
Gemini 1.5 Pro - A highly capable multimodal model with a 10M token context length
Today we are releasing the first demonstrations of the capabilities of the Gemini 1.5 series, with the Gemini 1.5 Pro model. One of the key differentiators of this model is its incredibly long context capabilities, supporting millions of tokens of multimodal input. The multimodal capabilities of the model means you can interact in sophisticated ways with entire books, very long document collections, codebases of hundreds of thousands of lines across hundreds of files, full movies, entire podcast series, and more.
Gemini 1.5 was built by an amazing team of people from @GoogleDeepMind, @GoogleResearch, and elsewhere at @Google. @OriolVinyals (my co-technical lead for the project) and I are incredibly proud of the whole team, and we’re so excited to be sharing this work and what long context and in-context learning can mean for you today!
There’s lots of material about this, some of which are linked to below.
Main blog post:
Technical report:
“Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context”
Videos of interactions with the model that highlight its long context abilities:
Understanding the three.js codebase:
Analyzing a 45 minute Buster Keaton movie:
Apollo 11 transcript interaction:
Starting today, we’re offering a limited preview of 1.5 Pro to developers and enterprise customers via AI Studio and Vertex AI. Read more about this on these blogs:
Google for Developers blog:
Google Cloud blog:
We’ll also introduce 1.5 Pro with a standard 128,000 token context window when the model is ready for a wider release. Coming soon, we plan to introduce pricing tiers that start at the standard 128,000 context window and scale up to 1 million tokens, as we improve the model.
Early testers can try the 1 million token context window at no cost during the testing period. We’re excited to see what developer’s creativity unlocks with a very long context window.
Let me walk you through the capabilities of the model and what I’m excited about!blog.google/technology/ai/…
goo.gle/GeminiV1-5
developers.googleblog.com/2024/02/gemini…
cloud.google.com/blog/products/…
Today we are releasing the first demonstrations of the capabilities of the Gemini 1.5 series, with the Gemini 1.5 Pro model. One of the key differentiators of this model is its incredibly long context capabilities, supporting millions of tokens of multimodal input. The multimodal capabilities of the model means you can interact in sophisticated ways with entire books, very long document collections, codebases of hundreds of thousands of lines across hundreds of files, full movies, entire podcast series, and more.
Gemini 1.5 was built by an amazing team of people from @GoogleDeepMind, @GoogleResearch, and elsewhere at @Google. @OriolVinyals (my co-technical lead for the project) and I are incredibly proud of the whole team, and we’re so excited to be sharing this work and what long context and in-context learning can mean for you today!
There’s lots of material about this, some of which are linked to below.
Main blog post:
Technical report:
“Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context”
Videos of interactions with the model that highlight its long context abilities:
Understanding the three.js codebase:
Analyzing a 45 minute Buster Keaton movie:
Apollo 11 transcript interaction:
Starting today, we’re offering a limited preview of 1.5 Pro to developers and enterprise customers via AI Studio and Vertex AI. Read more about this on these blogs:
Google for Developers blog:
Google Cloud blog:
We’ll also introduce 1.5 Pro with a standard 128,000 token context window when the model is ready for a wider release. Coming soon, we plan to introduce pricing tiers that start at the standard 128,000 context window and scale up to 1 million tokens, as we improve the model.
Early testers can try the 1 million token context window at no cost during the testing period. We’re excited to see what developer’s creativity unlocks with a very long context window.
Let me walk you through the capabilities of the model and what I’m excited about!blog.google/technology/ai/…
goo.gle/GeminiV1-5
developers.googleblog.com/2024/02/gemini…
cloud.google.com/blog/products/…

Needle in a Haystack Tests Out to 10M Tokens
First, let’s take a quick glance at a needle-in-a-haystack test across many different modalities to exercise Gemini 1.5 Pro’s ability to retrieve information from its very long context. In these tests, green is good, and red is not good, and these are almost entirely green (>99.7% recall), even out to 10M tokens. Great! A bit more on needle-in-a-haystack tests later in the thread.
First, let’s take a quick glance at a needle-in-a-haystack test across many different modalities to exercise Gemini 1.5 Pro’s ability to retrieve information from its very long context. In these tests, green is good, and red is not good, and these are almost entirely green (>99.7% recall), even out to 10M tokens. Great! A bit more on needle-in-a-haystack tests later in the thread.

