I'm giving the variant update at the SAVE meeting on Monday so I thought I'd put out a preview for comment.
We are now at our 4th 'high water' mark since the Omicron wave based on wastewater surveillance.
1/
We are now at our 4th 'high water' mark since the Omicron wave based on wastewater surveillance.
1/

I thought I would give an abbreviated summary of the last year in variants.
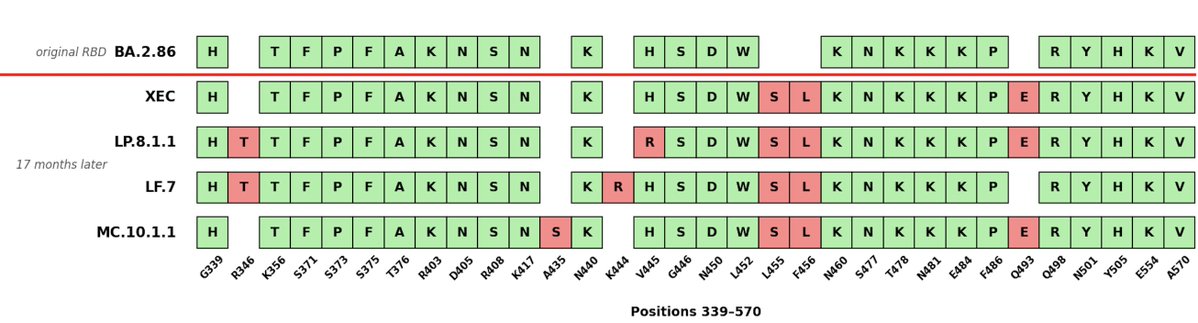
A little over a year ago BA.2.86 started circulating, a lineage that was almost certainly derived from a persistent infection.
2/
A little over a year ago BA.2.86 started circulating, a lineage that was almost certainly derived from a persistent infection.
2/

BA.2.86 was pretty fit, but it was still sensitive to a lot of Class 1 antibodies.
However, it quickly picked up S:L455S (making it JN.1), which evaded these antibodies, and it was off to the races.
3/
However, it quickly picked up S:L455S (making it JN.1), which evaded these antibodies, and it was off to the races.
3/

JN.1 played around with a lot of mutations, but its favorite was F456L, a change that it independently picked up at least 20 times.
4/
4/

We then started seeing lineages that combined 456L with the old favorite R346T, which was the same change that BA.4/5 picked up during the summer 2 years ago.
This happened lots of times, but the best know was probably KP.2.
5/
This happened lots of times, but the best know was probably KP.2.
5/

But those lineages got some competition when another 456L lineage picked up R493E (KP.3).
For whatever reason this really only happened once. I'm not sure why. It was a C->G mutation, which is rare.
KP.3 seemed to be fitter than the 456L/346T gang.
6/
For whatever reason this really only happened once. I'm not sure why. It was a C->G mutation, which is rare.
KP.3 seemed to be fitter than the 456L/346T gang.
6/

I always expected KP.3 to pick up R346T, but there hasn't appeared to be much selective pressure for that to happen. There's probably some redundancy in 346T/493E advantages.
7/
7/
Then the 346T/456L group found a neat trick. They deleted position S31, which gave them the leg up again.
8/
8/

But of course, KP.3 figured out that it could do that too.
The S31 deletion has occurred lots of times now, but the fittest among them seems to be KP.3.1.1.
9/
The S31 deletion has occurred lots of times now, but the fittest among them seems to be KP.3.1.1.
9/

So what does the S31 deletion do. It's been reported to both increase fitness (higher infectivity in pseudotype assays), and antibody evasion.
The deletion introduces a glycosylation site, but it also restores the insertions/deletion balance in that part of Spike.
10/
The deletion introduces a glycosylation site, but it also restores the insertions/deletion balance in that part of Spike.
10/

RaTG-13 had a glycosylation site at this position too, and I've seen it introduced in lots of cryptic lineages.
However, I never saw the 31 deletion until the JN.1 insertion occurred. Probably because of the insertion/deletion balance thing.
11/
However, I never saw the 31 deletion until the JN.1 insertion occurred. Probably because of the insertion/deletion balance thing.
11/

If I were smart I would put a 3D structure here showing why they insertion/deletion balance is important, but I'm not that smart (and it's just a theory).
12/
12/
So what are we watching now?
There is a chimera-of-chimeras in China called XDV.1 that is doing pretty well there, but not really anywhere else.
Its spike is derived from JN.1, but it doesn't have any of the 'advanced' changes.
It does have the XBB Orf9b:I5T though.
13/
There is a chimera-of-chimeras in China called XDV.1 that is doing pretty well there, but not really anywhere else.
Its spike is derived from JN.1, but it doesn't have any of the 'advanced' changes.
It does have the XBB Orf9b:I5T though.
13/

Finally there is the new chimera that just got designated, XEC. This one just appeared in June and has fared pretty well. I don't think it could keep up with KP.3.1.1 currently, but if it picks up a few more changes it might.
14/
14/

Overall it's an odd time. It's pretty clear that KP.3.1.1 (and equivalent) is going to have a sweep the world the way that JN.1 did, but I'm not sure what happens after that.
We'll be watching.
15/15
We'll be watching.
15/15
• • •
Missing some Tweet in this thread? You can try to
force a refresh