
There is much excitement about this prompt with claims that it helps Claude 3.5 Sonnet outperform o1 in reasoning.
I benchmarked this prompt to find out if the this claim is true ( thanks for @ai_for_success for the heads on this last night ) 🧵
I benchmarked this prompt to find out if the this claim is true ( thanks for @ai_for_success for the heads on this last night ) 🧵
https://twitter.com/_philschmid/status/1842846050320544016
The TLDR is that this prompt does not improve Claude 3.5 Sonnet to o1 levels in reasoning but it does tangibly improve its performance in reasoning focused benchmarks.
However, this does come at the expense of 'knowledge' focused benchmarks where the model is more directly generating text it has been trained on.
However, this does come at the expense of 'knowledge' focused benchmarks where the model is more directly generating text it has been trained on.
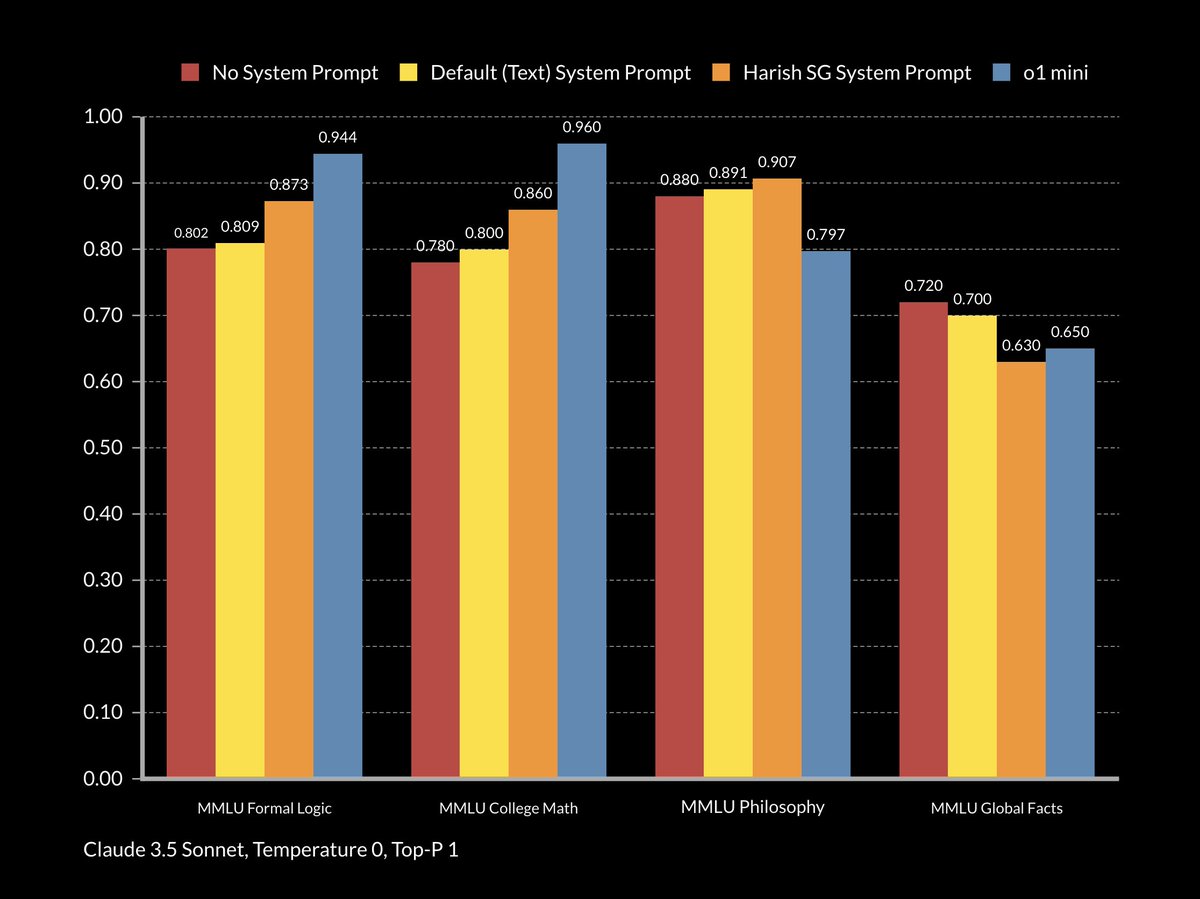
The 'formal logic' and 'college mathematics' benchmarks have significant reasoning focus. OpenAi's o1 excels in these. The use of this prompt with Sonnet also tangibly improves these.
The 'global facts' benchmark, like many other subject matter benchmarks, are much less reasoning focused. They're more about what the model knows and doesn't know. A complex prompt can 'confuse' a model so that even though the model can typically provide the correct answer it under performs because of the prompt.
This is what is happening here with this prompt applied.
The 'global facts' benchmark, like many other subject matter benchmarks, are much less reasoning focused. They're more about what the model knows and doesn't know. A complex prompt can 'confuse' a model so that even though the model can typically provide the correct answer it under performs because of the prompt.
This is what is happening here with this prompt applied.
I want to add an additional note here. The use of this prompt means that a user will get an answer after a significant delay.
In fact, it took Sonnet about 50% longer to complete the benchmarks compared to o1 mini and 100-200% longer than when using a simpler prompt.
Token length was similarly impacted ( 100-200% more tokens ) so a significant incremental cost.
In fact, it took Sonnet about 50% longer to complete the benchmarks compared to o1 mini and 100-200% longer than when using a simpler prompt.
Token length was similarly impacted ( 100-200% more tokens ) so a significant incremental cost.
• • •
Missing some Tweet in this thread? You can try to
force a refresh