Analyzing and understanding complex code bases
The model’s ability to quickly ingest large code bases and answer complex questions is pretty remarkable. three.js is a 3D Javascript library of about 100,000 lines of code, examples, documentation, etc. ()
With this codebase in context, the system can help the user understand the code, and can make modifications to complex demonstrations based on high-level human specifications (“show me some code to add a slider to control the speed of the animation. use that kind of GUI the other demos have”), or pinpoint the exact part of the codebase to change the height of some generated terrain in a different demo.
Watch this video!
threejs.org
The model’s ability to quickly ingest large code bases and answer complex questions is pretty remarkable. three.js is a 3D Javascript library of about 100,000 lines of code, examples, documentation, etc. ()
With this codebase in context, the system can help the user understand the code, and can make modifications to complex demonstrations based on high-level human specifications (“show me some code to add a slider to control the speed of the animation. use that kind of GUI the other demos have”), or pinpoint the exact part of the codebase to change the height of some generated terrain in a different demo.
Watch this video!
threejs.org
Navigating large and unfamiliar code bases
As another code-related example, imagine you’re unfamiliar with a large codebase and want the model to help you understand the code or find where particular functionality is implemented. In this example the model is able to ingest the entire 116 file JAX code base (746k tokens) and help the user identify the specific spot in the code that implements the backwards pass for autodifferentiation.
It’s easy to see how the long context capabilities can be invaluable when diving in to an unfamiliar code base or working with one that you use every day. Many Gemini team members have been finding it very useful to use Gemini 1.5 Pro’s long context capabilities on our Gemini code base.
As another code-related example, imagine you’re unfamiliar with a large codebase and want the model to help you understand the code or find where particular functionality is implemented. In this example the model is able to ingest the entire 116 file JAX code base (746k tokens) and help the user identify the specific spot in the code that implements the backwards pass for autodifferentiation.
It’s easy to see how the long context capabilities can be invaluable when diving in to an unfamiliar code base or working with one that you use every day. Many Gemini team members have been finding it very useful to use Gemini 1.5 Pro’s long context capabilities on our Gemini code base.

Analyzing and reasoning about videos
Analyzing videos is another great capability brought by the fact that Gemini models are naturally multimodal, and this becomes even more compelling with long contexts. Consider Gemini 1.5 Pro’s ability to analyze movies, like Buster Keaton’s silent 45 minute “Sherlock Jr.” movie. Using one frame per second, we turn this into an input context of 684k tokens. The model can then answer fairly complex questions about the video content, such as:
“Tell me some key information from the piece of paper that is removed from the person’s pocket, and the timecode of that moment.”
Or, a very cursory line drawing of something that happened, combined with “What is the timecode when this happens?”
You can see this interaction here:
Analyzing videos is another great capability brought by the fact that Gemini models are naturally multimodal, and this becomes even more compelling with long contexts. Consider Gemini 1.5 Pro’s ability to analyze movies, like Buster Keaton’s silent 45 minute “Sherlock Jr.” movie. Using one frame per second, we turn this into an input context of 684k tokens. The model can then answer fairly complex questions about the video content, such as:
“Tell me some key information from the piece of paper that is removed from the person’s pocket, and the timecode of that moment.”
Or, a very cursory line drawing of something that happened, combined with “What is the timecode when this happens?”
You can see this interaction here:



Reasoning about long text documents
The model also shines at analyzing long, complex text documents, like Victor Hugo’s five volume novel “Les Misérables” (1382 pages, 732k tokens). The multimodal capabilities are demonstrated by coarsely sketching a scene and saying “Look at the event in this drawing. What page is this on?”
The model also shines at analyzing long, complex text documents, like Victor Hugo’s five volume novel “Les Misérables” (1382 pages, 732k tokens). The multimodal capabilities are demonstrated by coarsely sketching a scene and saying “Look at the event in this drawing. What page is this on?”


