The Transformers architecture clearly explained 👇🏻 

Today I'm starting a new series of threads to simplify the concept of Transformers and what's behind the Natural Language abilities of LLMs.
Let's start with the basics of the Transformer architecture:
The encoder/decoder concept. 🧠✨
Let's start with the basics of the Transformer architecture:
The encoder/decoder concept. 🧠✨
1️⃣ 𝗪𝗛𝗔𝗧 𝗜𝗦 𝗔 𝗧𝗥𝗔𝗡𝗦𝗙𝗢𝗥𝗠𝗘𝗥?
A Transformer is a neural network that excels at understanding the context of sequential data and generating new data from it.
They are the first to rely solely on self-attention, without using RNNs or convolution.
A Transformer is a neural network that excels at understanding the context of sequential data and generating new data from it.
They are the first to rely solely on self-attention, without using RNNs or convolution.

2️⃣ 𝗧𝗥𝗔𝗡𝗦𝗙𝗢𝗥𝗠𝗘𝗥 𝗔𝗦 𝗔 𝗕𝗟𝗔𝗖𝗞 𝗕𝗢𝗫
Imagine a Transformer for language translation as a BLACK BOX. 🎩
• Input: A sentence in one language.
• Output: Its translation.
But what happens inside this black box? Let's find out! 🔍
Imagine a Transformer for language translation as a BLACK BOX. 🎩
• Input: A sentence in one language.
• Output: Its translation.
But what happens inside this black box? Let's find out! 🔍

3️⃣ 𝗘𝗡𝗖𝗢𝗗𝗘𝗥/𝗗𝗘𝗖𝗢𝗗𝗘𝗥 architecture
• Input: Spanish sentence ¿De quién es?
• Encoder: Transforms it into a structured format capturing its essence.
• Decoder: Receives this encoded data and generates the translation.
• Output: The translated sentence: Whose is it?
• Input: Spanish sentence ¿De quién es?
• Encoder: Transforms it into a structured format capturing its essence.
• Decoder: Receives this encoded data and generates the translation.
• Output: The translated sentence: Whose is it?

