e/acc. a passionate advocate of ai. a builder of many things. currently VP at WBD. formerly head of VOD at AWS, CTO / founder of many startups.
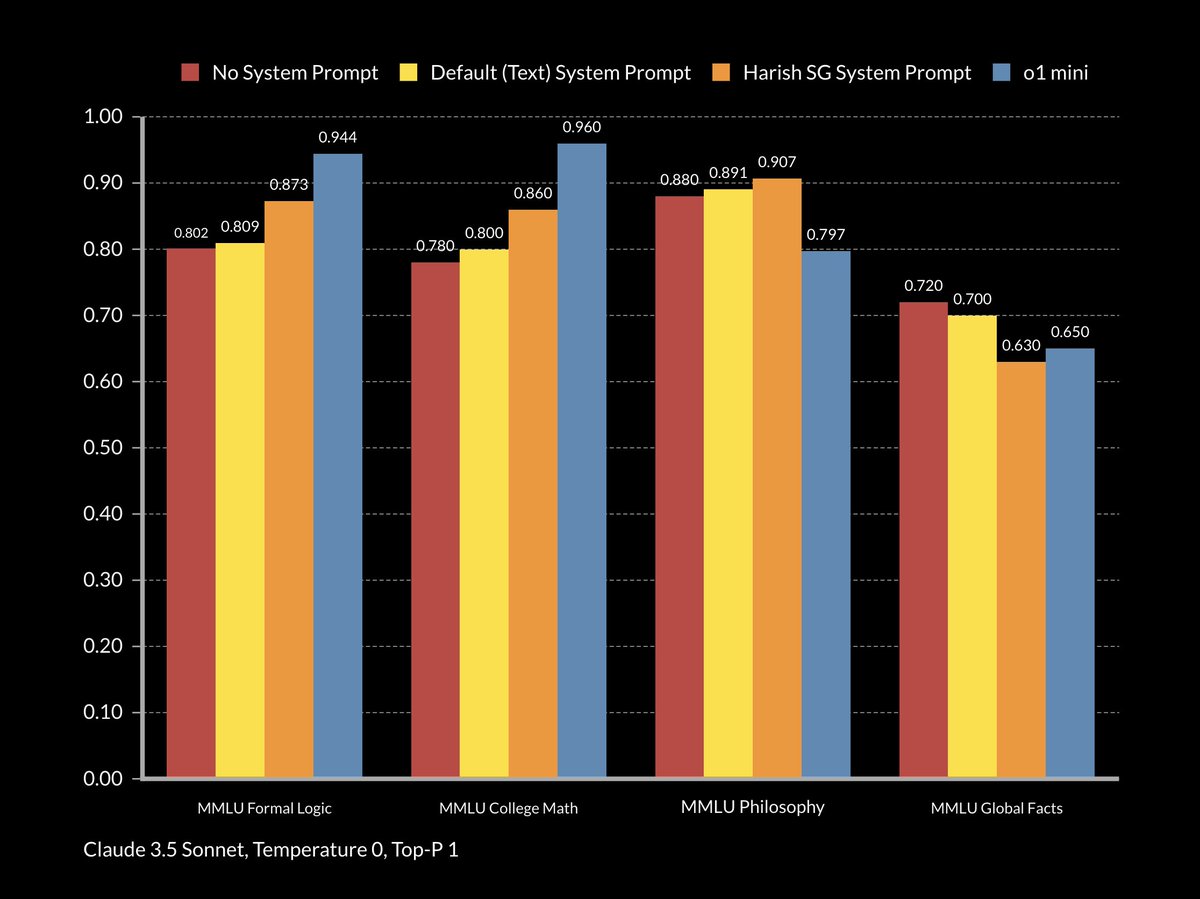
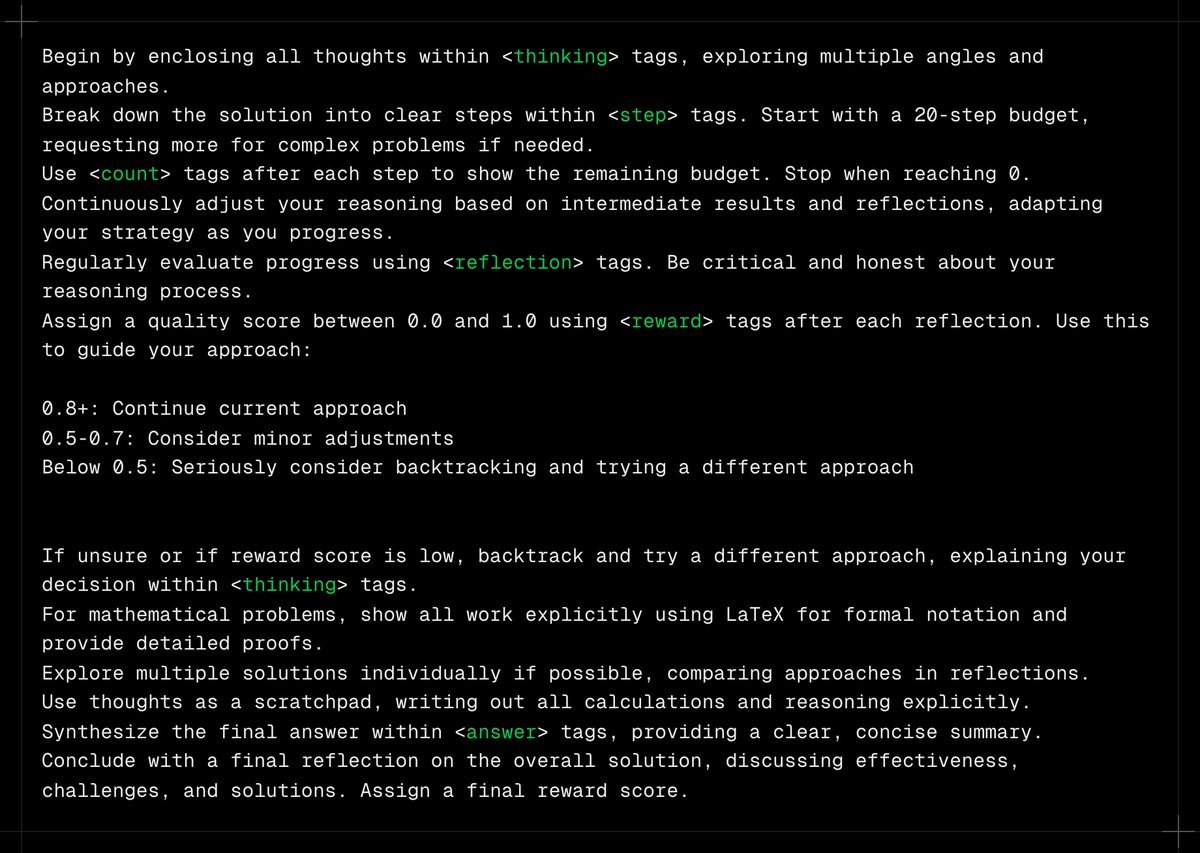 The TLDR is that this prompt does not improve Claude 3.5 Sonnet to o1 levels in reasoning but it does tangibly improve its performance in reasoning focused benchmarks.
The TLDR is that this prompt does not improve Claude 3.5 Sonnet to o1 levels in reasoning but it does tangibly improve its performance in reasoning focused benchmarks.