Computer Systems: A Programmer's Perspective" provides a detailed look at how computer systems function, focusing on system-level programming in C and x86 assembly.
This is a large thread covering the book materials, including 17 video lectures that will be added over time.
This is a large thread covering the book materials, including 17 video lectures that will be added over time.

Required Reading:
CMU Systems Programming book:
The C Programming Language by Kernighan and Ritchie: amazon.com/Computer-Syste…
amazon.com/Programming-La…
CMU Systems Programming book:
The C Programming Language by Kernighan and Ritchie: amazon.com/Computer-Syste…
amazon.com/Programming-La…
Course Materials and Labs
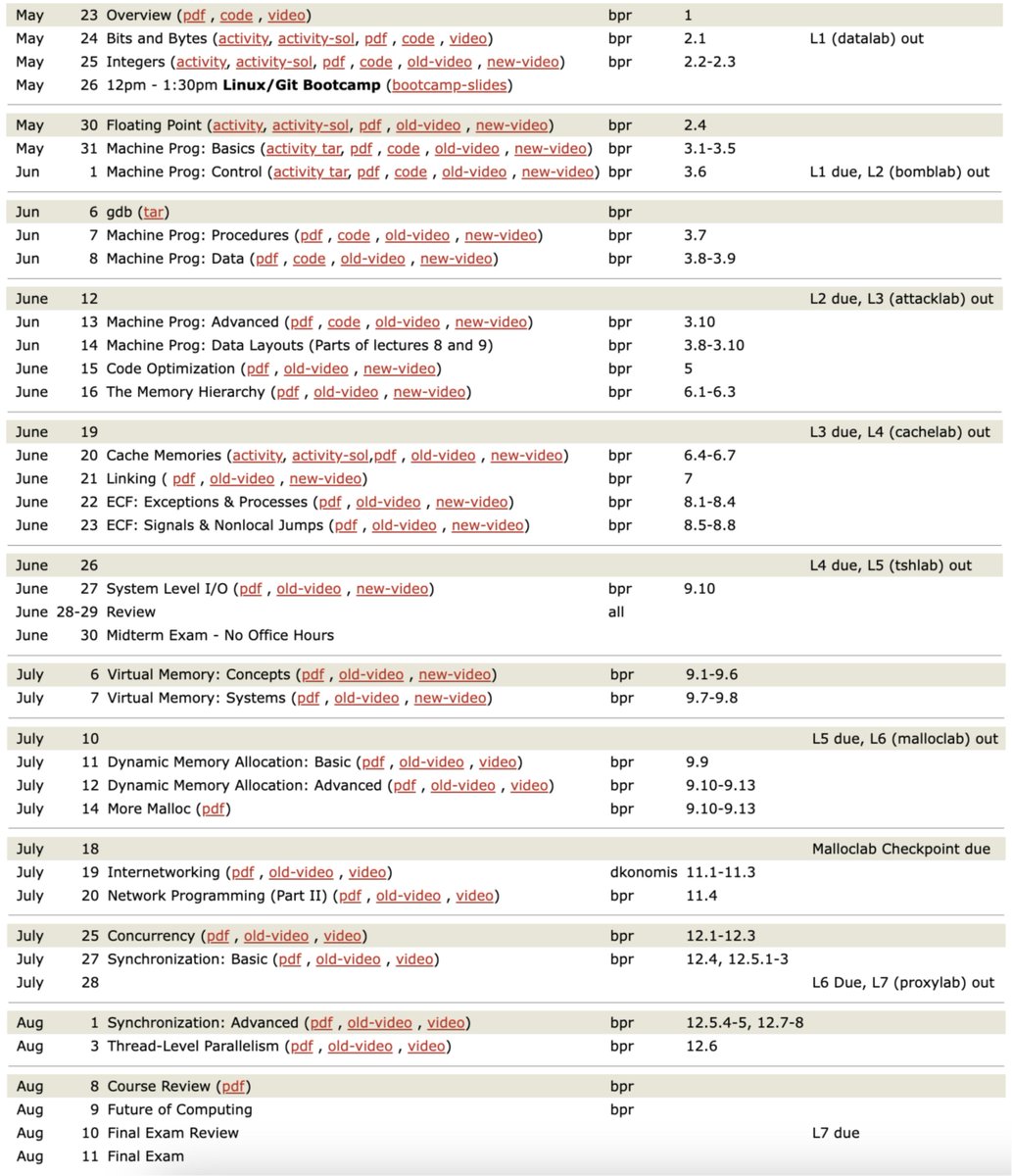
Course Schedule and Materials:
Lab Exercises:
Y86-64 Simulator Documentation:
Virtual Memory Documentation:
Book's Official Site: cs.cmu.edu/afs/cs/academi…
csapp.cs.cmu.edu/3e/labs.htm
csapp.cs.cmu.edu/3e/simguide.pdf
csapp.cs.cmu.edu/3e/docs/dsa.pdf
csapp.cs.cmu.edu/3e/home.html
Course Schedule and Materials:
Lab Exercises:
Y86-64 Simulator Documentation:
Virtual Memory Documentation:
Book's Official Site: cs.cmu.edu/afs/cs/academi…
csapp.cs.cmu.edu/3e/labs.htm
csapp.cs.cmu.edu/3e/simguide.pdf
csapp.cs.cmu.edu/3e/docs/dsa.pdf
csapp.cs.cmu.edu/3e/home.html
Video (1 of 27):
- Course Overview
The course is co-taught by Randy Bryant and Dave O'Hallaron, who are also co-authors of the textbook. You will need to buy the book to follow. The course, is designed to provide a comprehensive understanding of system-level programming.
- Course Overview
The course is co-taught by Randy Bryant and Dave O'Hallaron, who are also co-authors of the textbook. You will need to buy the book to follow. The course, is designed to provide a comprehensive understanding of system-level programming.
Video (2 of 27):
- Bits, Bytes, and Integers, Part1.
Randy Bryant explores data representations in this lecture, focusing on binary and hexadecimal systems, bitwise operations, and the nuances of unsigned vs. two's complement integers in programming.
- Bits, Bytes, and Integers, Part1.
Randy Bryant explores data representations in this lecture, focusing on binary and hexadecimal systems, bitwise operations, and the nuances of unsigned vs. two's complement integers in programming.
Video (3 of 27):
- Bits, Bytes, and Integers, Part2.
