
 (2/N) Installation and usage are simple. Just pip install liger-kernel and import the loss as a PyTorch module to benefit from significant memory reduction.
(2/N) Installation and usage are simple. Just pip install liger-kernel and import the loss as a PyTorch module to benefit from significant memory reduction. 
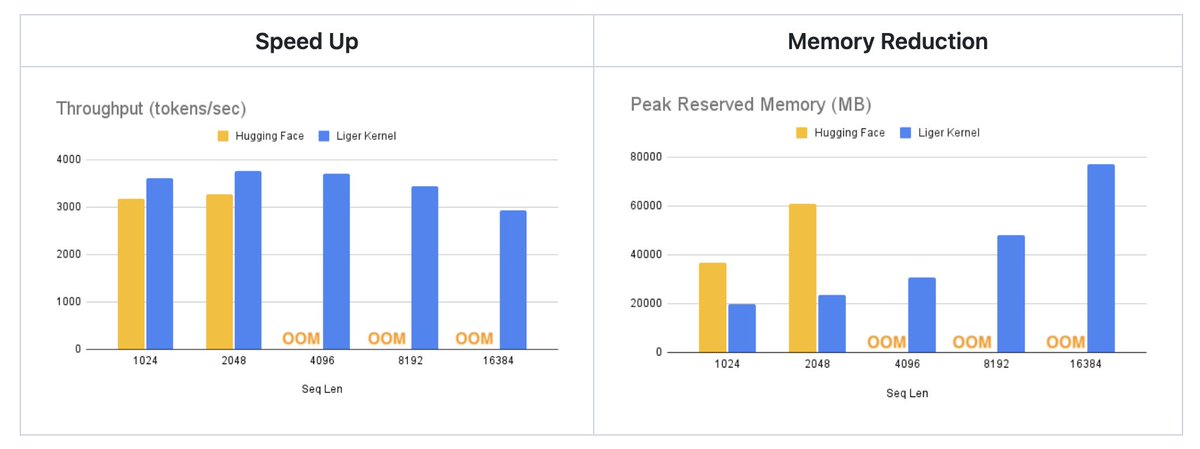 (2/n) Our kernel integrates smoothly with Flash Attention, PyTorch FSDP, and DeepSpeed. Patch your Hugging Face model with one line, or compose your own model using the provided kernels. These kernels have minimal dependencies—just Torch and Triton.
(2/n) Our kernel integrates smoothly with Flash Attention, PyTorch FSDP, and DeepSpeed. Patch your Hugging Face model with one line, or compose your own model using the provided kernels. These kernels have minimal dependencies—just Torch and Triton.