This is a single uncut video, showing a robot learning several tasks instantly, after just one demonstration each ...
This is possible because we've now been able to achieve in-context learning for everyday robotics tasks, and I'm very excited to announce our latest paper:
🎆 Instant Policy: In-Context Imitation Learning via Graph Diffusion 🎆
robot-learning.uk/instant-policy
(1/6) 🧵👇
This is possible because we've now been able to achieve in-context learning for everyday robotics tasks, and I'm very excited to announce our latest paper:
🎆 Instant Policy: In-Context Imitation Learning via Graph Diffusion 🎆
robot-learning.uk/instant-policy
(1/6) 🧵👇
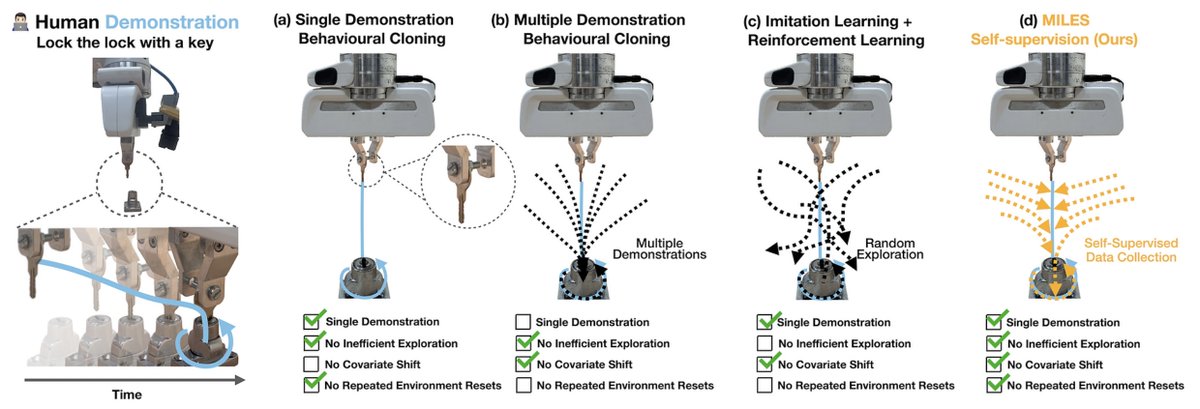
In-context learning is where a trained model accepts examples of a new task (the "context") at its input, and can then make predictions for that same task given a novel instance of it, without any further training or weight updates.
Achieving this in robotics is very exciting: with Instant Policy, we can now provide one or a few demonstrations (the "context"), and the robot instantly learns a closed-loop policy for that task, which it can then immediately perform.
(2/6)
Achieving this in robotics is very exciting: with Instant Policy, we can now provide one or a few demonstrations (the "context"), and the robot instantly learns a closed-loop policy for that task, which it can then immediately perform.
(2/6)
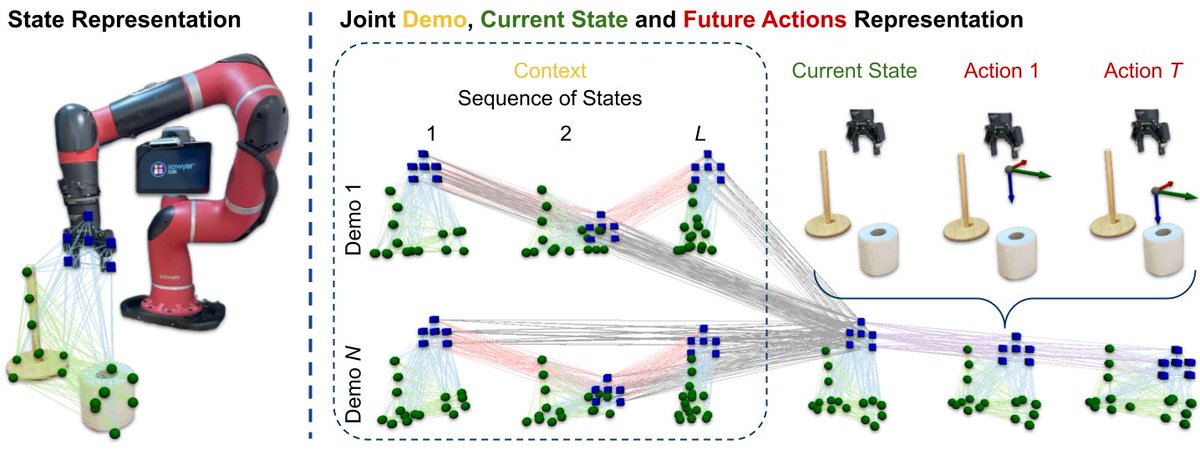
The figure below shows our network architecture, which jointly expresses the context (demonstrations, as sequences of observations and actions), the current observation, and the future actions. Observations are point clouds, and actions are relative gripper poses.
During inference, actions are predicted using a learned diffusion process on the graph nodes representing the actions, conditioned on the demonstrations and the current observation.
(3/6)
During inference, actions are predicted using a learned diffusion process on the graph nodes representing the actions, conditioned on the demonstrations and the current observation.
(3/6)
One very exciting aspect of Instant Policy is that we don't need any real-world training data. The entire network can be trained with simulated "pseudo-demonstrations", which are arbitrary trajectories with random objects, all in simulation.
And we found very promising scaling laws: we can continue to generate these pseudo-demonstrations in simulation, and the performance of the network continues to improve.
(4/6)
And we found very promising scaling laws: we can continue to generate these pseudo-demonstrations in simulation, and the performance of the network continues to improve.
(4/6)
Beyond just regular imitation learning, we also discovered two intriguing downstream applications:
(1) Cross-embodiment transfer from human-hand demonstrations to robot policies.
(2) Zero-shot transfer to language-defined tasks without needing large language-annotated datasets.
(5/6)
(1) Cross-embodiment transfer from human-hand demonstrations to robot policies.
(2) Zero-shot transfer to language-defined tasks without needing large language-annotated datasets.
(5/6)
This was led by my excellent student Vitalis Vosylius (@vitalisvos19), in the final project of his PhD.
To read the paper and see more videos, please visit robot-learning.uk/instant-policy.
And we have code and weights available on the webpage, for you to teach your own robot with Instant Policy. Please try it out, and let us know how you get on!
Thanks for reading 😀
(6/6)
To read the paper and see more videos, please visit robot-learning.uk/instant-policy.
And we have code and weights available on the webpage, for you to teach your own robot with Instant Policy. Please try it out, and let us know how you get on!
Thanks for reading 😀
(6/6)

• • •
Missing some Tweet in this thread? You can try to
force a refresh