

 The OpenAI API does not allow you to easily control how many tokens to spend at test-time. I hack my way around this by telling o1-mini how long I want it to think for. Afterwards, I can figure out how many tokens were actually used based on how much the query cost!
The OpenAI API does not allow you to easily control how many tokens to spend at test-time. I hack my way around this by telling o1-mini how long I want it to think for. Afterwards, I can figure out how many tokens were actually used based on how much the query cost!
 @evanzwangg @summeryue0 @squeakymouse777 @ellev3n11 @SeanHendryx PlanSearch significantly outperforms baselines on three popular code benchmarks: HumanEval+, MBPP+, and LiveCodeBench, a contaminated-free benchmark for competitive coding, across all models considered.
@evanzwangg @summeryue0 @squeakymouse777 @ellev3n11 @SeanHendryx PlanSearch significantly outperforms baselines on three popular code benchmarks: HumanEval+, MBPP+, and LiveCodeBench, a contaminated-free benchmark for competitive coding, across all models considered. 
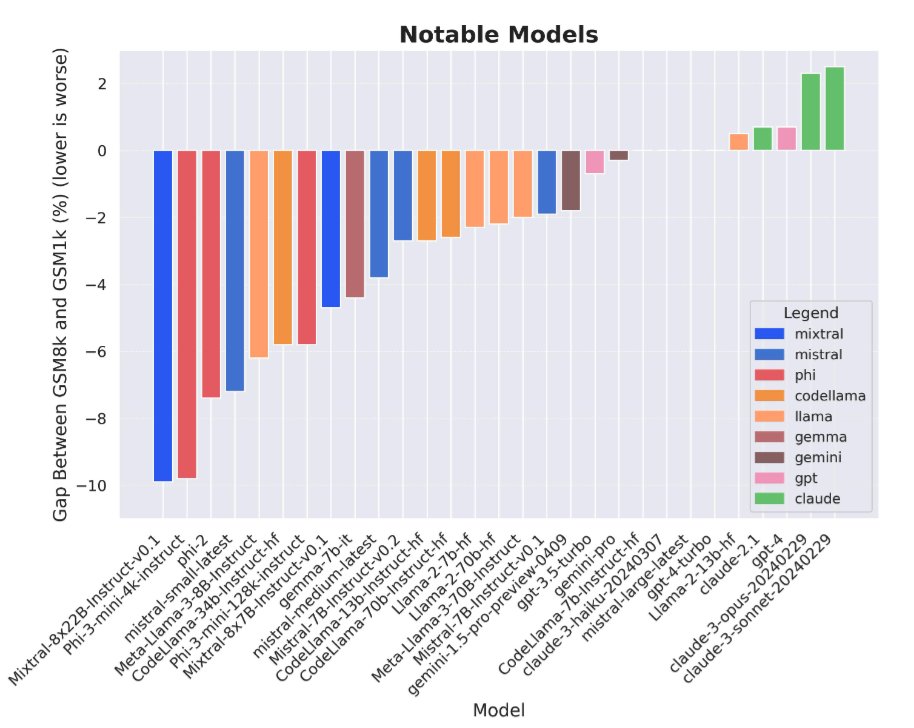 Stepping back for a moment, LLM evals are really hard because LLMs themselves are trained on basically the entire Internet at this point, so any public benchmark you make will inevitably just end up in the LLM training set.
Stepping back for a moment, LLM evals are really hard because LLMs themselves are trained on basically the entire Internet at this point, so any public benchmark you make will inevitably just end up in the LLM training set.