Here's my take on the Sora technical report, with a good dose of speculation that could be totally off. First of all, really appreciate the team for sharing helpful insights and design decisions – Sora is incredible and is set to transform the video generation community.
What we have learned so far:
- Architecture: Sora is built on our diffusion transformer (DiT) model (published in ICCV 2023) — it's a diffusion model with a transformer backbone, in short:
DiT = [VAE encoder + ViT + DDPM + VAE decoder].
According to the report, it seems there are not much additional bells and whistles.
- "Video compressor network": Looks like it's just a VAE but trained on raw video data. Tokenization probably plays a significant role in getting good temporal consistency. By the way, VAE is a ConvNet, so DiT technically is a hybrid model ;) (1/n)
What we have learned so far:
- Architecture: Sora is built on our diffusion transformer (DiT) model (published in ICCV 2023) — it's a diffusion model with a transformer backbone, in short:
DiT = [VAE encoder + ViT + DDPM + VAE decoder].
According to the report, it seems there are not much additional bells and whistles.
- "Video compressor network": Looks like it's just a VAE but trained on raw video data. Tokenization probably plays a significant role in getting good temporal consistency. By the way, VAE is a ConvNet, so DiT technically is a hybrid model ;) (1/n)
When Bill and I were working on the DiT project, instead of creating novelty (see my last tweet🤷♂️), we prioritized two aspects: simplicity and scalability. These priorities offer more than just conceptual advantages.
- Simplicity means flexibility. The cool thing about vanilla ViT that people often miss is how it makes your model way more flexible when it comes to working with input data. For example, in masked autoencoder (MAE), ViT helped us to just process the visible patches and ignore the masked ones. And similarly, Sora "can control the size of generated videos by arranging randomly-initialized patches in an appropriately-sized grid." UNet does not directly offer this flexibility.
👀Speculation: Sora might also use Patch n’ Pack (NaViT) from Google, to make DiT adaptable to variable resolutions/durations/aspect ratios.
- Scalability is the core theme of the DiT paper. First, an optimized DiT runs much faster than UNet in terms of wall-clock time per Flop. More importantly, Sora demonstrated that the DiT scaling law applies not just to images but now to videos as well -- Sora replicates the visual scaling behavior observed in DiT.
👀Speculation: In the Sora report, the quality for the first video is quite bad, I suspect it is using a base model size. A back-of-the-envelope calculation: DiT XL/2 is 5X GFLOPs of the B/2 model, so the final 16X compute model is probably 3X DiT-XL model size, which means Sora might have ~3B parameters – if true, this is not an unreasonable model size . It could suggest that training the Sora model might not require as many GPUs as one would anticipate – I would expect very fast iterations going forward. (2/n)
- Simplicity means flexibility. The cool thing about vanilla ViT that people often miss is how it makes your model way more flexible when it comes to working with input data. For example, in masked autoencoder (MAE), ViT helped us to just process the visible patches and ignore the masked ones. And similarly, Sora "can control the size of generated videos by arranging randomly-initialized patches in an appropriately-sized grid." UNet does not directly offer this flexibility.
👀Speculation: Sora might also use Patch n’ Pack (NaViT) from Google, to make DiT adaptable to variable resolutions/durations/aspect ratios.