This lecture is on integer arithmetic, also unsigned and two's complement integers. It covers their binary representations, overflows, and the modular arithmetic within fixed bit limits. The examples show addition overflow and bit manipulation.
- Bits, Bytes, and Integers, Part2.
This lecture is on integer arithmetic, also unsigned and two's complement integers. It covers their binary representations, overflows, and the modular arithmetic within fixed bit limits. The examples show addition overflow and bit manipulation.
Video (4 of 27):
- Floating Point
This lecture covers floating point arithmetic, real number representation and manipulation in binary. Key topics include the binary point, binary fractions, and the challenges of representing certain numbers due to limitations in bit size.
- Floating Point
This lecture covers floating point arithmetic, real number representation and manipulation in binary. Key topics include the binary point, binary fractions, and the challenges of representing certain numbers due to limitations in bit size.
Video (5 of 27):
Start of core lectures.
- Machine-Level Programming I: Basics
This lecture covers machine-level programming, introducing assembly language as the bridge between high-level languages and machine-executed binary code. registers, memory addressing, and assembly.
Start of core lectures.
- Machine-Level Programming I: Basics
This lecture covers machine-level programming, introducing assembly language as the bridge between high-level languages and machine-executed binary code. registers, memory addressing, and assembly.
Video (6 of 27):
- Machine-Level Programming II: Control
Lab:
The lecture on Machine Level Programming II covers the machine-level code for system understanding and error analysis. Introduces "Bomb Lab" which is a pretty famous reverse engineering labcsapp.cs.cmu.edu/3e/labs.html
- Machine-Level Programming II: Control
Lab:
The lecture on Machine Level Programming II covers the machine-level code for system understanding and error analysis. Introduces "Bomb Lab" which is a pretty famous reverse engineering labcsapp.cs.cmu.edu/3e/labs.html
CMU (Carnegie Mellon University) Hosts all CC video lectures on Panopto.
scs.hosted.panopto.com/Panopto/Pages/…
scs.hosted.panopto.com/Panopto/Pages/…
Video (Recitation 3) - Datalab and Data Representations.
