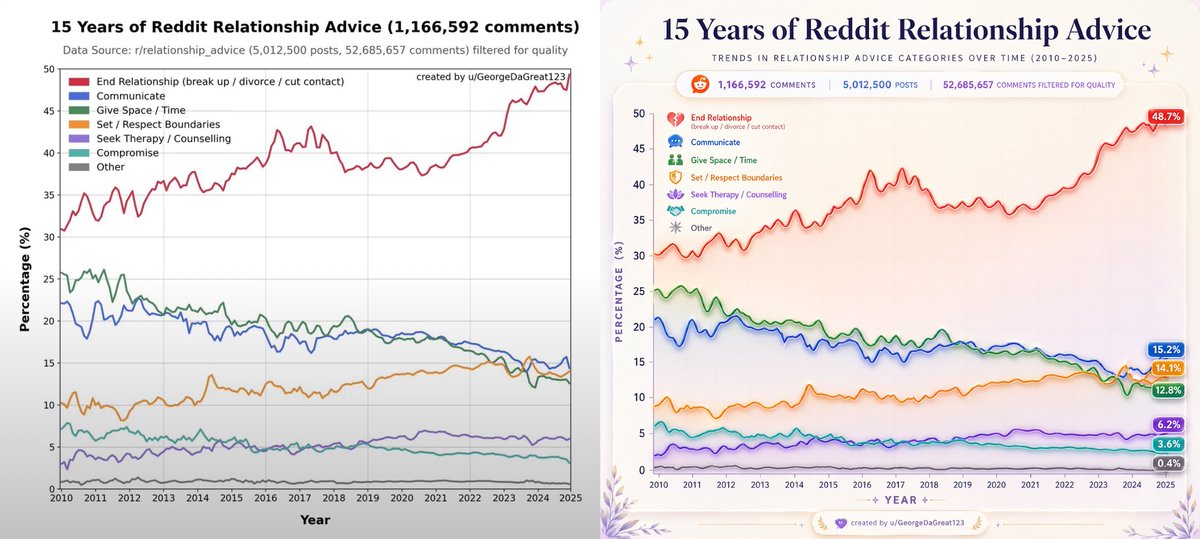
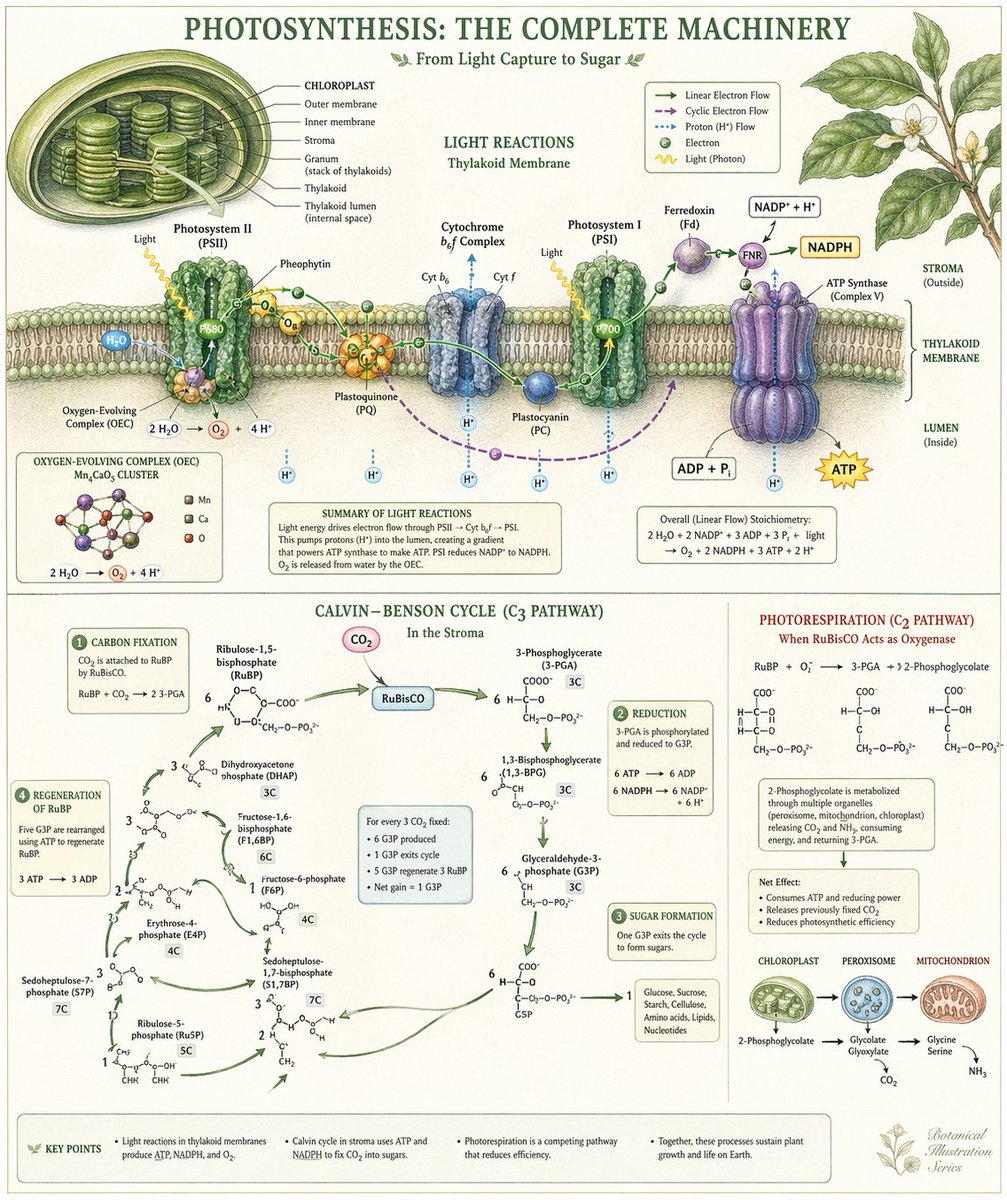
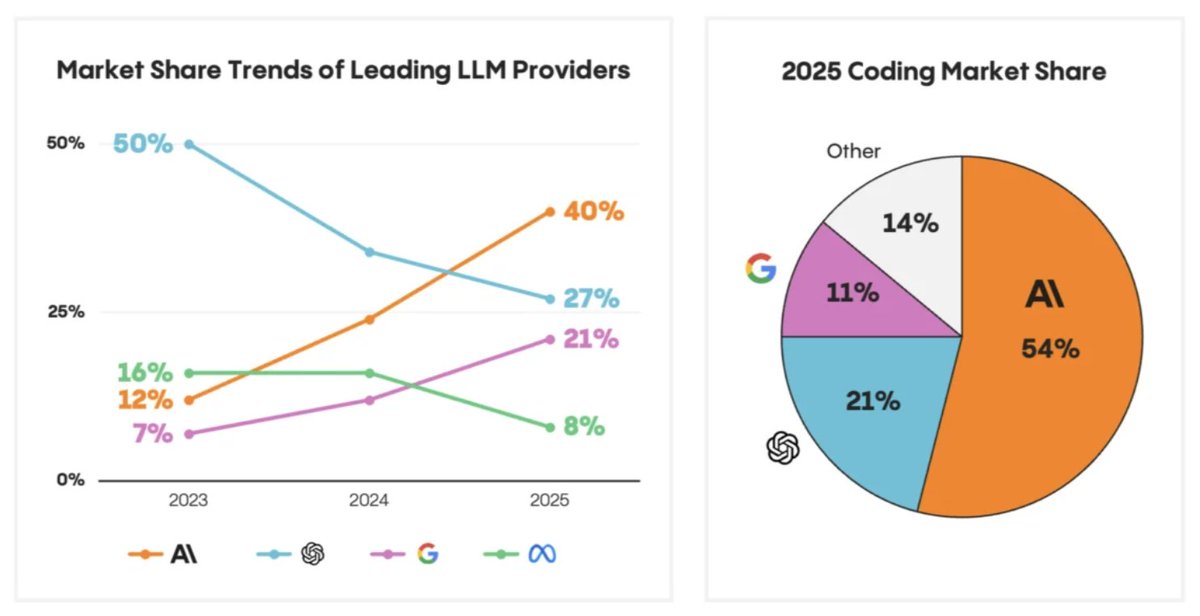
