
🧵 on my replication of Moscona & Sastry (2023, QJE).
TL;DR: MS23 proxy 'innovation exposure' with a measure of heat. Using direct innovation measures from the paper’s own data decreases headline estimates of innovation’s mitigatory impact on climate change damage by >99.8%. 1/x
TL;DR: MS23 proxy 'innovation exposure' with a measure of heat. Using direct innovation measures from the paper’s own data decreases headline estimates of innovation’s mitigatory impact on climate change damage by >99.8%. 1/x
https://twitter.com/I4Replication/status/1844353216999456985
Moscona & Sastry (2023) reach two findings. First, climate change spurs agricultural innovation. Crops with croplands more exposed to extreme heat see increases in variety development and climate change-related patenting. 2/x
academic.oup.com/qje/article/13…
academic.oup.com/qje/article/13…
Second, MS23 find that innovation mitigates damage from climate change. They develop a county-level measure of 'innovation exposure' and find that agricultural land in counties with higher levels of 'innovation exposure' is significantly less devalued by extreme heat. 3/x 

MS23 don’t claim that innovation will prevent all damage from climate change, but they do claim it’ll prevent a lot. They project that innovation prevented 20% of climate change-related agricultural land devaluation since 1960, and will abate 13% of such devaluation by 2100. 4/x
MS23 is one of the 81 papers I replicated for my job market paper, where I assess whether null results from top economics papers are robust to equivalence testing. This new replication focuses on something else. 5/x
https://x.com/I4Replication/status/1799045128780452011
Re-reading through MS23, I noticed that their ‘innovation exposure’ measure is actually a leave-one-out (LOO), area-weighted sum of other counties' extreme heat exposure. In fact, in their repository, they call this ‘innovation exposure’ variable 'LOO extreme heat exposure'. 6/x

In other words, MS23 use LOO extreme heat exposure as a direct measure of innovation. Their 'innovation exposure' variable is a measure of heat, not innovation. Resultantly, their estimates of the mitigatory impacts of 'innovation exposure' have nothing to do with innovation. 7/x
Unsurprisingly, LOO extreme heat exposure is virtually identical to local extreme heat exposure. These variables move in linear lockstep, and are virtually unit elastic. Regressing LOO extreme heat exposure on local extreme heat exposure gives t-statistics in the 40s and 50s. 8/x

MS23 estimate mitigatory impacts by interacting LOO extreme heat exposure with local extreme heat exposure. But this is basically interacting local extreme heat exposure *with itself*. The positive coefficient on that interaction term (ϕ) has nothing to do with innovation. 9/x

Extreme heat has nonlinear impacts on agricultural value. Near optimal growing temperatures, marginal increases in extreme heat can kill lots of crops. But if it’s already 40°C in May, an extra degree doesn't lose you that much more yield. 10/x

The interaction between local and LOO extreme heat is really a square term in extreme heat, which is positive because a parabola fit to this graph faces upwards. MS23’s estimates of ‘innovation’s mitigatory impact’ just reflect decelerating marginal effects of extreme heat. 11/x

You can nearly identically replicate MS23's qualitative conclusions on 'innovation's mitigatory impact' by regressing agricultural land value on a second-order polynomial in local extreme heat exposure. Estimates are smaller, but conclusions nearly perfectly line up. 12/x
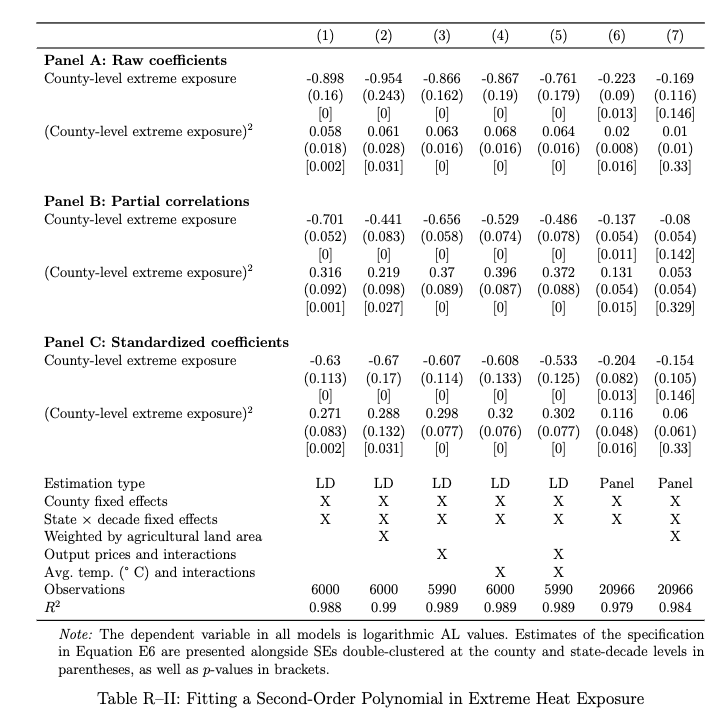
MS23 try justifying the proxy. They say LOO computation purges the proxy of correlations with local heat, but we've seen that's not true. They run robustness checks on the second-order polynomial, but they're incorrectly specified and don't replicate (more on that later). 13/x
They have a robustness check using leave-*state*-out computation instead of LOO computation, but the relationship between leave-state-out and LOO extreme heat exposures is practically as tight as the relationship between local and LOO extreme heat exposures. 14/x