Link for Data Lab:
-
Description of lab:
Students implement simple logical, two's complement, and floating point functions, but using a highly restricted subset of C. For example, they might be asked to compute the absolute value of a number using only bit-level operations and straightline code. This lab helps students understand the bit-level representations of C data types and the bit-level behavior of the operations on data.scs.hosted.panopto.com/Panopto/Pages/…
csapp.cs.cmu.edu/3e/labs.html
Video (Recitation 4) - Bomb Lab.
Link for Bomb Lab:
-
Description of Lab:
A "binary bomb" is a program provided to students as an object code file. When run, it prompts the user to type in 6 different strings. If any of these is incorrect, the bomb "explodes," printing an error message and logging the event on a grading server. Students must "defuse" their own unique bomb by disassembling and reverse engineering the program to determine what the 6 strings should be. The lab teaches students to understand assembly language, and also forces them to learn how to use a debugger. It's also great fun. A legendary lab among the CMU undergrads.scs.hosted.panopto.com/Panopto/Pages/…
csapp.cs.cmu.edu/3e/labs.html
Video (7 of 27):
- Machine-Level Programming III: Procedures
This lecture covers procedure processes and the ABI (Application Binary Interface) in managing procedures on x86. This standardizes operations across systems, for efficient resource management.
- Machine-Level Programming III: Procedures
This lecture covers procedure processes and the ABI (Application Binary Interface) in managing procedures on x86. This standardizes operations across systems, for efficient resource management.
Here is a list of excellent resources for C programming and x86 assembly to complement the course material in the CMU book.
Online Resources
RTFMan Pages: - Always go to the man pages first!
SSL/TSL:
Beej's Networking C: - Amazing
Linux Syscalls:
Stanford Engineering C Lectures: - Best C Resource online
Stanford EDU C assignments:
Status of C99 features in GCC:
C VA_ARGS:
Algorithms for: DFT DCT DST FFT:
Apple Source Browser: - Lots of nice code implementations for things like strchr strcasecmp sprintf
GNU C Programming Tutorial:
Steve Holmes C Programming:
C Programming class notes:
C tutorials:
An Introduction to C:
FAQ:
Declarations:
Event-Driven:
Microsoft Learn - C Docs:
CASIO® Personal Computer PB-2000C Introduction to the C programming language: - In case you want to target a late 80s pocket computer that, in the Japanese production (the AI-1000), ran LISP 2 instead of C as its system language (both use HD61700d processor).
C Books (FREE)
UNIX System Calls and Subroutines:
Bug-Free C Code:
The C Book:
C elements of style:
The Art of Unix Programming:
Modern C:
Advanced Tutorials:
BitHacking
- god tier bit hacks
- bit hacking cheat sheet
Game Dev
A thread by @Mattias_G about making retro-style games in C/C++, and also about getting them to run in a browser.
Low Level
inline assembly:
OS-Development Build Your Own OS:
Build a Computer from Nand Gates to OS:
The Art of Assembly: - amazing
Introduction to 64-Bit Assembly Language Programming for Linux and OS X by Ray Seyfarth:
What Every Programmer Should Know About Memory by Ulrich Drepper:
Modern x64 Assembly by What's a Creel?:
Performance Programming: x64 Caches by What's a Creel?:
A Comprehensive Guide To Debugging Optimized x64 Code by Jorge:
Introduction to x64 Assembly by Chris Lomont:
Challenges of Debugging Optimized x64 code by Microsoft:
Microsoft x64 Software Conventions: - This will be your eternal companion and enforcer as you work on Windows.
The Netwide Assembler manual: - Contains all the information needed about programming with NASM syntax.
Intel 64 and IA-32 Architectures Software Developer Manuals: - Contain all the technical information regarding the CPU architecture, instructions, and timings.
x86 and amd64 instructions reference: - an excellent list of all the instructions available on the x86-64 instruction set. Be warned. Not everything maps 1:1 in either NASM/MASM syntax!
Intel Intrinsics Guide: - is an excellent guide to the intrinsic functions available for Intel CPUs.
Instruction Tables: - Reference instruction timings for various CPU generations.
