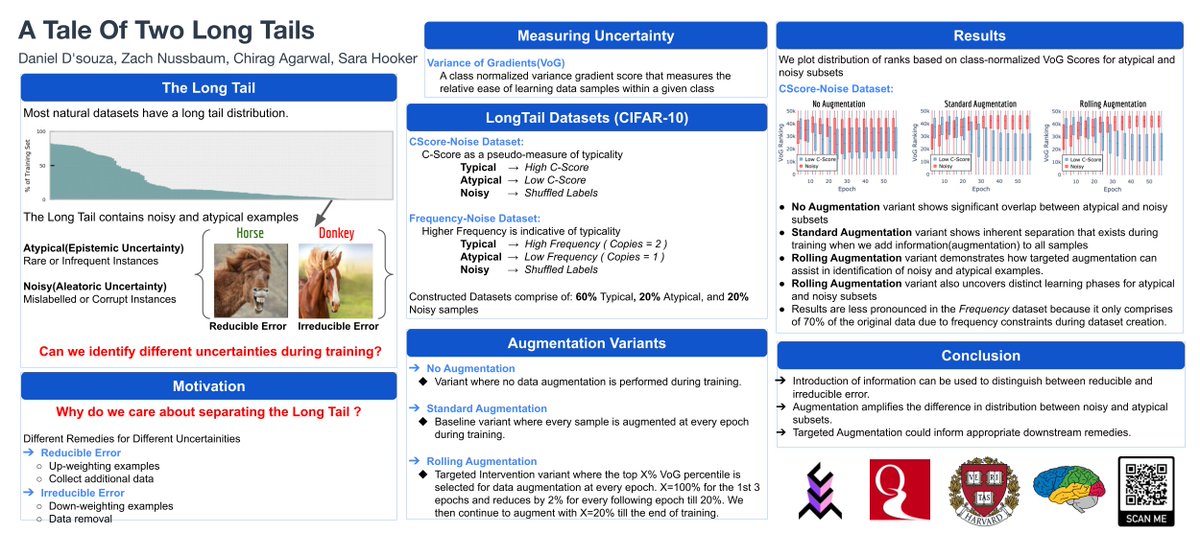
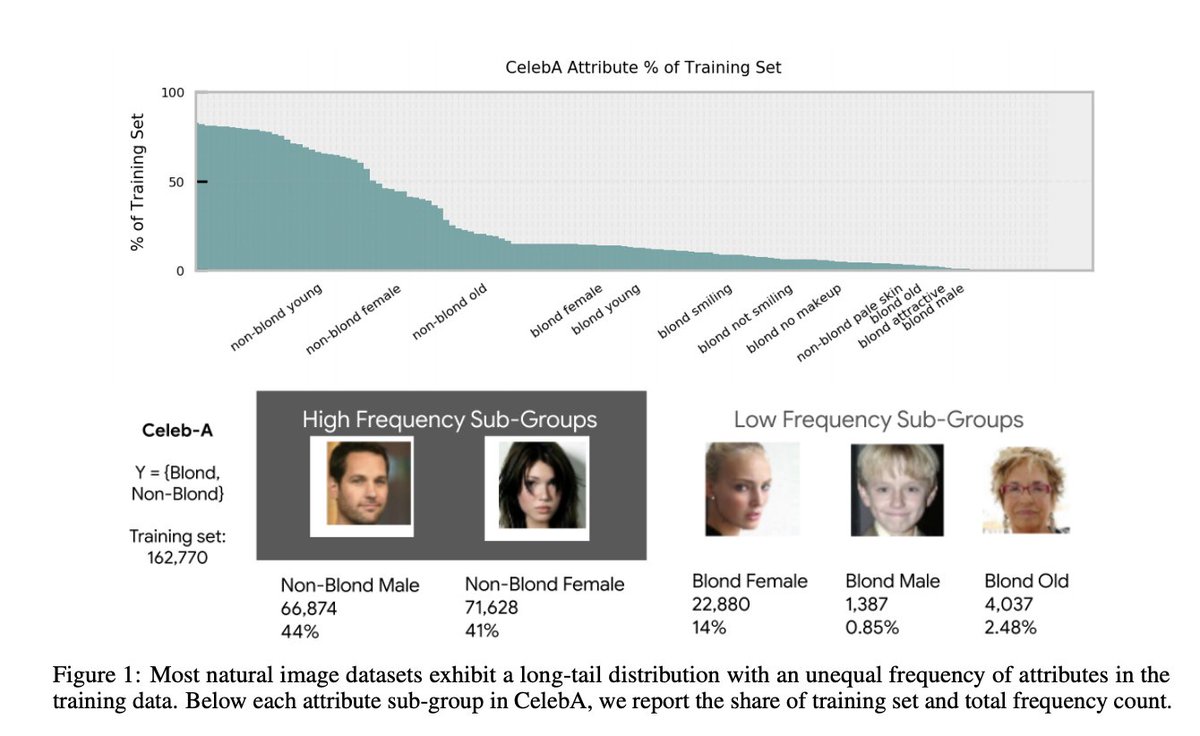
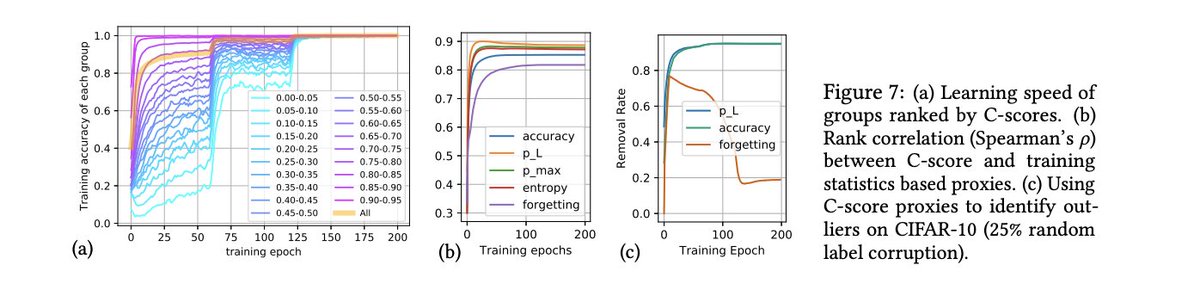
One of the biggest open questions is what is the limit of synthetic data.
Does training of synthetic data lead to mode collapse?
Or is there a path forward that could outperform current models?
Does training of synthetic data lead to mode collapse?
Or is there a path forward that could outperform current models?

