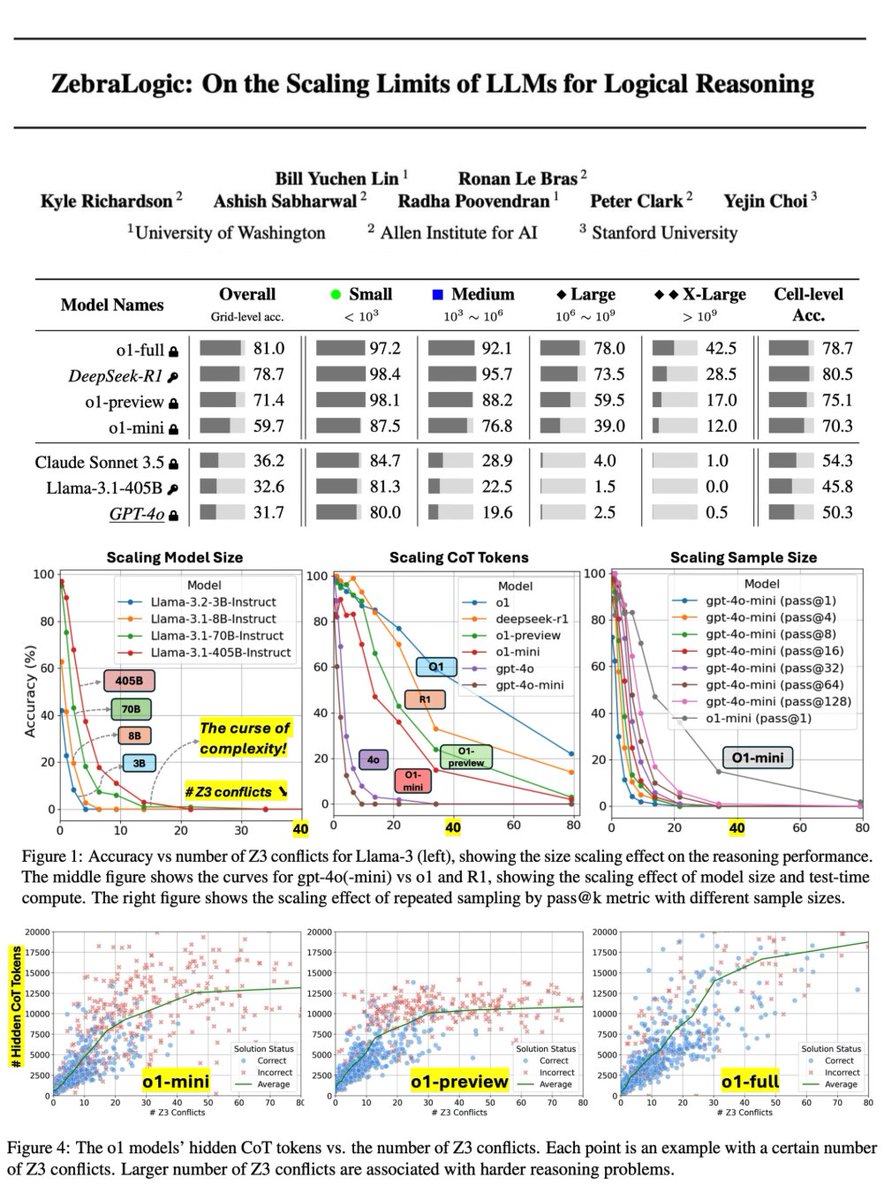
We've been re-evaluating LLMs with a unified setup by controlling the factors such as prompting, sampling, output parsing, etc. Introducing 🔥 ZeroEval: a simple unified framework for evaluating LLMs. Two initial tasks are MMLU-Redux and GSM. Btw, GPT-4o-mini @openai is super great. [1/n]
Github: github.com/yuchenlin/Zero…
Github: github.com/yuchenlin/Zero…

