I've spent the past ~2 weeks trying to make a chip from scratch with no prior experience. It's been an incredible source of learning so far.
Progress tracker in thread (coolest stuff at the end)👇
Progress tracker in thread (coolest stuff at the end)👇

Step 1 ✅: Learning the fundamentals of chip architecture
I started by learning how a chip works all the way from binary to C.
This part was critical.
In order to design a chip, you need a strong understanding of all the architecture fundamentals as you constantly work with logic, gates, memory, etc.
I reviewed the entire stack:
> Binary - using voltage to encode data
> Transistors - using semi-conductors to create a digital switch
> CMOS - using transistors to build the first energy efficient inverter
> Gates - using transistors to compute higher level boolean logic
> Combinatorial Logic - using gates to build boolean logic circuits
> Sequential Logic - using combinatorial logic to persist data
> Memory - using sequential logic to create storage systems for data
> CPU - combining memory & combinatorial logic to create the Von Neumann architecture, the first Turing Complete step (ignoring memory constraints)
> Machine Language - how instructions in program memory map to control signals across the CPU
> Assembly - how assembly maps directly to the CPU
> C - how C compiles down into assembly and then machine language
Coming from a software background, fully understanding the connection between each of these layers in depth unlocked so many intuitions for me.
Planning to write a post about the full stack of compute soon (including all these layers + the relevant layers of chip fabrication & design)
I started by learning how a chip works all the way from binary to C.
This part was critical.
In order to design a chip, you need a strong understanding of all the architecture fundamentals as you constantly work with logic, gates, memory, etc.
I reviewed the entire stack:
> Binary - using voltage to encode data
> Transistors - using semi-conductors to create a digital switch
> CMOS - using transistors to build the first energy efficient inverter
> Gates - using transistors to compute higher level boolean logic
> Combinatorial Logic - using gates to build boolean logic circuits
> Sequential Logic - using combinatorial logic to persist data
> Memory - using sequential logic to create storage systems for data
> CPU - combining memory & combinatorial logic to create the Von Neumann architecture, the first Turing Complete step (ignoring memory constraints)
> Machine Language - how instructions in program memory map to control signals across the CPU
> Assembly - how assembly maps directly to the CPU
> C - how C compiles down into assembly and then machine language
Coming from a software background, fully understanding the connection between each of these layers in depth unlocked so many intuitions for me.
Planning to write a post about the full stack of compute soon (including all these layers + the relevant layers of chip fabrication & design)

Step 2 ✅: Learning the fundamentals of chip fabrication
Next, I learned about how transistors are actually fabricated.
Chip design tools are all built around specific fabrication processes (called process nodes), so I needed to understand this to fully grasp the chip design flow.
I focused on learning about:
> Materials - There are a huge number of materials required for semiconductor fabrication, including semi-conductors, etchants, solvents, etc. each with specific qualities that merit their use.
> Wafer Preparation - Creating silicon wafers with poly-silicon crystals and "growing" Silicon Dioxide layers on them
> Patterning - The 10 step process using layering (oxidation/layer deposition/metallization), photo-lithography, and etching to create the actual transistor patterns on the chip
> Packaging - Packaging the chips in protective covers to prevent corruption, create I/O interfaces, help w/ heat dissipation, etc.
> Contamination - Was interesting learning about how big of a focus contamination control is/how critical it becomes as transistor sizes decrease
Within each of these topics, there's so much depth to go into - each part of the process has many different approaches, each using different materials & machines.
I focused more on getting a broad understanding of the important parts of the process.
The most important intuition here is that chips are produced by defining the layout of different layers.
The design of these layers is what you produce as the output of the chip design (EDA) process.
Next, I learned about how transistors are actually fabricated.
Chip design tools are all built around specific fabrication processes (called process nodes), so I needed to understand this to fully grasp the chip design flow.