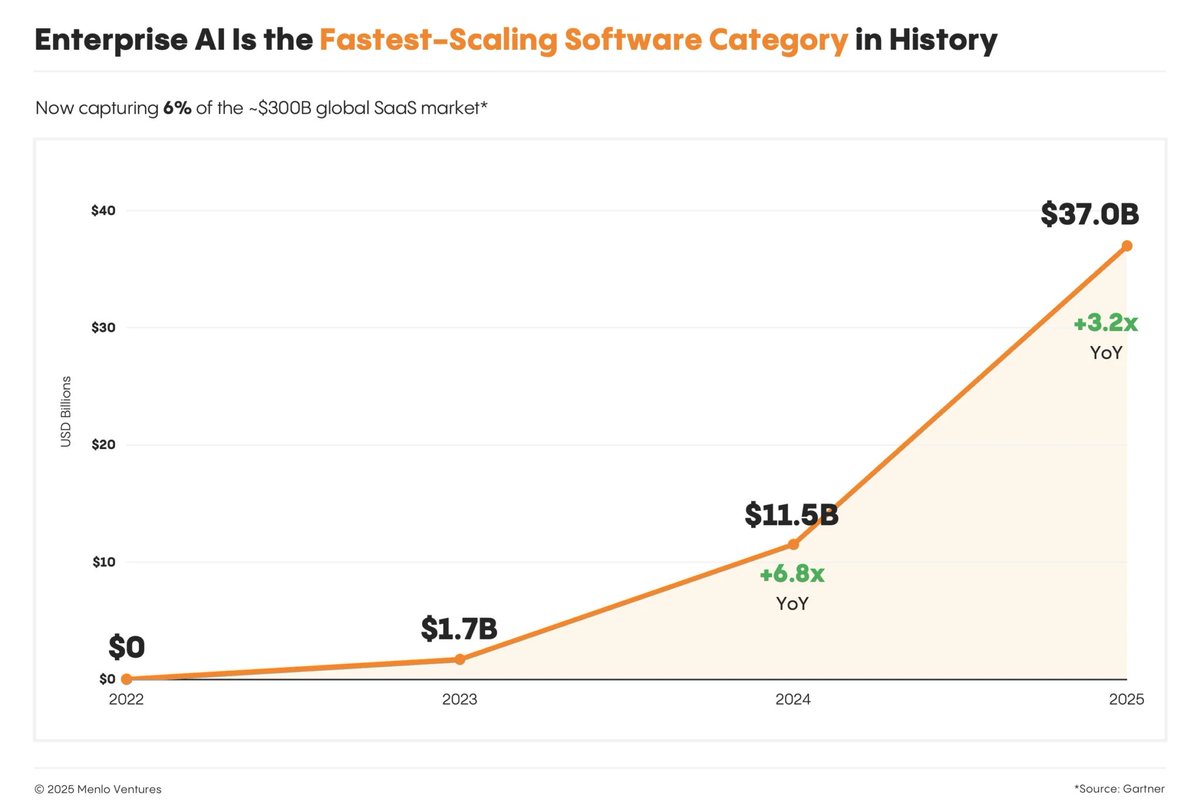
A single fairly unknown Dutch company makes maybe the most expensive and complex non-military device ($200M) that builds on 40 years of Physics and has a monopoly responsible for all AI advancement today.
