
cofounder & chief science officer at @amilabs | faculty @nyu_courant | prev: @googledeepmind @meta (fair) @ucsandiego | ynwa
 diffusion transformers have come a long way, but most still lean on the old 2021 sd-vae for their latent space.
diffusion transformers have come a long way, but most still lean on the old 2021 sd-vae for their latent space.

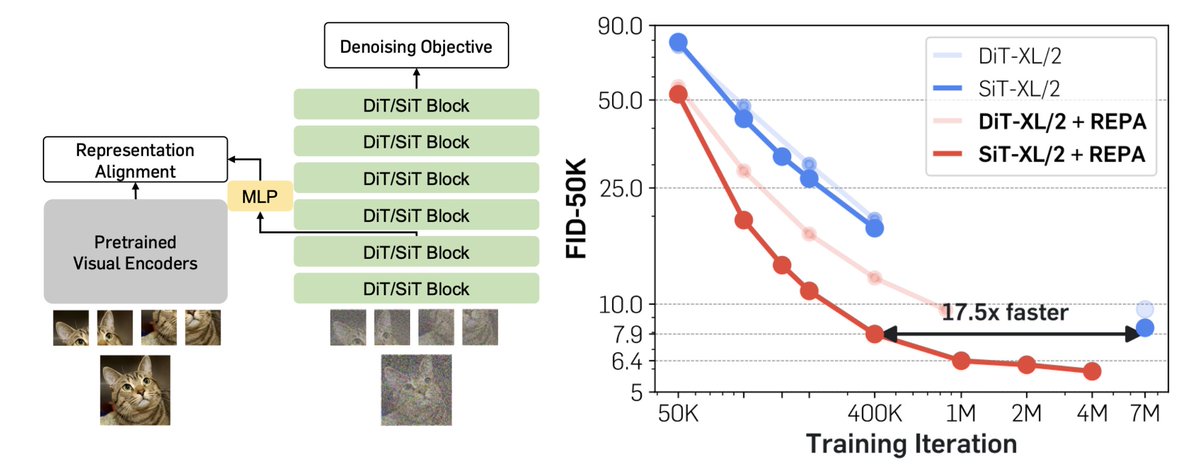 People (in academia) always tell me that training DiTs/SiTs is way too hard because it takes 7M iters and weeks to get the FID we reported in the paper. We figured out how to speed up training by ~18X, hitting even better FID in less than 400K iters. We did this by digging into the representation learned from diffusion models (2/n).
People (in academia) always tell me that training DiTs/SiTs is way too hard because it takes 7M iters and weeks to get the FID we reported in the paper. We figured out how to speed up training by ~18X, hitting even better FID in less than 400K iters. We did this by digging into the representation learned from diffusion models (2/n).
 From our previous projects (MMVP, V*, VIRL), we've noticed unexpected visual shortcomings in current MLLM systems. While we can temporarily fix issues by e.g. adding data, one root problem is that our visual representations are not yet sufficient for language understanding.
From our previous projects (MMVP, V*, VIRL), we've noticed unexpected visual shortcomings in current MLLM systems. While we can temporarily fix issues by e.g. adding data, one root problem is that our visual representations are not yet sufficient for language understanding.
 When Bill and I were working on the DiT project, instead of creating novelty (see my last tweet🤷♂️), we prioritized two aspects: simplicity and scalability. These priorities offer more than just conceptual advantages.
When Bill and I were working on the DiT project, instead of creating novelty (see my last tweet🤷♂️), we prioritized two aspects: simplicity and scalability. These priorities offer more than just conceptual advantages. 

 Why does this matter? Consider everyday situations like locating keys on a cluttered table or spotting a friend in a crowd: we engage our system II and actively *search* for the necessary visual info -- we do not have an 'internal CLIP' that shows us everything all at once. (2/n)
Why does this matter? Consider everyday situations like locating keys on a cluttered table or spotting a friend in a crowd: we engage our system II and actively *search* for the necessary visual info -- we do not have an 'internal CLIP' that shows us everything all at once. (2/n)