I focused on learning about:
> Materials - There are a huge number of materials required for semiconductor fabrication, including semi-conductors, etchants, solvents, etc. each with specific qualities that merit their use.
> Wafer Preparation - Creating silicon wafers with poly-silicon crystals and "growing" Silicon Dioxide layers on them
> Patterning - The 10 step process using layering (oxidation/layer deposition/metallization), photo-lithography, and etching to create the actual transistor patterns on the chip
> Packaging - Packaging the chips in protective covers to prevent corruption, create I/O interfaces, help w/ heat dissipation, etc.
> Contamination - Was interesting learning about how big of a focus contamination control is/how critical it becomes as transistor sizes decrease
Within each of these topics, there's so much depth to go into - each part of the process has many different approaches, each using different materials & machines.
I focused more on getting a broad understanding of the important parts of the process.
The most important intuition here is that chips are produced by defining the layout of different layers.
The design of these layers is what you produce as the output of the chip design (EDA) process.

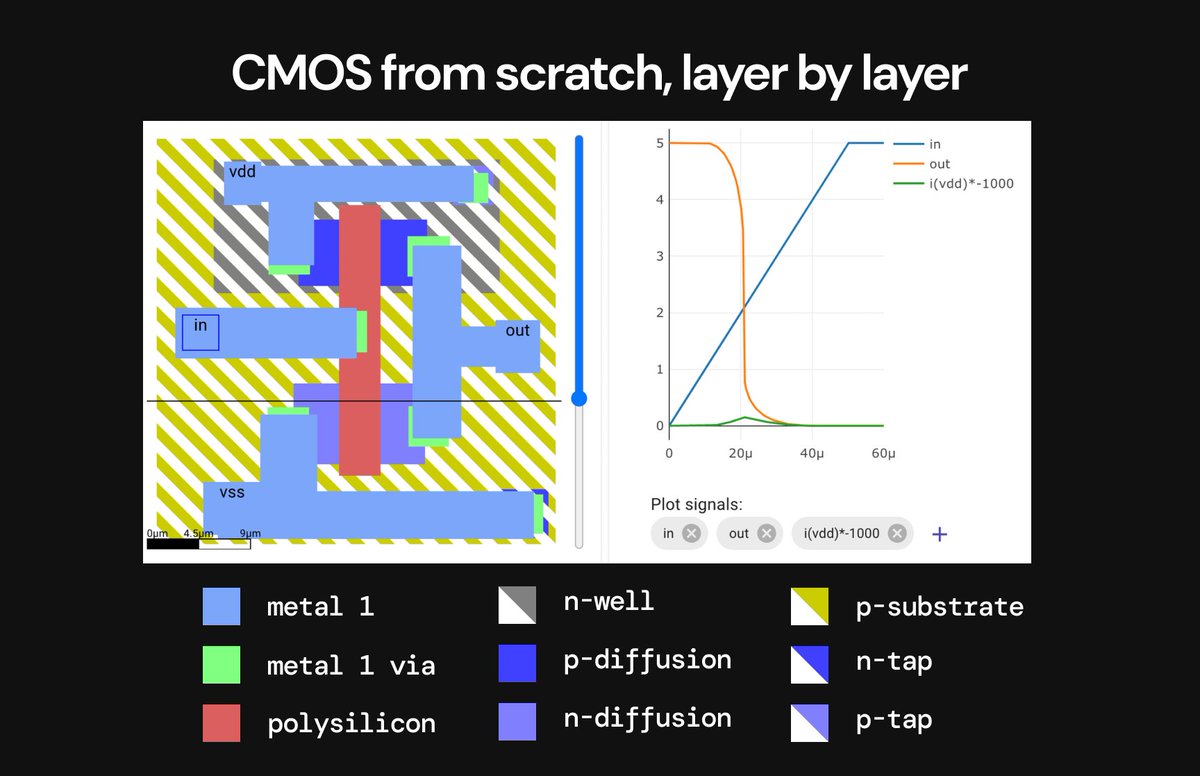
Step 3 ✅: Starting electronic design automation by making a CMOS transistor, layer-by-layer
The CMOS transistor is the fundamental structure that enabled digital computation to take off because of it's unique energy efficiency
Drawing each layer of the CMOS manually made the design of a transistor much more clear.
