Let's talk about CPU scaling in games. On recent AMD CPUs, most games run better on single CCD 8 core model. 16 cores doesn't improve performance. Also Zen 5 was only 3% faster in games, while 17% faster in Linux server. Why? What can we do to make games scale?
Thread...
Thread...
History lesson: Xbox One / PS4 shipped with AMD Jaguar CPUs. There was two 4 core clusters with their own LLCs. Communication between these clusters was through main memory. You wanted to minimize data sharing between these clusters to minimize the memory overhead.
6 cores were available to games. 2 taken by OS in the second cluster. So game had 4+2 cores. Many games used the 4 core cluster to run your thread pool with work stealing job system. Second cluster cores did independent tasks such as audio mixing and background data streaming.
Workstation and server apps usually spawn independent process per core. There's no data sharing. This is why they scale very well to workloads that require more than 8 cores. More than one CCD. We have to design games similarly today. Code must adapt to CPU architectures.
On a two CCD system, you want to have two thread pools locked on these cores, and you want to push tasks to these thread pools in a way that minimizes the data sharing across the thread pools. This requires designing your data model and communication in a certain way.
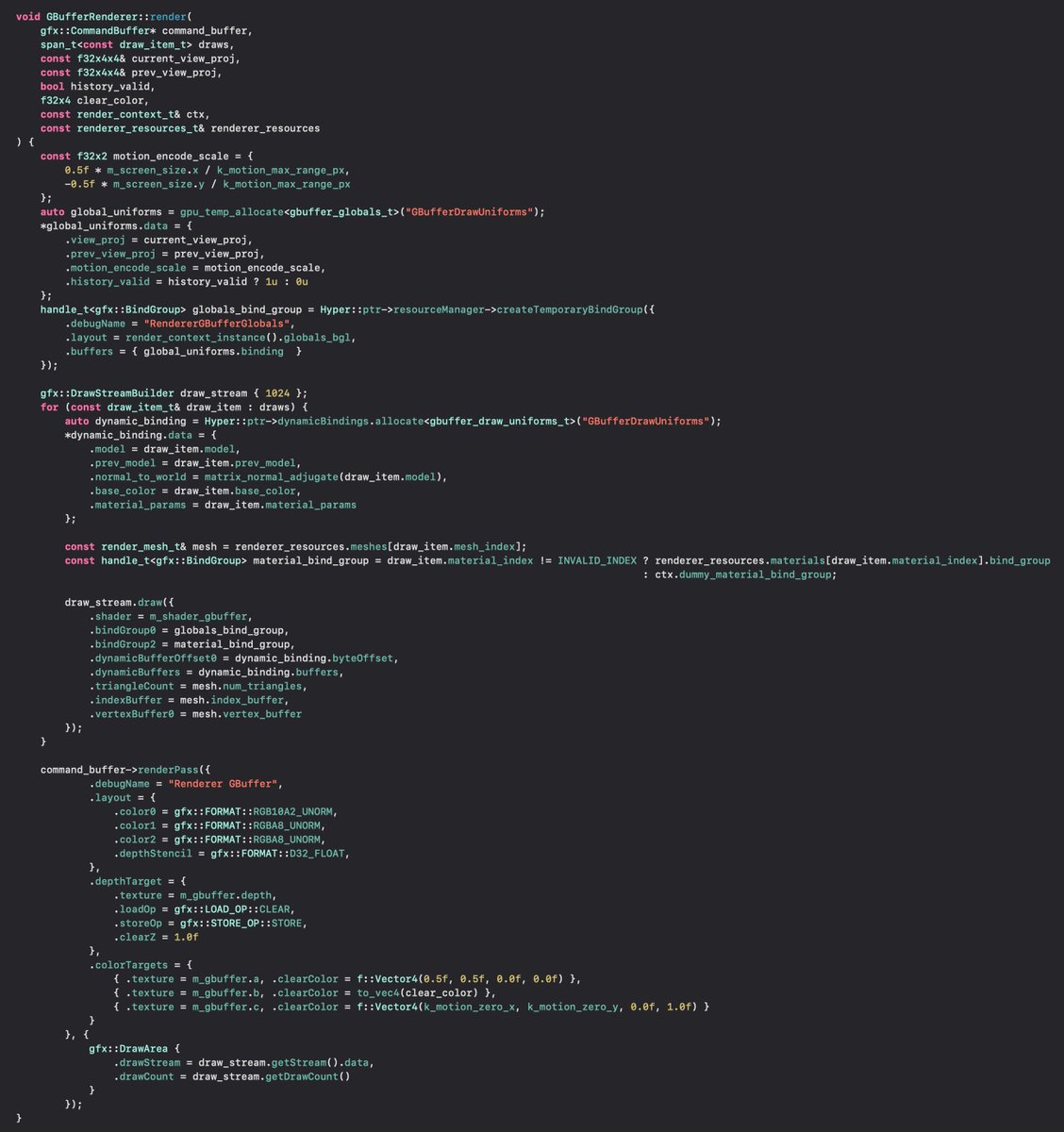
Let's say you use a modern physics library like Jolt Physics. It uses a thread pool (or integrates to yours). You could create Jolt thread pool on the second CCD. All physics collisions, etc are done in threads which share a big LLC with each other.
Once per frame you get a list of changed objects from the physics engine. You copy transforms of changed physics engine objects to your core objects, which live in the first CCD. It's a tiny subset of all the physics data. The physics world itself will never be accessed by CCD0.