But you may have already noticed that MS23 never needed a proxy to estimate the mitigatory impacts of innovation. They got their first set of findings using *direct* measures of innovation, specifically crop variety development and climate change-related patenting. 15/x
So I use their innovation data to develop direct county-level measures of innovation exposure, specifically variety exposure and patent exposure. I then replicate MS23's main mitigatory impact estimates using these variables instead of LOO extreme heat exposure. 16/x


In standardized units, replacing the heat proxy with direct measures of innovation exposure decreases MS23’s estimates of the mitigatory impact of innovation exposure by at least 99.8%. None of these estimates are statistically significantly different from zero. 17/x


Maybe innovation is just more endogenous than weather patterns. So I pursue an IV strategy, instrumenting my direct innovation measures with LOO extreme heat exposure. Per MS23’s justifications, LOO extreme heat exposure should be a good exogenous instrument for innovation. 18/x
Thinking about this in an instrumental variables setting makes the proxy's problems intuitive. There's a clear exclusion restriction violation going on here. LOO extreme heat exposure impacts agricultural value not just through innovation, but also through extreme heat. 19/x
The instrument also ends up being pretty weak, with first-stage F-statistics all less than eight. Instrumental variables estimates for mitigatory impacts are somewhat more positive, but none are statistically significantly different from zero. 20/x


A few points on MS23's response. First, they claim that I ignore their rationales for the proxy. *A third of my paper* is dedicated to the section titled “Justifications for the Proxy”, which directly addresses MS23's empirical justifications from their paper and reply. 21/x

Second, MS23 claim that I exactly replicate their paper's results, that the replicability issues I find are minuscule (rounding errors in deep decimal places), and that my classification of the paper as 'partially replicable' is misleading. None of these claims are true. 22/x

The reason I maintain my 'partially replicable' classification is because of replicability problems for an important robustness check in the appendix, one that is supposed to address the exact concern that underpins my entire replication. 23/x
In Appendix Table A18, MS23 report mitigatory impact estimates after controlling for a square term in local extreme heat exposure. This is supposed to rule out my main critique, that MS23's mitigatory impact estimates capture nonlinear impacts of local extreme heat exposure. 24/x
There is no replication code for Appendix Table A18, and my best attempts to reproduce it yield mitigatory impact estimates that are up to 38.3% weaker than those in the published version of the table. 25/x

The published Appendix Table A18 implies that if anything, controlling for squared local extreme heat exposure *increases* estimates of innovation's mitigatory impacts. My replication of that table implies that this control actually *decreases* those estimates considerably. 26/x

I also find that the models in Appendix Table A18 are misspecified (see Section 3.1.4 of my paper for details). When this is corrected, controlling for squared local extreme heat exposure leaves most estimates of innovation's mitigatory impact not stat. sig. diff. from zero. 27/x

Third and finally, MS23 imply that my paper actually reaches the same conclusion as theirs: that innovation has a relatively weak mitigatory impact on agricultural damage from climate change. Our papers do not reach the same conclusion. 28/x

As I mentioned, MS23 conclude that market innovation has prevented about 20% of the potential agricultural damages of climate change since 1960. This is obviously a meaningfully large effect, and my main replication reduces this estimate by at least 99.8%. 29/x
MS23’s paper says: market innovation is useful for abating some climate change damage, but don’t trust it to abate *everything*. My paper says: don’t trust it to abate *anything*. The market won’t save us. We need collective action on climate change. 30/31
I will be submitting this replication report to @QJEHarvard, and will keep posted about the progress of that submission. The most recent version of the paper will be updated at . 31/31jack-fitzgerald.github.io/files/MS23_Rep…
@QJEHarvard Also, if you care enough about this issue to read this far, please consider donating to All Faiths Food Bank, a local charity in Sarasota, where Hurricane Milton made landfall.
allfaithsfoodbank.org
allfaithsfoodbank.org
@QJEHarvard @threadreaderapp unroll this
• • •
Missing some Tweet in this thread? You can try to
force a refresh