Reasoning about long text documents (cont)
Gemini 1.5 Pro can analyze and summarize the 402-page transcripts from Apollo 11’s mission to the moon.
“One small step for man, one giant leap for mankind.”
Gemini 1.5 Pro can analyze and summarize the 402-page transcripts from Apollo 11’s mission to the moon.
“One small step for man, one giant leap for mankind.”
Kalamang Translation
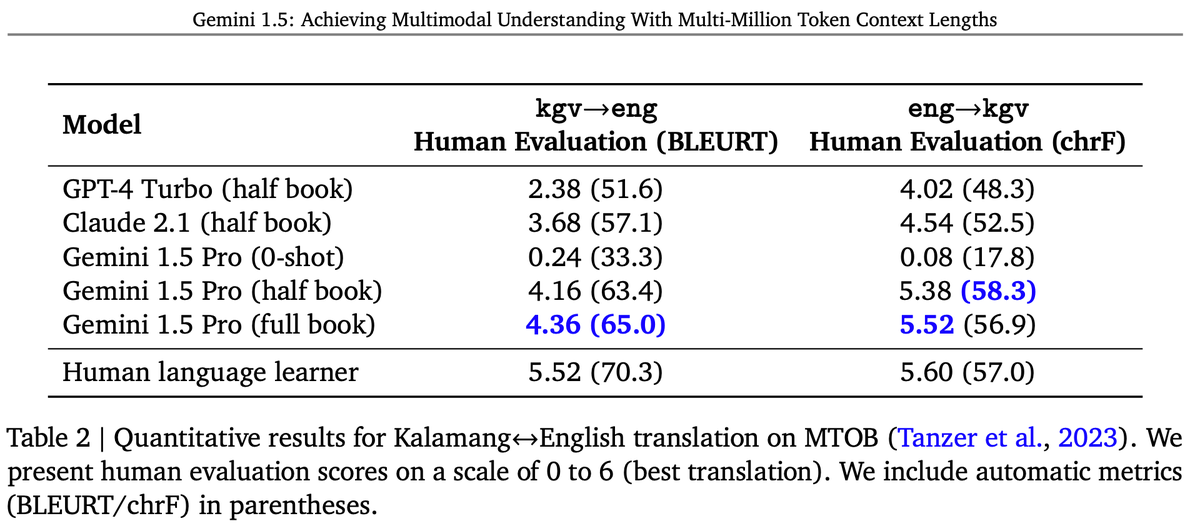
One of the most exciting examples in the report involves translation of Kalamang. Kalamang is a language spoken by fewer than 200 speakers in western New Guinea in the east of Indonesian Papua (). Kalamang has almost no online presence. Machine Translation from One Book (MTOB: ) is a recently introduced benchmark evaluating the ability of a learning system to learn to translate Kalamang from just a single book.
Eline Visser () wrote a 573 page book “A Grammar of Kalamang” ().
Thank you, Eline! The text of this book is used in the MTOB benchmark. With this book and a simple bilingual wordlist (dictionary) provided in context, Gemini 1.5 Pro can learn to translate from English to/from Kalamang. Without the Kalamang materials in context, the 1.5 Pro model produces almost random translations. However, with the materials in the context window, Gemini Pro 1.5 is able to use in-context learning about Kalamang, and we find that the quality of its translations is comparable to that of a person who has learned from the same materials. With a ChrF of 58.3 for English->Kalamang translation, Gemini Pro 1.5 improves substantially over the best model score of 45.8 ChrF and also slightly exceeds the human baseline of 57.0 ChrF reported in the MTOB paper ().
The possibilities for significantly improving translation for very low resource languages are quite exciting!endangeredlanguages.com/lang/1891
arxiv.org/abs/2309.16575
elinevisser23.github.io
github.com/langsci/344/bl…
arxiv.org/abs/2309.16575
One of the most exciting examples in the report involves translation of Kalamang. Kalamang is a language spoken by fewer than 200 speakers in western New Guinea in the east of Indonesian Papua (). Kalamang has almost no online presence. Machine Translation from One Book (MTOB: ) is a recently introduced benchmark evaluating the ability of a learning system to learn to translate Kalamang from just a single book.
Eline Visser () wrote a 573 page book “A Grammar of Kalamang” ().
Thank you, Eline! The text of this book is used in the MTOB benchmark. With this book and a simple bilingual wordlist (dictionary) provided in context, Gemini 1.5 Pro can learn to translate from English to/from Kalamang. Without the Kalamang materials in context, the 1.5 Pro model produces almost random translations. However, with the materials in the context window, Gemini Pro 1.5 is able to use in-context learning about Kalamang, and we find that the quality of its translations is comparable to that of a person who has learned from the same materials. With a ChrF of 58.3 for English->Kalamang translation, Gemini Pro 1.5 improves substantially over the best model score of 45.8 ChrF and also slightly exceeds the human baseline of 57.0 ChrF reported in the MTOB paper ().
The possibilities for significantly improving translation for very low resource languages are quite exciting!endangeredlanguages.com/lang/1891
arxiv.org/abs/2309.16575
elinevisser23.github.io
github.com/langsci/344/bl…
arxiv.org/abs/2309.16575

Needle in a Haystack tests
The tech report also details a number of microbenchmark “needle in a haystack” tests (modeled after @GregKamradt’s ) that probe the model’s ability to retrieve specific information from its context.
For text, Gemini 1.5 Pro achieves 100% recall up to 530k tokens, 99.7% up to 1M tokens, and 99.2% accuracy up to 10M tokens.github.com/gkamradt/LLMTe…
The tech report also details a number of microbenchmark “needle in a haystack” tests (modeled after @GregKamradt’s ) that probe the model’s ability to retrieve specific information from its context.
For text, Gemini 1.5 Pro achieves 100% recall up to 530k tokens, 99.7% up to 1M tokens, and 99.2% accuracy up to 10M tokens.github.com/gkamradt/LLMTe…

Audio haystack
For audio, Gemini 1.5 Pro achieves 100% recall when looking for different audio needles hidden in ~11 hours of audio.
For audio, Gemini 1.5 Pro achieves 100% recall when looking for different audio needles hidden in ~11 hours of audio.