- Scalability is the core theme of the DiT paper. First, an optimized DiT runs much faster than UNet in terms of wall-clock time per Flop. More importantly, Sora demonstrated that the DiT scaling law applies not just to images but now to videos as well -- Sora replicates the visual scaling behavior observed in DiT.
👀Speculation: In the Sora report, the quality for the first video is quite bad, I suspect it is using a base model size. A back-of-the-envelope calculation: DiT XL/2 is 5X GFLOPs of the B/2 model, so the final 16X compute model is probably 3X DiT-XL model size, which means Sora might have ~3B parameters – if true, this is not an unreasonable model size . It could suggest that training the Sora model might not require as many GPUs as one would anticipate – I would expect very fast iterations going forward. (2/n)


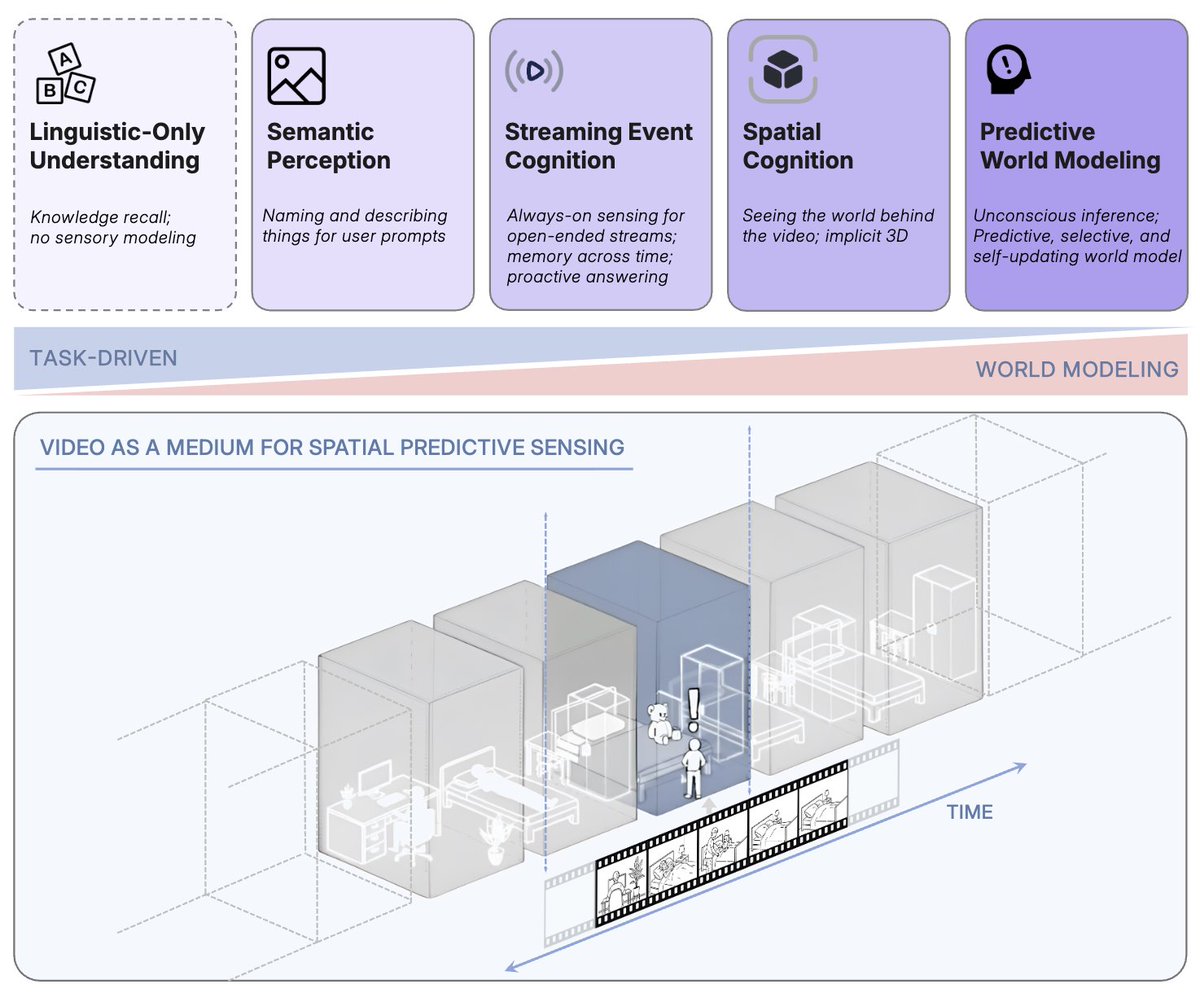
The key takeaway is from the "Emerging simulation capabilities" section. Before Sora, it was unclear if long form consistency could emerge on its own or if it required complex subject-driven generation pipelines or even physics simulators. OpenAI has shown that, though not perfect, these behaviors can be achieved with end-to-end training. Yet, two essential points have not been discussed.
1. Training Data: No talk about training source and construction at all, which might just imply data is likely the most critical factor for Sora's success.
👀Speculations: There's already much speculation about data from game engines. I also anticipate the inclusion of movies, documentaries, cinematic long takes, etc. Quality really matters. Super curious where Sora got this data from (surely not YouTube, right?).
2. (Auto-regressive) Long Video Generation: a significant breakthrough in Sora is the ability to generate very long videos. The difference between producing a 2-second video and a 1-minute video is monumental.
In Sora, this is probably achieved through joint frame prediction that allows auto-regressive sampling, yet a major challenge is how to address error accumulation and maintain quality/consistency through time. A very long (and bi-directional) context for conditioning? Or could scaling up simply lessen the issue? These technical details can be super important and hopefully will be demystified in the future (3/n)
1. Training Data: No talk about training source and construction at all, which might just imply data is likely the most critical factor for Sora's success.
👀Speculations: There's already much speculation about data from game engines. I also anticipate the inclusion of movies, documentaries, cinematic long takes, etc. Quality really matters. Super curious where Sora got this data from (surely not YouTube, right?).
2. (Auto-regressive) Long Video Generation: a significant breakthrough in Sora is the ability to generate very long videos. The difference between producing a 2-second video and a 1-minute video is monumental.
In Sora, this is probably achieved through joint frame prediction that allows auto-regressive sampling, yet a major challenge is how to address error accumulation and maintain quality/consistency through time. A very long (and bi-directional) context for conditioning? Or could scaling up simply lessen the issue? These technical details can be super important and hopefully will be demystified in the future (3/n)
https://x.com/gabor/status/1758295719788822866?s=20
#shamelessplug DiT shines in Sora. Our team at NYU has recently released a new DiT model, called SiT. It has exactly the same architecture, but offers enhanced performance and faster convergence. Super curious about its performance on video generation too! (n/n)
https://x.com/ma_nanye/status/1748199729438113993?s=20
• • •
Missing some Tweet in this thread? You can try to
force a refresh