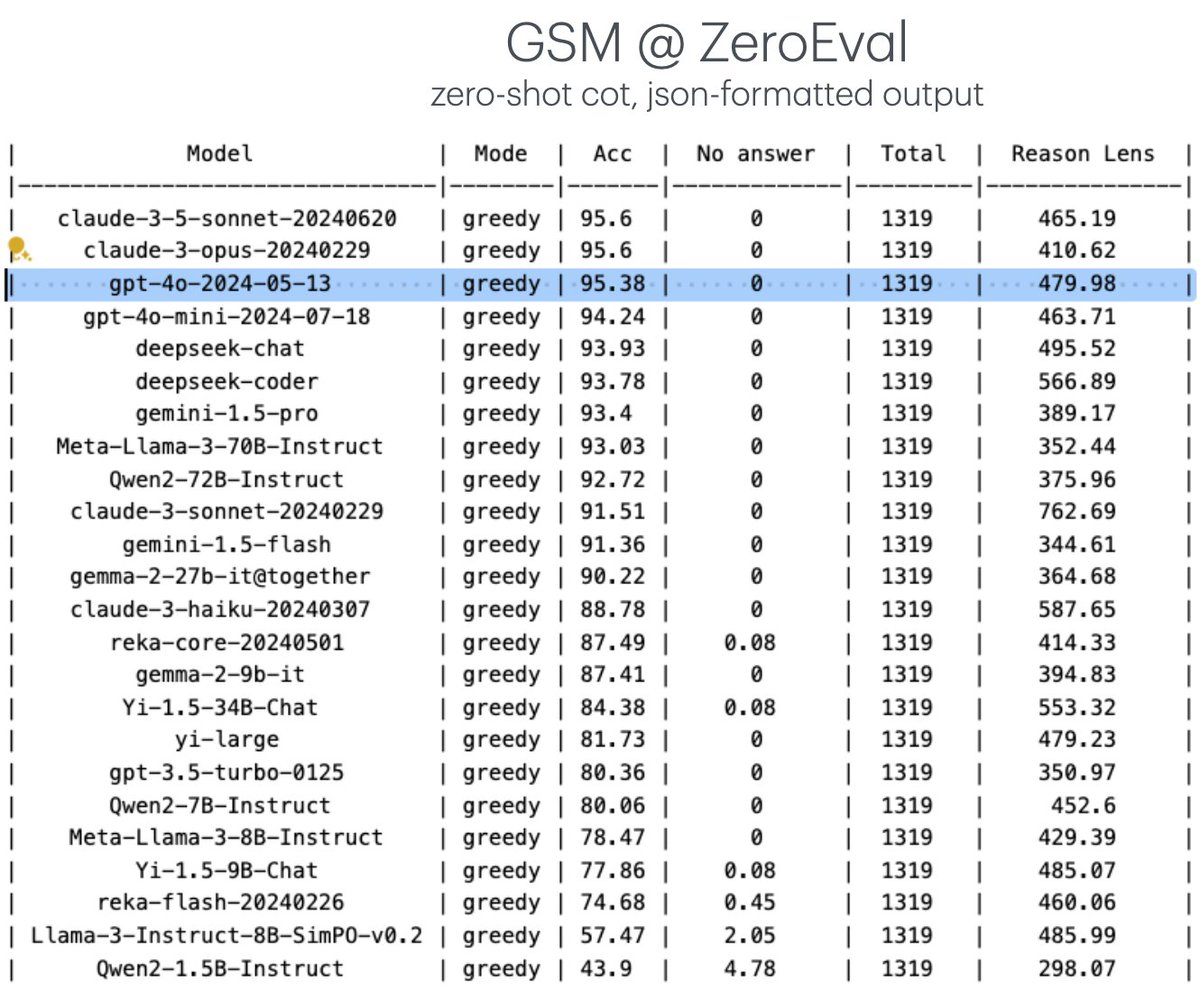
In ZeroEval, we perform zero-shot prompting, and instruct LM to output both reasoning and answer in a json-formatted output. We are actively adding new tasks. Contributions are welcome! [2/n]
Add your task to ZeroEval: ⬇️ github.com/yuchenlin/Zero…
Add your task to ZeroEval: ⬇️ github.com/yuchenlin/Zero…

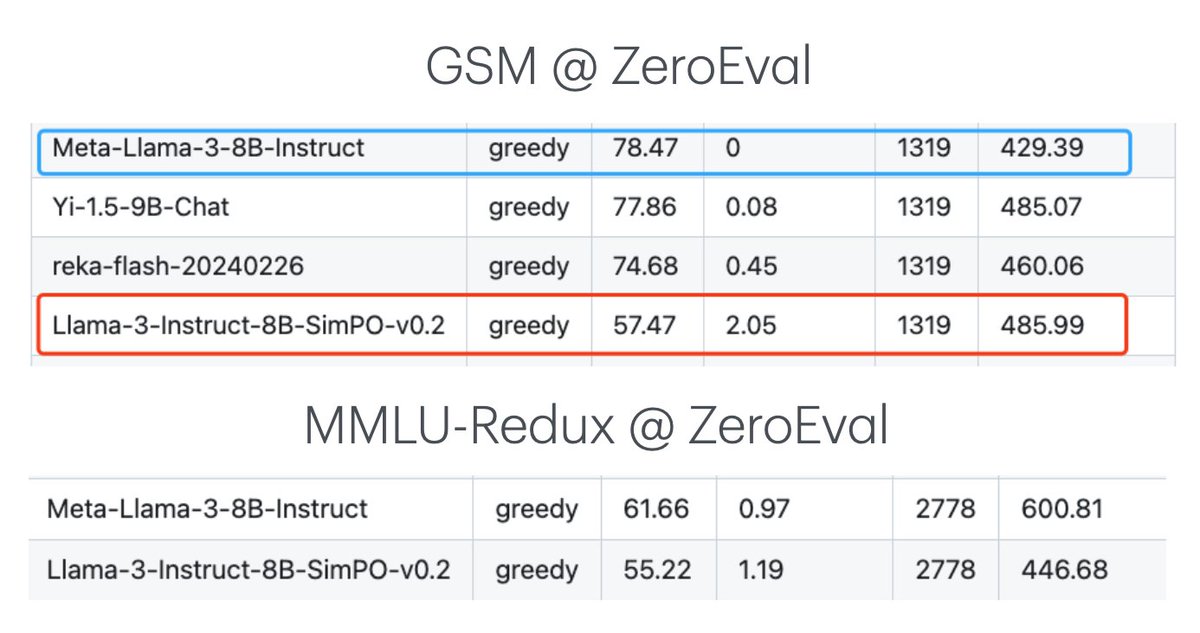
Forgetting issue can be evident for methods like DPO and SimPO. For example, SimPO (on top of Llama3-8b-instruct) can significantly hurt both MMLU-Redux and GSM performance. Mitigating alignment tax is still a hard problem! [3/n]
More results: github.com/yuchenlin/Zero…
More results: github.com/yuchenlin/Zero…
We find that gemma-2-27b-it on @vllm_project may have some problems. Its performance is much worse than using @togethercompute 's api or the vanilla @huggingface inference. 9B on vLLM is okay, though [4/n]

• • •
Missing some Tweet in this thread? You can try to
force a refresh