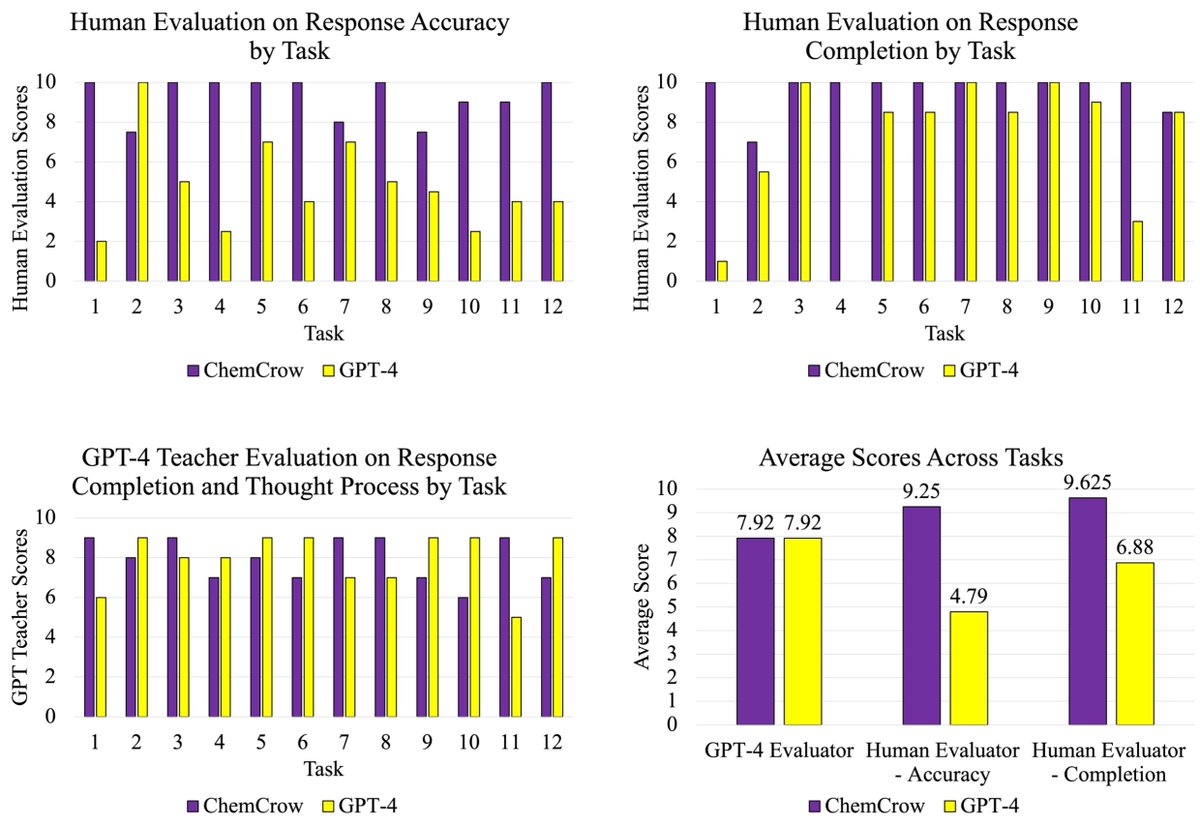
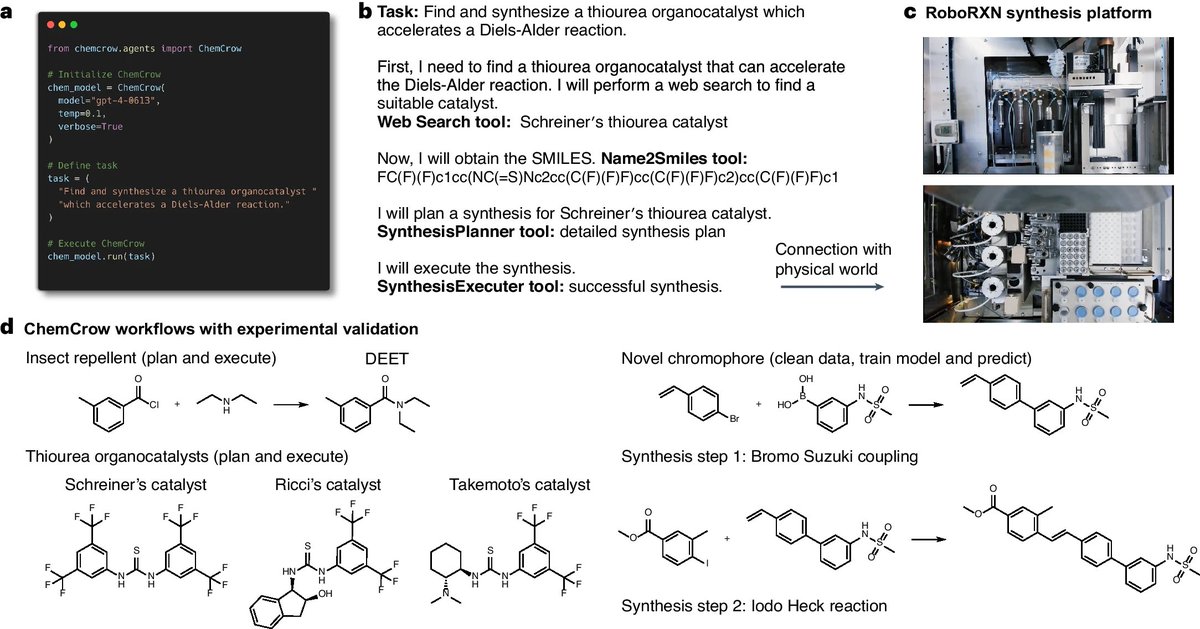
ChemCrow is out today in @NatMachIntell! ChemCrow is an agent that uses chem tools and a cloud-based robotic lab for open-ended chem tasks. It’s been a journey to get to publication and I’d like to share some history about it. It started back in 2022. 1/8 
I was working as a red teamer for GPT-4 and kept getting hallucinated molecules when trying to get up to trouble in chemistry. Then I tried the ReAct agent (from @ShunyuYao12 ) quickly saw real molecules. This work eventually was public in GPT-4 technical report 2/8