Here's the story of ASML, the company powering Moore's Law..
1/9
Here's the story of ASML, the company powering Moore's Law..
1/9

ASML's extreme ultraviolet (EUV) machines are engineering marvels.
They shoot molten tin droplets 50,000x/s with a 25kW laser turning it into plasma as hot as the sun's surface to create 13.5nm UV light —so energetic it's absorbed by air itself.
2/9
They shoot molten tin droplets 50,000x/s with a 25kW laser turning it into plasma as hot as the sun's surface to create 13.5nm UV light —so energetic it's absorbed by air itself.
2/9
Each $200M machine contains mirrors that are the smoothest objects humans have ever created.
They're made with layers of molybdenum/silicon, each just a few atoms thick. If you scaled one to the size of Germany, its largest imperfection would be 1mm high.
3/9
They're made with layers of molybdenum/silicon, each just a few atoms thick. If you scaled one to the size of Germany, its largest imperfection would be 1mm high.
3/9
This light goes through the mirrors onto moving 300mm silicon wafers at highway speeds (~1m/s) with precision better than the width of a SINGLE SILICON ATOM (0.2nm).
That's like hitting a target in SF from NYC with the accuracy of a human hair.
4/9
That's like hitting a target in SF from NYC with the accuracy of a human hair.
4/9
TSMC's 4nm process for NVIDIA H100 needs ~15 EUV layers (+80 DUV layers).
Each layer must align within nanometers. One machine processes ~100 wafers/hr. Cost? About $150K of chips per hour.
Other techniques cannot get the quality + throughput + cost to this level.
5/9
Each layer must align within nanometers. One machine processes ~100 wafers/hr. Cost? About $150K of chips per hour.
Other techniques cannot get the quality + throughput + cost to this level.
5/9
Why monopoly?
The supplier network:
— Zeiss (optics)
— Trumpf (lasers)
— VDL (frames)
40 years of co-development, 40,000 patents, 700+ suppliers. They own 24.9% of Zeiss's semiconductor div.
Replication would take decades + $100B+.
6/9
The supplier network:
— Zeiss (optics)
— Trumpf (lasers)
— VDL (frames)
40 years of co-development, 40,000 patents, 700+ suppliers. They own 24.9% of Zeiss's semiconductor div.
Replication would take decades + $100B+.
6/9
The complexity is astounding.
Each machine ships in 40 containers and takes 4 months to install. The supply chain spans 700+ companies. 100K+ parts per machine, 40K patents protecting it.
One missing component = global semiconductor disruption.
7/9
Each machine ships in 40 containers and takes 4 months to install. The supply chain spans 700+ companies. 100K+ parts per machine, 40K patents protecting it.
One missing component = global semiconductor disruption.
7/9
Only three companies can run cutting-edge EUV:
— TSMC (that makes GPUs for Nvidia)
— Samsung
— Intel.
ASML machines are the only way to make chips dense enough for modern AI. Each H100 has 80B transistors. The next gen will need >100B.
Impossible without EUV.
8/9
— TSMC (that makes GPUs for Nvidia)
— Samsung
— Intel.
ASML machines are the only way to make chips dense enough for modern AI. Each H100 has 80B transistors. The next gen will need >100B.
Impossible without EUV.
8/9
Rich Sutton's "The Bitter Lesson" is that general methods that leverage
computation and Moore's Law are the most effective for advancing AI research.
In the iceberg of AI technology, while LLMs are at the top, ASML is at the murky depths.
It has kept Moore's Law alive.
9/9
computation and Moore's Law are the most effective for advancing AI research.
In the iceberg of AI technology, while LLMs are at the top, ASML is at the murky depths.
It has kept Moore's Law alive.
9/9
• • •
Missing some Tweet in this thread? You can try to
force a refresh