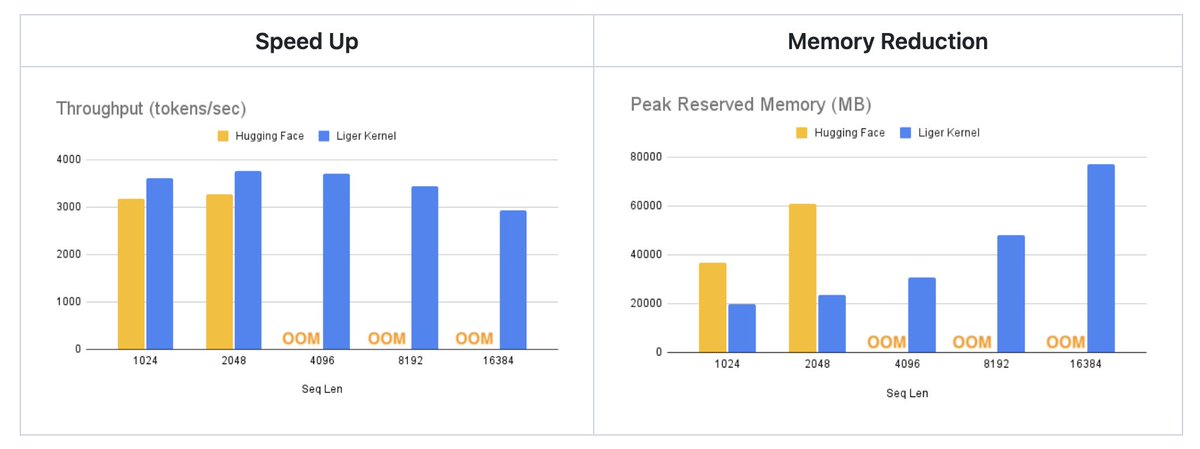
Introducing the first open-source optimized post-training losses in Liger Kernel with ~80% memory reduction, featuring DPO (@rm_rafailov), CPO (@fe1ixxu), ORPO (@jiwoohong98), SimPO (@yumeng0818), JSD, and more, achieving up to 70% end-to-end speedup through larger batch size. Use it as any PyTorch module - Available today in Liger v0.5.0!
github.com/linkedin/Liger…
github.com/linkedin/Liger…

(2/N) Installation and usage are simple. Just pip install liger-kernel and import the loss as a PyTorch module to benefit from significant memory reduction.

(3/N) The core challenge is that LLMs' vocab sizes are massive, and losses like DPO or JSD need to materialize multiple copies of the logits, causing memory issues. We applied the same idea from our popular fused linear cross entropy to other losses.
(4/N) For all losses, hidden inputs are fed into the lm head then the loss function. We avoid materializing full logits by chunking hidden inputs and fusing forward and backward passes. Memory can be reduced by up to 80% since the memory peak is only the size of a small chunk!
(5/N) Rather than writing custom triton kernels, we generate kernels using torch compile. We achieve amazing performance by using grad_and_value to run forward and backward in one call, using a for loop to accumulate gradients, and torch compiling the full code.

(6/N) Torch compile streamlines kernel execution and fuses operations, but recompilation can add overhead. We found setting variable-length inputs as dynamic with torch._dynamo.mark_dynamic minimizes unnecessary recompilations and ensures consistent performance.
(7/N) We made the interface easy to extend with pure pytorch: github.com/linkedin/Liger…. Researchers can easily innovate custom losses on top of our flexible chunk loss implementation with superior performance. Please follow our official account and see the full release note of v0.5: x.com/liger_kernel/s…
(8/N) This work has been led by @shivam15sahni and @hsu_byron. Special thanks to @cHHillee for developing the Torch Compile Chunk Loss, and to Pramodith (github.com/pramodith) and Austin (github.com/austin362667), both of whom are active open source contributors. We’ve implemented the LigerORPOTrainer on top of the Hugging Face Trainer and are looking forward to deeper integration with training frameworks!
• • •
Missing some Tweet in this thread? You can try to
force a refresh