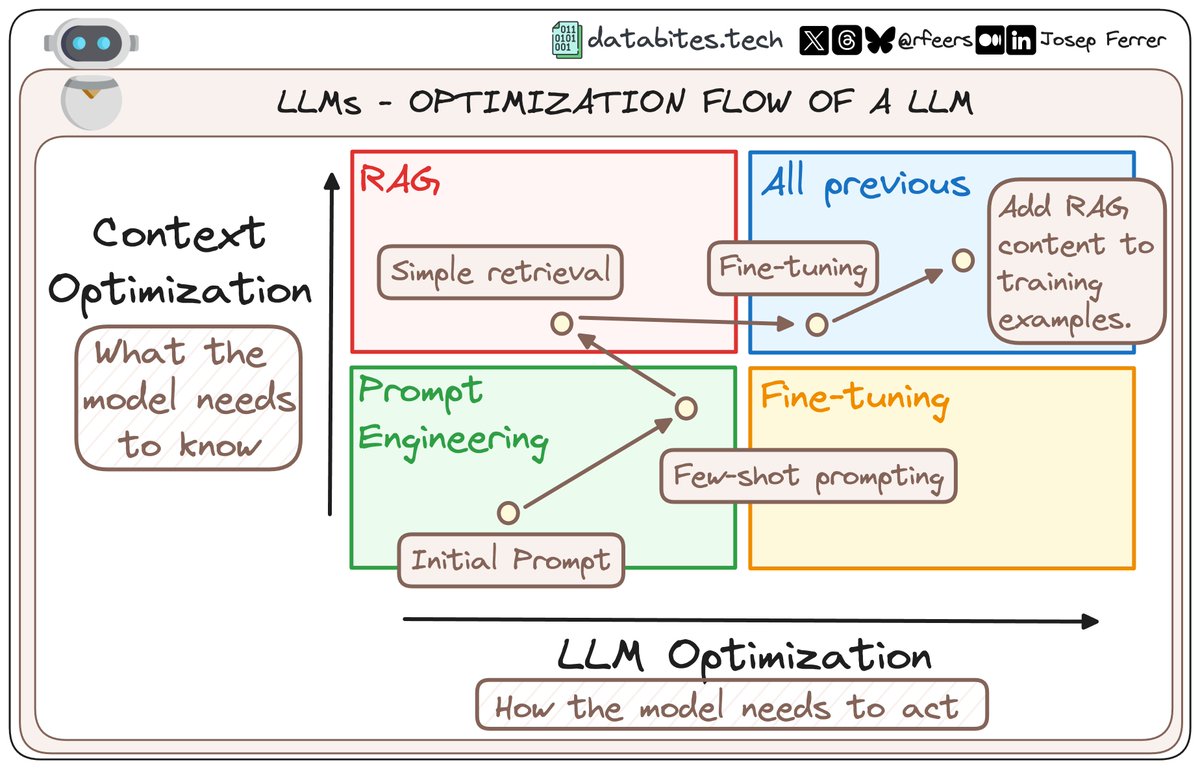
4️⃣ 𝗧𝗛𝗘 𝗔𝗥𝗖𝗛𝗜𝗧𝗘𝗖𝗧𝗨𝗥𝗘 BEHIND THE TRANSFORMERS
Each encoder and decoder is made up of layers. Here's how they work:
• Encoders: Process the input sequentially, layer by layer.
• Decoders: Take the encoded data and generate the output step by step.
Each encoder and decoder is made up of layers. Here's how they work:
• Encoders: Process the input sequentially, layer by layer.
• Decoders: Take the encoded data and generate the output step by step.
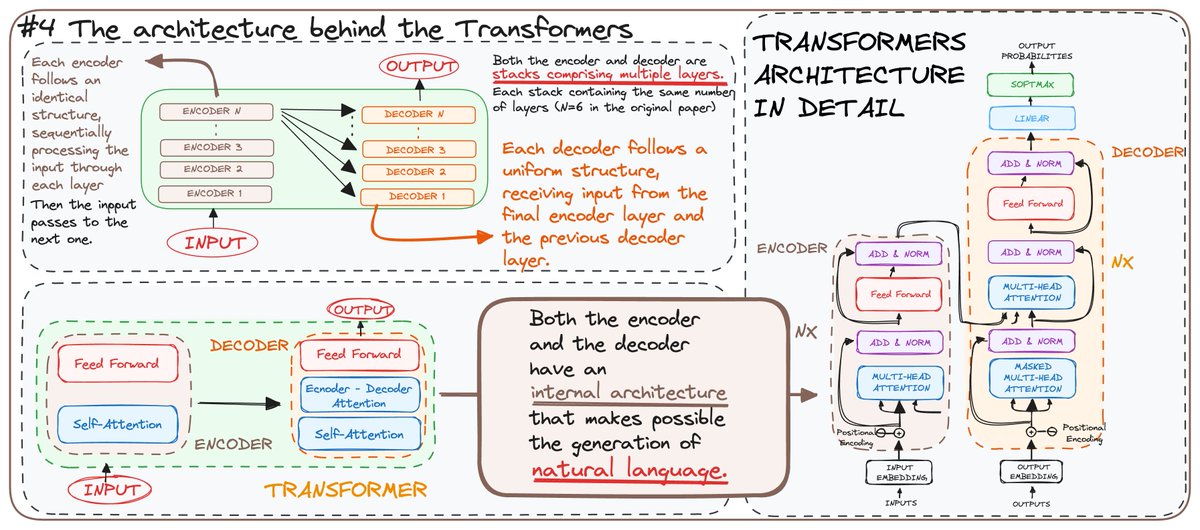
Both use self-attention and feed-forward neural networks, enabling the generation of natural language.
Tomorrow we will break down the architecture of both core elements of the Transformers architecture.
Tomorrow we will break down the architecture of both core elements of the Transformers architecture.