Intel Documentation
Intel SDM Root Page: [](software.intel.com/en-us/articles…
kernel.org/doc/man-pages/
wiki.openssl.org/index.php/SSL/…
beej.us/guide/bgnet/
linuxhint.com/list_of_linux_…
web.stanford.edu/class/archive/…
gcc.gnu.org/c99status.html
en.cppreference.com/w/cpp/preproce…
kurims.kyoto-u.ac.jp/~ooura/fft.html
opensource.apple.com/source/Berkele…
crasseux.com/books/ctutoria…
strath.ac.uk/IT/Docs/Ccours…
eskimo.com/~scs/cclass/cc…
cslibrary.stanford.edu
cprog.tomsweb.net/cintro.html
c-faq.com
ericgiguere.com/articles/readi…
eventdrivenpgm.sourceforge.net
learn.microsoft.com/en-us/cpp/c-la…
pisi.com.pl/piotr433/manua…
cs.cf.ac.uk/Dave/C/
duckware.com/bugfreec/
publications.gbdirect.co.uk/c_book/
oualline.com/style/index.ht…
faqs.org/docs/artu/inde…
hal.inria.fr/hal-02383654/d…
cprogramming.com/advtutorial.ht…
graphics.stanford.edu/~seander/bitha…
cheatography.com/jsondhof/cheat…
https://twitter.com/Mattias_G/status/1762257302013284372
csapp.cs.cmu.edu/3e/waside/wasi…
wiki.osdev.org/Expanded_Main_…
nand2tetris.org
phatcode.net/res/223/files/…
rayseyfarth.com
people.freebsd.org/~lstewart/arti…
software.intel.com/en-us/articles…
blogs.msdn.microsoft.com/ntdebugging/20…
docs.microsoft.com/en-us/cpp/buil…
nasm.us/doc/
software.intel.com/en-us/articles…
felixcloutier.com/x86/
software.intel.com/sites/landingp…
agner.org/optimize/instr…
intel.com/content/www/us…
intel.com/content/www/us…
VIdeo (8 of 27):
- Machine-Level Programming IV: Data
This lecture, covers data representations, focusing on arrays and structs. They also look at how arrays of identical types and structs with various data types are structured and accessed in memory.
- Machine-Level Programming IV: Data
This lecture, covers data representations, focusing on arrays and structs. They also look at how arrays of identical types and structs with various data types are structured and accessed in memory.
Video (Recitation 5) - Attack Lab and Stacks
Link for Attack Lab & Buffer Lab:
-
Description of Lab: Teaches Linux Exploit Development
Note: Do both labs!
These labs are god tier, so do not skip them!
The "Attack Lab" represents an updated 64-bit version of the previously established 32-bit "Buffer Lab." In this lab, students exploit two x86-64 bins, each vulnerable to buffer overflow attacks. One executable is prone to code injection attacks, while the other is susceptible to return-oriented programming (ROP) attacks. The challenge is to craft exploits that alter the program’s execution. These are similar to flag discovery in a typical Capture The Flag (CTF) event. (there are levels with poitns)
The "Buffer Lab" focuses on exploiting a 32-bit x86 binary.scs.hosted.panopto.com/Panopto/Pages/…
csapp.cs.cmu.edu/3e/labs.html
Video (9 of 27):
- Machine-Level Programming V: Advanced Topics
Covers topics, including "Attack Lab" from previous post focusing on exploiting buffer overflows and security vulnerabilities in x86-64 programs. Also explores memory layout, unions, and related security measures.
- Machine-Level Programming V: Advanced Topics
Covers topics, including "Attack Lab" from previous post focusing on exploiting buffer overflows and security vulnerabilities in x86-64 programs. Also explores memory layout, unions, and related security measures.
Video (10 of 27):
- Program Optimization
This lecture on code optimization explains how understanding compilers can enhance code performance. The discussion covers optimizing programs to run faster by making them more compiler-friendly, considering what compilers manage well and the limitations they face.
- Program Optimization
This lecture on code optimization explains how understanding compilers can enhance code performance. The discussion covers optimizing programs to run faster by making them more compiler-friendly, considering what compilers manage well and the limitations they face.
• • •
Missing some Tweet in this thread? You can try to
force a refresh