Same can be done for rendering. Rendering objects/components should be fully separated from the main game objects. This way you can start simulating the next frame while rendering tasks are still running. Important for avoiding bubbles in your CPU/GPU execution.
Many engines already separate rendering data structures fully from the main data structures. But they make a crucial mistake. They push render jobs in the same global job queue with other jobs, so they will all be distributed to all CCDs with no proper data separation.
Instead, the graphics tasks should be all scheduled to a thread pool that's core locked to a single CCD. If graphics is your heaviest CPU hog, then you could allocate physics and game logic tasks to the thread pool in the other CCD. Whatever suits your workload.
Rendering world data separation is implemented by many engines already. It practically means that you track which objects have been visually modified and bump allocate the changed data to a linear ring buffer which is read by the render update tasks when next frame render starts.
This kind of design where you fully separate your big systems has many advantages: It allows refactoring each of them separately, which makes refactoring much easier to do in big code bases in big companies. Each of these big systems also can have unique optimal data models.
In a two thread pool system, you could allocate independent background tasks such as audio mixing and background streaming to either thread pool to load balance between them. We could also do more fine grained splitting of systems, by investigating their data access patterns.
Next topic: Game devs historically were drooling about new SIMD instructions. 3dNow! Quake sold AMD CPUs. VMX-128 was super important for Xbox 360 and Cell SPUs for PS3. Intel made mistakes with AVX-512. AVX-512 was initially too scattered and Intel's E-cores didn't support it. 

Game devs were used to writing SIMD code either by using a vec4 library or hand written intrinsics. vec4 already failed with 8-wide AVX2, and hand written instrinsics failed with various AVX-512 instruction sets and various CPU support. How do we solve this problem today?
Unreal Engine's new Chaos Physics was written with Intel's ISPC SPMD compiler. ISPC allows writing SMPD code similar to GPU compute shaders on CPU side. It supports compiling the same code to SSE4, ARM NEON, AVX, AVX2 and AVX-512. Thus it solves the instruction set fragmentation.
Unity's new Burst C# compiler aims to do the same for Unity. Burst C# is a C99-style C# subset. The compiler leans heavily on autovectorization. Burst C# has implicit knowledge of data aliasing allowing it to autovectorize better than standard compiler. Same is true for Rust.
However autovectorization is always fragile no matter how many "restrict" keywords you put either manually or by the compiler. ISPCs programming model is better suited for reliable near optimal AVX-512 generation.
ISPC compiles C/C++ compatible object files. They are easy to call from your game engine code. Workloads such as culling, physics simulation, particle simulation, sorting, etc can be done using ISPC to get AVX2 (8 wide) and AVX-512 (16 wide) performance benefits.
The last topic: SMT and Zen 5 dual decoders. Zen 5 has independent decoders for both threads. This helps server workloads. Zen 5 also has wider execution units to sustain running two SMT threads better. Can we design our game code to work better with SMT (Hyperthreading)?
The biggest problem with SMT is actually the same problem that we have with E-cores: Thread time variance. If we assume 130% SMT throughput (vs one thread on CPU), both SMT threads run at 65% performance. So they take 54% longer to finish...
Many game engines still have a main thread and some have a graphics thread too. These dedicated threads often become performance bottlenecks. If any of these critical threads gets scheduled to E-core or some other thread runs on the same core with SMT, we have a problem.
I have a solution: Don't have a main thread at all. Just use tasks that spawn tasks. This way programmers can't write code in main thread. Problem solved? Yes, if you are writing a new engine from scratch. Very hard to refactor original engine to "no main thread" model.
The other problem is that simple schedulers implement parallel for loops by evenly splitting the job to N workers. What if one of these workers is E-core or SMT thread? Other threads finish sooner, but next task has to wait for the slowest E-core/SMT thread to finish...
The solution for this is to use work stealing. For parallel for loops, I recommend using "lazy binary splitting". This balances very well with minimal scheduling overhead. Basically you always steal half of the work instead of fixed amount of work.
dl.acm.org/doi/10.1145/16…
dl.acm.org/doi/10.1145/16…
Conclusions: Solutions exist for minimizing multi-CCD data sharing, improving scheduling for E-cores/SMT and cross platform SPMD SIMD programming (AVX2/AVX-512). We need to improve our engine tech to make it more suitable for modern processors. CPUs have changed. Tech must too.
@hkultala And this is for 8 core models in gaming. Games still don't scale to 16 cores properly as it requires game engine changes. Same with E-cores and SMT. Performance benefit could be bigger if engine architecture was modified.
@AgileJebrim Also static load balancing on modern cache hierarchies is difficult. So many different cache levels. 200 cycle memory latency on a 6 wide system means up to 1200 instruction stall for a cache miss. This is dynamic behavior. You can't predict cache misses statically.
@AgileJebrim You want to threat a 16 core AMD Zen CPU similarly as a dual GPU setup. You don't want to split parallel for between them, as then results are 50/50 split in their memories. Next step needs to do mixed reads from two memories, if access pattern doesn't match exactly.
@AgileJebrim If you want to statically allocate the workload so that it fits both of these CPUs, you have to limit your CPU workload to two medium performance cores. You lose performance on both the dual-core iPhone 6 and 7 and you also lose all E-cores on the Android...
• • •
Missing some Tweet in this thread? You can try to
force a refresh