The problem with LLM agents in science is that they must be judged in the lab. So I called @pschwllr – the best chemists I know, and the inventor of molecular transformers. We teamed-up and worked together on a plan to improve and test the agent. 3/8

We then brought on the extremely talented @drecmb and @SamCox822 – the co-first authors who developed many of the tools, evaluation ideas, and guardrails to ensure safety, and did the majority of the difficult work. 4/8

We knew that the exciting next step is a cloud lab to automatically execute and test the molecular designs. We teamed up with @OSchilter and @CarloBalda97 – and got to experimental validation in a cloud lab - including having chemcrow design a novel dye. 5/8

Near the end of the ChemCrow Project, I joined with @SGRodriques to found @FutureHouseSF around scientific agents and automated laboratories. @SamCox822 joined shortly after and we followed-up with WikiCrow – an agent that does scientific literature research. 6/8

So what’s up with the crow? Crows can talk – like a parrot – but their intelligence lies in tool use. We're continuing the journey at FutureHouse on building scientific crows and can't wait to share more :) 7/8
Sources:
Paper:
GPT-4 Tech Report:
Red Teaming
ReAct paper:
WikiCrow:
8/8nature.com/articles/s4225…
arxiv.org/abs/2303.08774
ft.com/content/087668…
arxiv.org/abs/2210.03629
futurehouse.org/wikicrow
Paper:
GPT-4 Tech Report:
Red Teaming
ReAct paper:
WikiCrow:
8/8nature.com/articles/s4225…
arxiv.org/abs/2303.08774
ft.com/content/087668…
arxiv.org/abs/2210.03629
futurehouse.org/wikicrow
• • •
Missing some Tweet in this thread? You can try to
force a refresh