In computer architecture, the common explanation of transistors is actually heavily over-simplified - whereas designing the actual transistor layer-by-layer forced me to go more into the actual implementation details.
Looking at the voltage and current diagram (right) vs. the equivalent for an individual nMOS transistor also made the power efficiency gains of the CMOS much more obvious.
In the picture below, each different color specifies a different layer, each made with different materials/ions/etc. and created in a different step of the fabrication process - for example, the red poly-silicon layer is the actual GATE for the top nMOS and bottom pMOS transistor, and the light blue metal 1 layer are the actual connections to input & output.
The CMOS transistor is the fundamental structure that enabled digital computation to take off because of it's unique energy efficiency
Drawing each layer of the CMOS manually made the design of a transistor much more clear.
In computer architecture, the common explanation of transistors is actually heavily over-simplified - whereas designing the actual transistor layer-by-layer forced me to go more into the actual implementation details.
Looking at the voltage and current diagram (right) vs. the equivalent for an individual nMOS transistor also made the power efficiency gains of the CMOS much more obvious.
In the picture below, each different color specifies a different layer, each made with different materials/ions/etc. and created in a different step of the fabrication process - for example, the red poly-silicon layer is the actual GATE for the top nMOS and bottom pMOS transistor, and the light blue metal 1 layer are the actual connections to input & output.
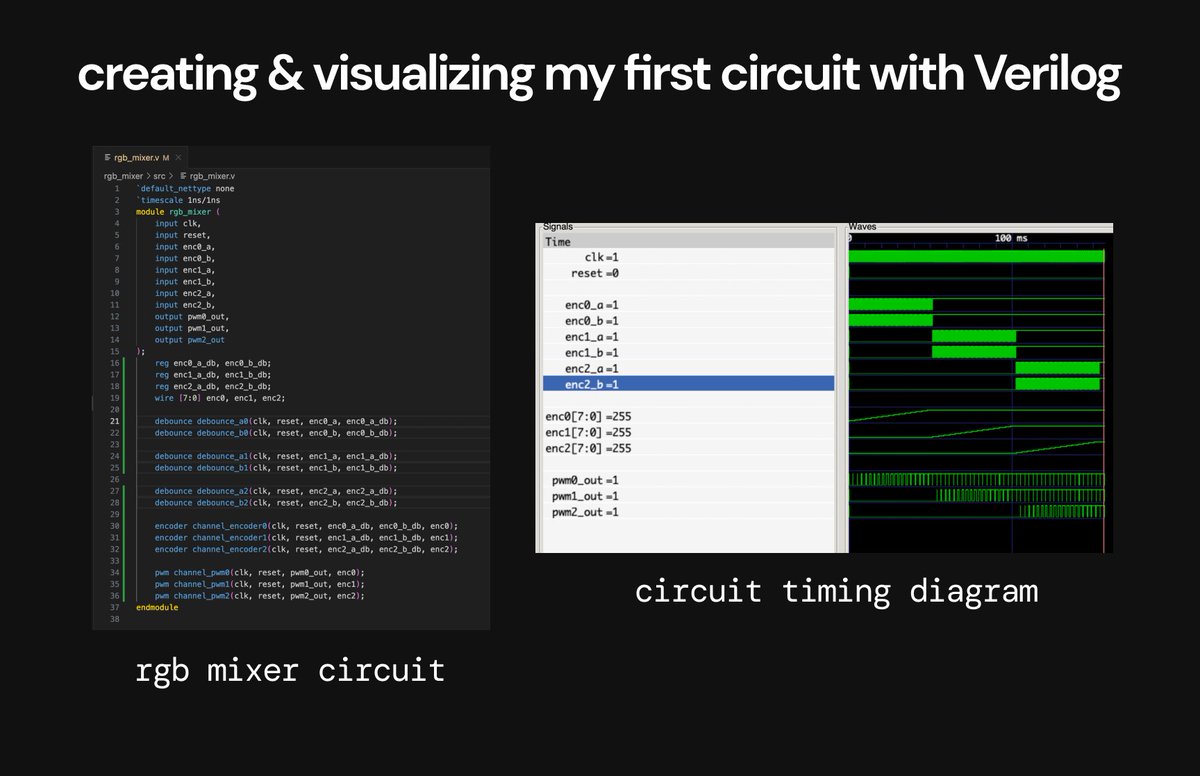
Step 4 ✅: Creating my first full circuit in Verilog
This part was a cool unlock for me - my first experience with programming hardware using software.