Video haystack
For video, Gemini 1.5 Pro achieves 100% recall when looking for different visual needles hidden in ~3 hours of video.
For video, Gemini 1.5 Pro achieves 100% recall when looking for different visual needles hidden in ~3 hours of video.

Multineedle in haystack test
We also created a generalized version of the needle in a haystack test, where the model must retrieve 100 different needles hidden in the context window. For this, we see that Gemini 1.5 Pro’s performance is above that of GPT-4 Turbo at small context lengths and remains relatively steady across the entire 1M context window, while the GPT-4 Turbo model drops off more quickly (and cannot go past 128k tokens).
We also created a generalized version of the needle in a haystack test, where the model must retrieve 100 different needles hidden in the context window. For this, we see that Gemini 1.5 Pro’s performance is above that of GPT-4 Turbo at small context lengths and remains relatively steady across the entire 1M context window, while the GPT-4 Turbo model drops off more quickly (and cannot go past 128k tokens).

Basic Capabilities
We’ve been able to add the long context ability without sacrificing on other capabilities. Although it required a small fraction of the training time of the Gemini 1.0 Ultra model, the 1.5 Pro model exceeds the performance of the 1.0 Ultra model on 17 of 31 benchmarks. Compared to the 1.0 Pro model, the 1.5 Pro model exceeds its performance on 27 of 31 benchmarks.
Tables 8 and 10 in the tech report have lots more details.
We’ve been able to add the long context ability without sacrificing on other capabilities. Although it required a small fraction of the training time of the Gemini 1.0 Ultra model, the 1.5 Pro model exceeds the performance of the 1.0 Ultra model on 17 of 31 benchmarks. Compared to the 1.0 Pro model, the 1.5 Pro model exceeds its performance on 27 of 31 benchmarks.
Tables 8 and 10 in the tech report have lots more details.


Mixture of Experts
Gemini 1.5 Pro uses a mixture-of-expert (MoE) architecture, building on a long line of Google research efforts on sparse models:
2017: Shazeer et al.. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. ICLR 2017.
2020: Lepikhin et al., GShard: Scaling giant models with conditional computation and automatic sharding. ICLR 2020.
2021: Carlos Riquelme et al., Scaling vision with sparse mixture of experts, NeurIPS 2021.
2021: Fedus et al., Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity. JMLR 2022.
Clark et al., Unified scaling laws for routed language models, ICML 2022.
2022: Zoph et al., Designing effective sparse expert models. arxiv.org/abs/1701.06538
arxiv.org/abs/2006.16668
arxiv.org/abs/2106.05974
arxiv.org/abs/2101.03961
arxiv.org/abs/2202.01169
arxiv.org/abs/2202.08906
Gemini 1.5 Pro uses a mixture-of-expert (MoE) architecture, building on a long line of Google research efforts on sparse models:
2017: Shazeer et al.. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. ICLR 2017.
2020: Lepikhin et al., GShard: Scaling giant models with conditional computation and automatic sharding. ICLR 2020.
2021: Carlos Riquelme et al., Scaling vision with sparse mixture of experts, NeurIPS 2021.
2021: Fedus et al., Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity. JMLR 2022.
Clark et al., Unified scaling laws for routed language models, ICML 2022.
2022: Zoph et al., Designing effective sparse expert models. arxiv.org/abs/1701.06538
arxiv.org/abs/2006.16668
arxiv.org/abs/2106.05974
arxiv.org/abs/2101.03961
arxiv.org/abs/2202.01169
arxiv.org/abs/2202.08906
Gratitude
It’s really great to get to work with such an awesome set of colleagues on a project like Gemini.
@OriolVinyalsML and I just want to say a heartfelt thank you to everyone on the team for the hard work on Gemini so far, and I’m so proud of what we’ve built together! 🙏
It’s really great to get to work with such an awesome set of colleagues on a project like Gemini.
@OriolVinyalsML and I just want to say a heartfelt thank you to everyone on the team for the hard work on Gemini so far, and I’m so proud of what we’ve built together! 🙏
Seeing farther
Sometimes when you're looking at something, you're a bit too close to it to see important aspects.
The long context work enables us to all see a bit further.
Sometimes when you're looking at something, you're a bit too close to it to see important aspects.
The long context work enables us to all see a bit further.


We are very excited to be able to share our work on this next iteration of Gemini. We can’t wait to see how people creatively use the long context capabilities to do all kinds of things that previously were not possible. How would you use these capabilities?
And now, back to some other things we’re ultra excited about!
And now, back to some other things we’re ultra excited about!
• • •
Missing some Tweet in this thread? You can try to
force a refresh









