
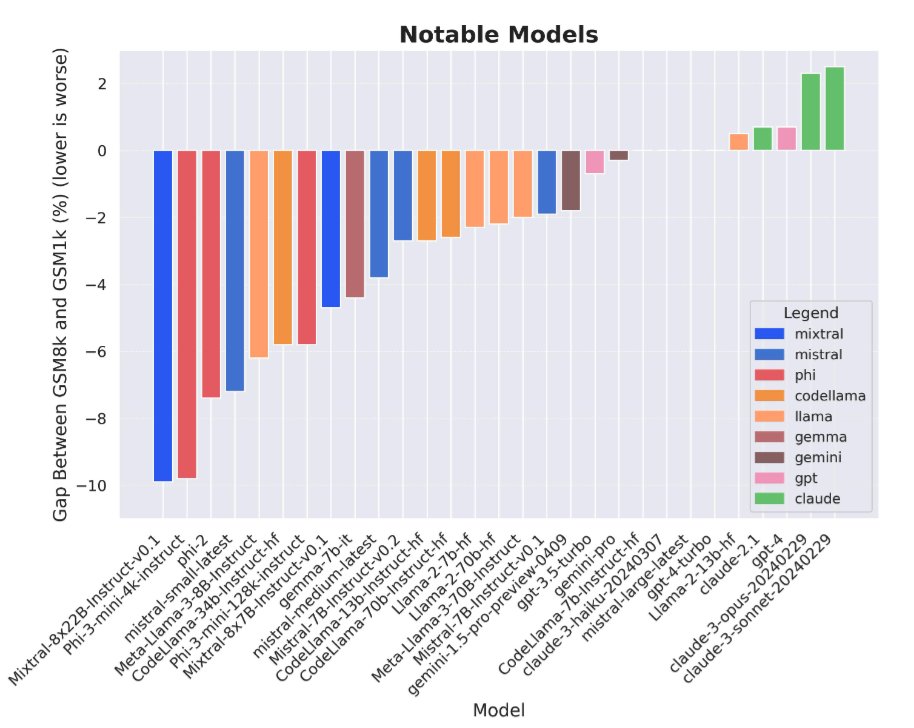
Data contamination is a huge problem for LLM evals right now. At Scale, we created a new test set for GSM8k *from scratch* to measure overfitting and found evidence that some models (most notably Mistral and Phi) do substantially worse on this new test set compared to GSM8k. 
Stepping back for a moment, LLM evals are really hard because LLMs themselves are trained on basically the entire Internet at this point, so any public benchmark you make will inevitably just end up in the LLM training set.
Ideally, you would solve this by creating custom, private evals and not releasing them. But that’s pretty hard to do typically … unless
We did this at Scale AI! After all, that is what we do! We created a new version of GSM8k from scratch called GSM1k and took great care to make sure it matches GSM8k on metrics like difficulty, number of steps in solution, answer magnitude, etc.
We find a huge range on how much models are overfit. On one end, models like Mistral or Phi do up to 10% worse on GSM1k compared to GSM8k. On the other end, models like Gemini, Claude, or GPT show basically no signs of being overfit.

I also want to commend Llama2 in particular, which (at least on GSM8k) did a great job at avoiding overfitting, especially relative to most other open source models.
So how much of this overfitting is data contamination? In one experiment, we compare a model’s perplexity on GSM8k to its performance gap between GSM8k and GSM1k. We find that models which are more likely to output GSM8k problems are indeed more likely to be overfit (obviously).

But it’s not the only factor! Some models aren’t very likely to generate GSM8k, but are extremely overfit (Math Shepherd). Other models it’s the opposite (Llema)! Our guess is that other factors, like choosing the final model checkpoint based on benchmarks, are also a reason.
Finally, I did want to mention — overfitting is not great yes, and it’s important for benchmarks to mean something credible about a model’s performance. But overfit models != bad models. Even the most overfit models are still *pretty* good at reasoning.
Phi-3 has a 10% drop on GSM1k compared to GSM8k — but it still solves 68% of GSM1k problems, which it definitely hasn’t seen before. That’s way more than any other similarly sized model and almost the same performance as dbrx-instruct, which has 132B params!
GSM1k will remain private for now. We include 50 examples (+1 in Table 1) in the paper, but the rest is hidden to prevent the same issue of data contamination that we are trying to solve. We pre-commit to releasing the data at a later point though (details in paper).
Finally, wanted to give a shout out to the “Do ImageNet Classifiers Generalize to ImageNet?” paper by @beenwrekt, @BeccaRoelofs, @lschmidt3 and @Vaishaal which was a huge inspiration for this work and a longtime favorite of mine. We learned a lot of lessons from them.

@beenwrekt @BeccaRoelofs @lschmidt3 @Vaishaal joint work with @_jeffda, Dean Lee, Vaughn Robinson, Catherine Wu, Will Song, Tiffany Zhao, Pranav Raja, @dylanslack20, @qin_lyu, @SeanHendryx, @russelljkaplan, @mikelunati, @summeryue0.
And of course, sponsored by the wonderful @alexandr_wang!
And of course, sponsored by the wonderful @alexandr_wang!
• • •
Missing some Tweet in this thread? You can try to
force a refresh