I made my first circuit with the hardware description language (HDL) Verilog.
I made an RGB mixer circuit that converts signal from 3 rotating dials to pulses for 3 LEDs.
You can use HDLs to specify individual gates, but thank fully most foundries ship libraries of standard cells for customers to use.
A standard cell is just an arrangement of transistors for a common use (like an AND gate) that's heavily optimized for efficiency and designed for a specific foundries fabrication process.
These standard cells libraries have almost all of the logic units you would actually need for most designs, so you don't need to dip too much into the gate level.
I created this circuit with the standard cell library for the Skywater 130nm process node (a specific fabrication process from a foundry called Skywater).
I know code is mostly useless to look at, but wanted to include it for anyone curious. The timing diagram shows 3 different knobs being turned and the corresponding LEDs being turned on.
This part was a cool unlock for me - my first experience with programming hardware using software.
I made my first circuit with the hardware description language (HDL) Verilog.
I made an RGB mixer circuit that converts signal from 3 rotating dials to pulses for 3 LEDs.
You can use HDLs to specify individual gates, but thank fully most foundries ship libraries of standard cells for customers to use.
A standard cell is just an arrangement of transistors for a common use (like an AND gate) that's heavily optimized for efficiency and designed for a specific foundries fabrication process.
These standard cells libraries have almost all of the logic units you would actually need for most designs, so you don't need to dip too much into the gate level.
I created this circuit with the standard cell library for the Skywater 130nm process node (a specific fabrication process from a foundry called Skywater).
I know code is mostly useless to look at, but wanted to include it for anyone curious. The timing diagram shows 3 different knobs being turned and the corresponding LEDs being turned on.
Step 5 ✅: Implementing simulation & formal verification for my circuit (disclaimer, this part might be boring, skip to the end if you want)
Since the cost of bugs in hardware is far higher than in software (since you can't change stuff once you're design is fabricated), using extensive testing and formal verification is a critical part of the design process.
Throughout the EDA flow, you use:
> Static-timing analysis - make sure there are no timing errors because of how signals propagate through your circuit
> Bounded model checking & k-induction - make sure that it's impossible for your design to get into certain invalid states
> You also want to make sure that it's possible for your circuit to get into specific valid states
I implemented all of these steps to formally verify that my RGB mixer circuit & other designs were valid (proper expected state transitions occur)
Since the cost of bugs in hardware is far higher than in software (since you can't change stuff once you're design is fabricated), using extensive testing and formal verification is a critical part of the design process.