What is missing from this conversation is that the success of synthetic data hinges on how you optimize in the data space.
A few recent papers highlight this tension well, on the side of dangers of synthetic data -- excellent paper released in Nature.
📜nature.com/articles/s4158…
A few recent papers highlight this tension well, on the side of dangers of synthetic data -- excellent paper released in Nature.
📜nature.com/articles/s4158…
The Nature paper finds that:
Eventually, if you train repeatedly on synthetic data trained from a single model – you generate gibberish.
This due to repeat sampling of the mode of the distribution. You lose the long-tail. It is also why synthetic sampling can amplify bias.
Eventually, if you train repeatedly on synthetic data trained from a single model – you generate gibberish.
This due to repeat sampling of the mode of the distribution. You lose the long-tail. It is also why synthetic sampling can amplify bias.
But what if you strategically sample, either by constraining criteria for sampling or expanding to multiple teachers -- two of our recent works look at it from this lens.
The results suggest the road ahead for synthetic data is far more promising.
The results suggest the road ahead for synthetic data is far more promising.
In LLM see, LLM do we call this active inheritance and use it to optimize in the data space towards non-differentiable objectives.
https://x.com/sarahookr/status/1808237222522769410
We constrain the generation process to explicitly steer towards minimization or maximization of non-differentiable features. 📈
The results speak for themselves: we saw considerable improvements for all attributes.
The results speak for themselves: we saw considerable improvements for all attributes.

In follow up work -- instead of following traditional "single teacher" paradigm, we show massive gains for multilingual through arbitrage sampling.
Selectively sampling parts of the distribution from different teachers avoids mode collapse.
Selectively sampling parts of the distribution from different teachers avoids mode collapse.
https://x.com/sarahookr/status/1828786620566249724
Arbitrage 📈 will likely benefit any specialized domain where we don't expect a single model to perform well at all parts of the distribution we care about.
This work starts to directly address the question: "Can you avoid model collapse when you rely on synthetic data?"
This work starts to directly address the question: "Can you avoid model collapse when you rely on synthetic data?"

By sampling strategically -- you avoid overfitting to the limitations of any single teacher. We dramatically outperform single teachers.
This also suggests mode collapse can be avoided outside of a setting where you repeatedly train on the outputs of a single teacher.
This also suggests mode collapse can be avoided outside of a setting where you repeatedly train on the outputs of a single teacher.
Overall -- I am most excited that we are now moving as a field to optimizing in the data space.
Historically, high-quality data has been costly to curate, which has precluded adapting training sets “on-the-fly” to target new properties. Now, we can steer in the data space.
Historically, high-quality data has been costly to curate, which has precluded adapting training sets “on-the-fly” to target new properties. Now, we can steer in the data space.
If you made it this far, read the excellent article by @alisonmsnyder for @axios covering these different perspectives on whether there is a ceiling to progress using synthetic data.
axios.com/2024/07/27/syn…
axios.com/2024/07/27/syn…
• • •
Missing some Tweet in this thread? You can try to
force a refresh