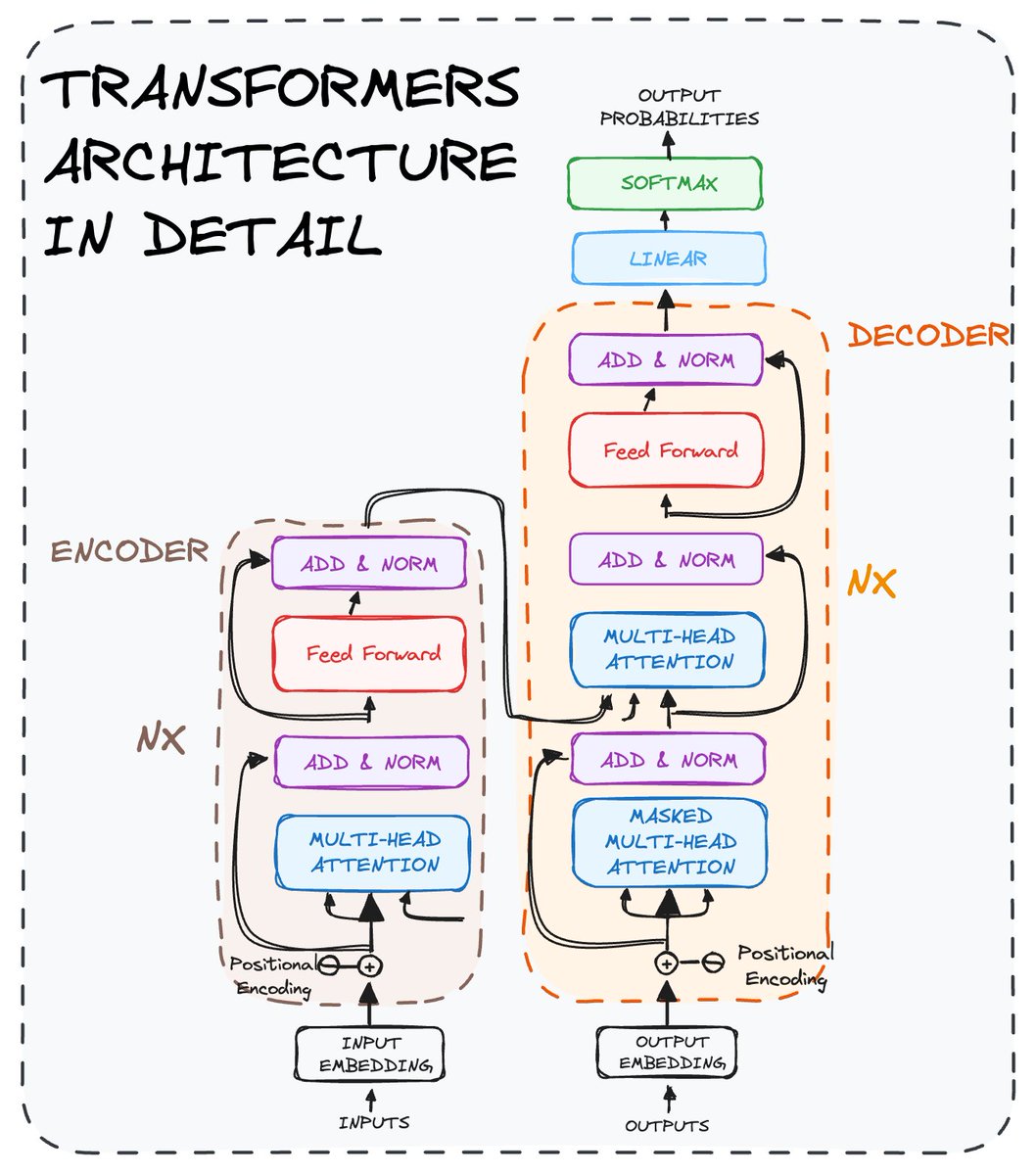
Do you want to understand the Transformers architecture?
Then go check my last article about Transformers👇🏻
aigents.co/data-science-b…
Then go check my last article about Transformers👇🏻
aigents.co/data-science-b…
If you are interested in...
• Python 🐍
• SQL 💾
• ML/MLOps 🛠
• LLMs & NLP 🗣
• DataViz 🗣
• AI Engineering ⚙️
Then follow me → @rfeers
• Python 🐍
• SQL 💾
• ML/MLOps 🛠
• LLMs & NLP 🗣
• DataViz 🗣
• AI Engineering ⚙️
Then follow me → @rfeers
Did you like this post?
Then join my freshly started DataBites newsletter to get all my content right to your mail every week! 🧩
👉🏻 databites.tech
Then join my freshly started DataBites newsletter to get all my content right to your mail every week! 🧩
👉🏻 databites.tech

• • •
Missing some Tweet in this thread? You can try to
force a refresh