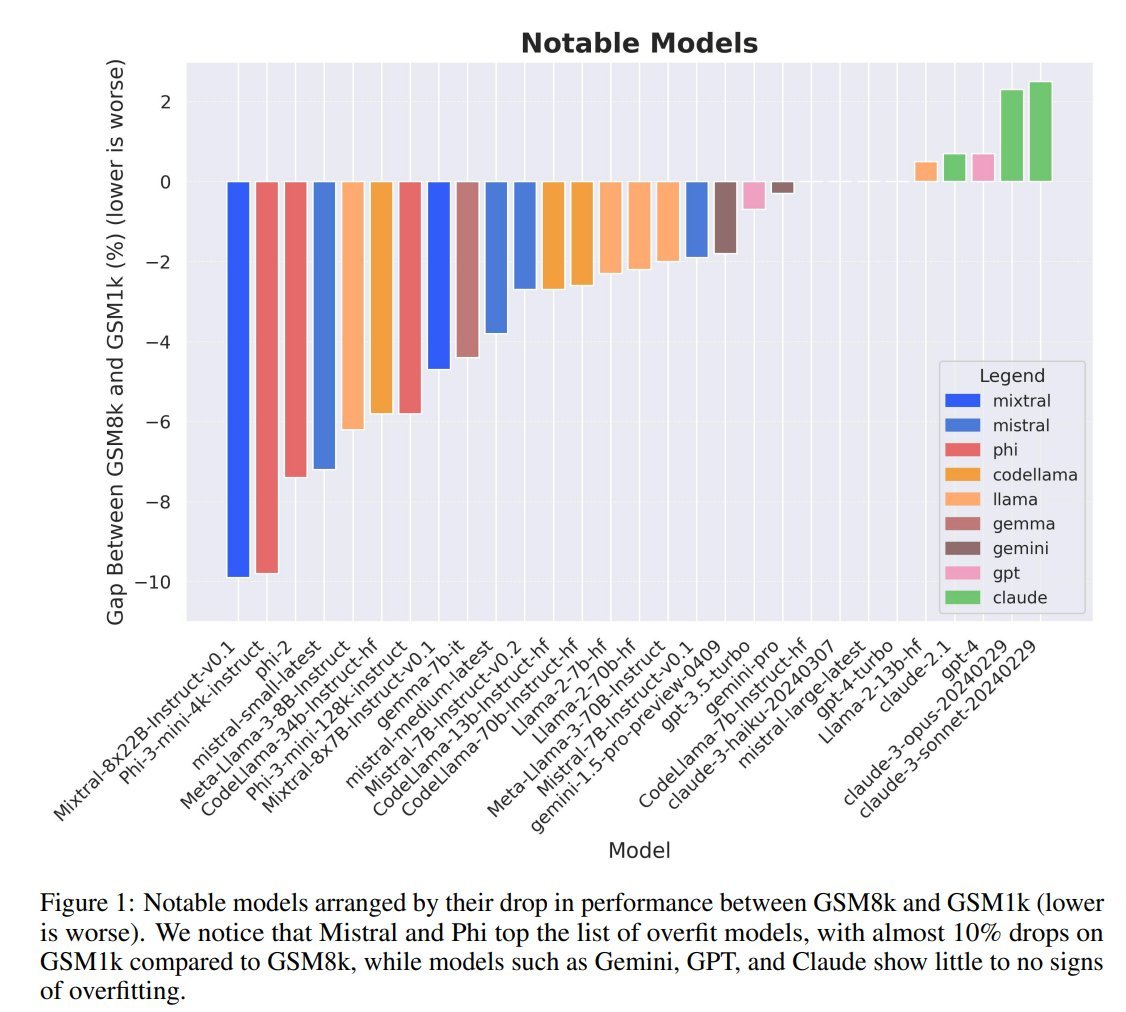
How overfit are popular LLMs on public benchmarks?
New research out of @scale_ai SEAL to answer this:
- produced a new eval GSM1k
- evaluated public LLMs for overfitting on GSM8k
VERDICT: Mistral & Phi are overfitting benchmarks, while GPT, Claude, Gemini, and Llama are not.
New research out of @scale_ai SEAL to answer this:
- produced a new eval GSM1k
- evaluated public LLMs for overfitting on GSM8k
VERDICT: Mistral & Phi are overfitting benchmarks, while GPT, Claude, Gemini, and Llama are not.
h/t to our incredible team for this research:
@hughbzhang @summeryue0, @_jeffda, Dean Lee Vaughn Robinson, Catherine Wu, Will Song, Tiffany Zhao, Pranav Raja, Dylan Slack, Qin Lyu, @seanh, Russell Kaplan, @mikelunati
paper link: arxiv.org/abs/2405.00332
@hughbzhang @summeryue0, @_jeffda, Dean Lee Vaughn Robinson, Catherine Wu, Will Song, Tiffany Zhao, Pranav Raja, Dylan Slack, Qin Lyu, @seanh, Russell Kaplan, @mikelunati
paper link: arxiv.org/abs/2405.00332
• • •
Missing some Tweet in this thread? You can try to
force a refresh