Guaranteed structure output with Ollama and Pydantic.
@pydantic @ollama I also just learned @ollama is @UWaterloo ece?!
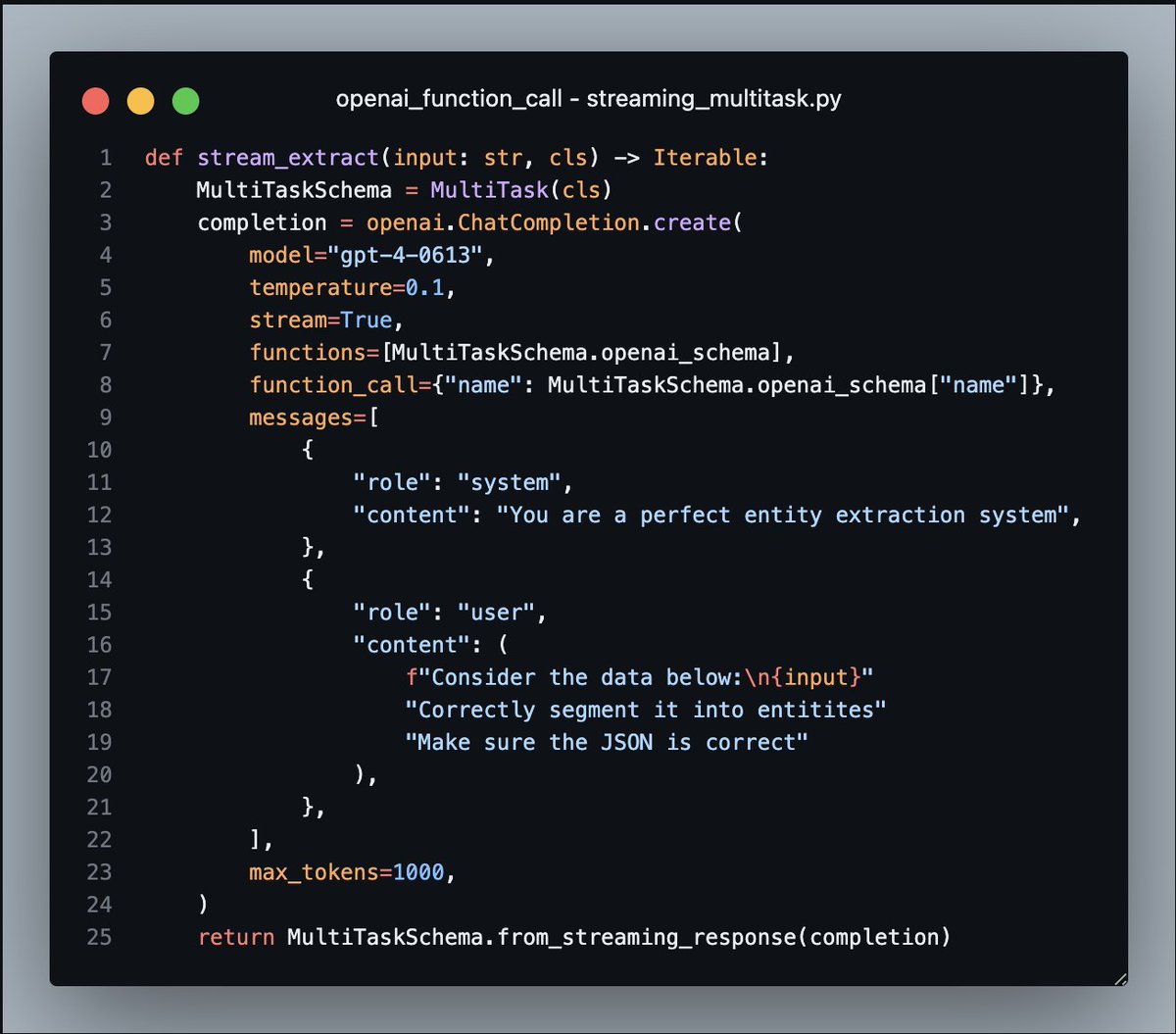
instructor also supports partial streaming of json so:
1. don't wait for the full payload
2. no stress about json.loads
what do you think @ollama
1. don't wait for the full payload
2. no stress about json.loads
what do you think @ollama
• • •
Missing some Tweet in this thread? You can try to
force a refresh