Throughout the EDA flow, you use:
> Static-timing analysis - make sure there are no timing errors because of how signals propagate through your circuit
> Bounded model checking & k-induction - make sure that it's impossible for your design to get into certain invalid states
> You also want to make sure that it's possible for your circuit to get into specific valid states
I implemented all of these steps to formally verify that my RGB mixer circuit & other designs were valid (proper expected state transitions occur)

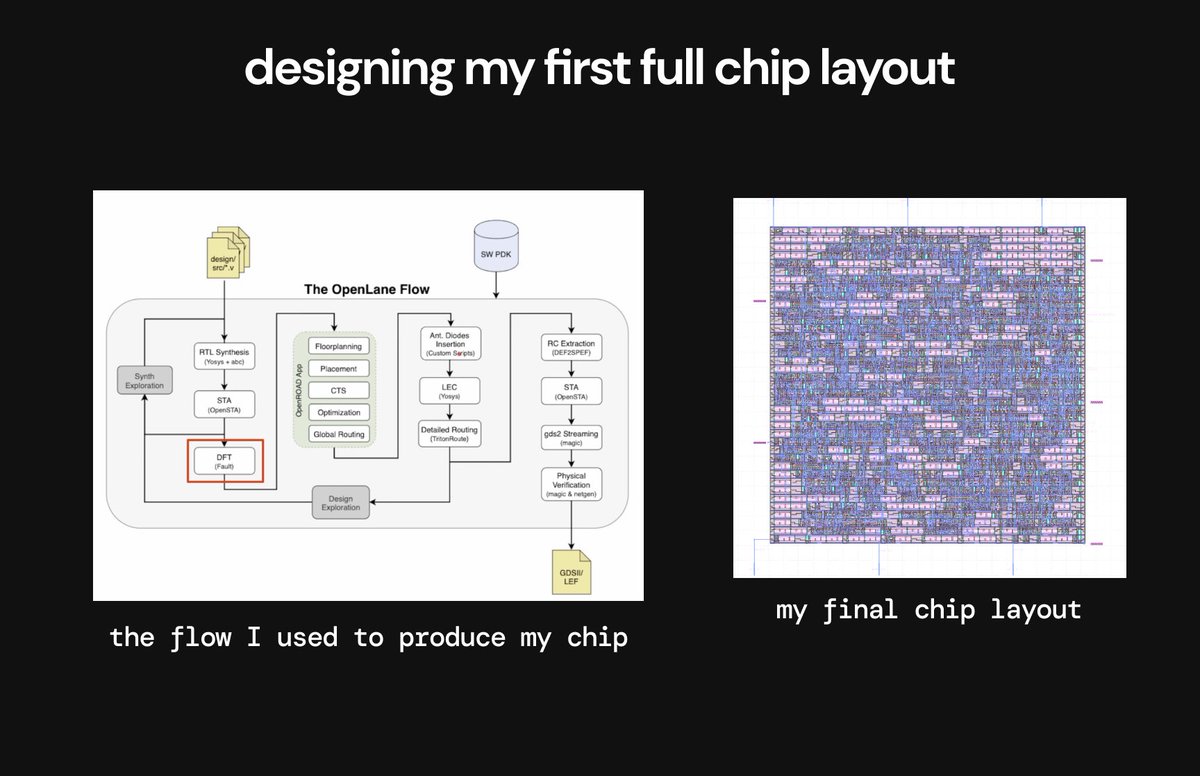
Step 6 ✅: Designing my first full chip layout
This was the coolest part of the process so far. I used OpenLane (an open-source EDA tool) to perform the entire synthesis, optimization, and layout process on my design and come up with a complete chip design.
Just seeing my Verilog code get turned into an actual chip layout and being able to go in and play with all of the layers and click into each gate was a sick unlock.
The OpenLane flow deals with all of the following:
> Simulation - running simulation to verify that your design passes all test cases
> Synthesis - convert HDL to a net-list that shows the connections between all the gates in your design
> Optimization - optimize area, performance, and power consumption of your design
> Layout - lays out all the standard cells on the physical chip
> Wiring - connects all the components together with proper wiring
> Verification - runs formal verification on your end design
> GDS - creates the final output files, called GDS2 files, which specify the exact layers to be sent to a foundry for tape-out
This was the coolest part of the process so far. I used OpenLane (an open-source EDA tool) to perform the entire synthesis, optimization, and layout process on my design and come up with a complete chip design.
Just seeing my Verilog code get turned into an actual chip layout and being able to go in and play with all of the layers and click into each gate was a sick unlock.
The OpenLane flow deals with all of the following:
> Simulation - running simulation to verify that your design passes all test cases
> Synthesis - convert HDL to a net-list that shows the connections between all the gates in your design
> Optimization - optimize area, performance, and power consumption of your design
> Layout - lays out all the standard cells on the physical chip
> Wiring - connects all the components together with proper wiring
> Verification - runs formal verification on your end design
> GDS - creates the final output files, called GDS2 files, which specify the exact layers to be sent to a foundry for tape-out
Here's me playing with my design in the EDA tool
> I can zoom in and look at the individual cells and transistors
> I can selectively hide different metal layers to get a sense of how everything is connected
> I can view energy density, component density, etc. on my design
> I can zoom in and look at the individual cells and transistors
> I can selectively hide different metal layers to get a sense of how everything is connected
> I can view energy density, component density, etc. on my design
Step 7 ✅: Reverse-engineering and designing a GPU from scratch
My initial goal for my project was to build a minimal GPU. I didn't realize how hard that was going to be.
My expectation was that building a GPU was going to be similar to building a CPU, where there are a ton of learning resources online to figure out how to do it.
I was wrong.
Because GPU companies are all trying to keep their secrets from each other, most of the GPU architecture data is all proprietary and closed source.
NVIDIA and AMD release high-level architecture overviews, but leave all the details of how their GPUs work at a low-level completely undocumented.
This makes things way more fun for me - I basically have a few high-level architecture docs + some attempts at making an open-source GPU design, and zero public learning resources about GPU architectures.
From this, I've been trying to reverse engineer the details of how a GPU architecture works (of course at a much simpler level) based on what I know they do + what has to be true.
Claude Opus has been a huge help here - I've been proposing my ideas for how each unit must work to Claude, and then somehow (through inference from what it knows, or training on proprietary data) it will guide me toward the right implementation approaches which I can then go and confirm with open-source repos - but if I search some of the things publicly, nothing shows up which is a testament to how well hidden the implementation details are.
So TL;DR - I'm still building a minimal GPU design. I'm also going to document how everything works & make a post about it so it's more clear for anyone else who gets curious.
Will be shipping this in the next few days, and will probably send a cut down version to be taped out on the Skywater 130nm process node.
Very excited for this project!
My initial goal for my project was to build a minimal GPU. I didn't realize how hard that was going to be.
My expectation was that building a GPU was going to be similar to building a CPU, where there are a ton of learning resources online to figure out how to do it.
I was wrong.
Because GPU companies are all trying to keep their secrets from each other, most of the GPU architecture data is all proprietary and closed source.
NVIDIA and AMD release high-level architecture overviews, but leave all the details of how their GPUs work at a low-level completely undocumented.
This makes things way more fun for me - I basically have a few high-level architecture docs + some attempts at making an open-source GPU design, and zero public learning resources about GPU architectures.
From this, I've been trying to reverse engineer the details of how a GPU architecture works (of course at a much simpler level) based on what I know they do + what has to be true.
Claude Opus has been a huge help here - I've been proposing my ideas for how each unit must work to Claude, and then somehow (through inference from what it knows, or training on proprietary data) it will guide me toward the right implementation approaches which I can then go and confirm with open-source repos - but if I search some of the things publicly, nothing shows up which is a testament to how well hidden the implementation details are.
So TL;DR - I'm still building a minimal GPU design. I'm also going to document how everything works & make a post about it so it's more clear for anyone else who gets curious.
Will be shipping this in the next few days, and will probably send a cut down version to be taped out on the Skywater 130nm process node.
Very excited for this project!

I posted my full learning plan earlier for anyone curious
https://x.com/MajmudarAdam/status/1773869330700361789
• • •
Missing some Tweet in this thread? You can try to
force a refresh