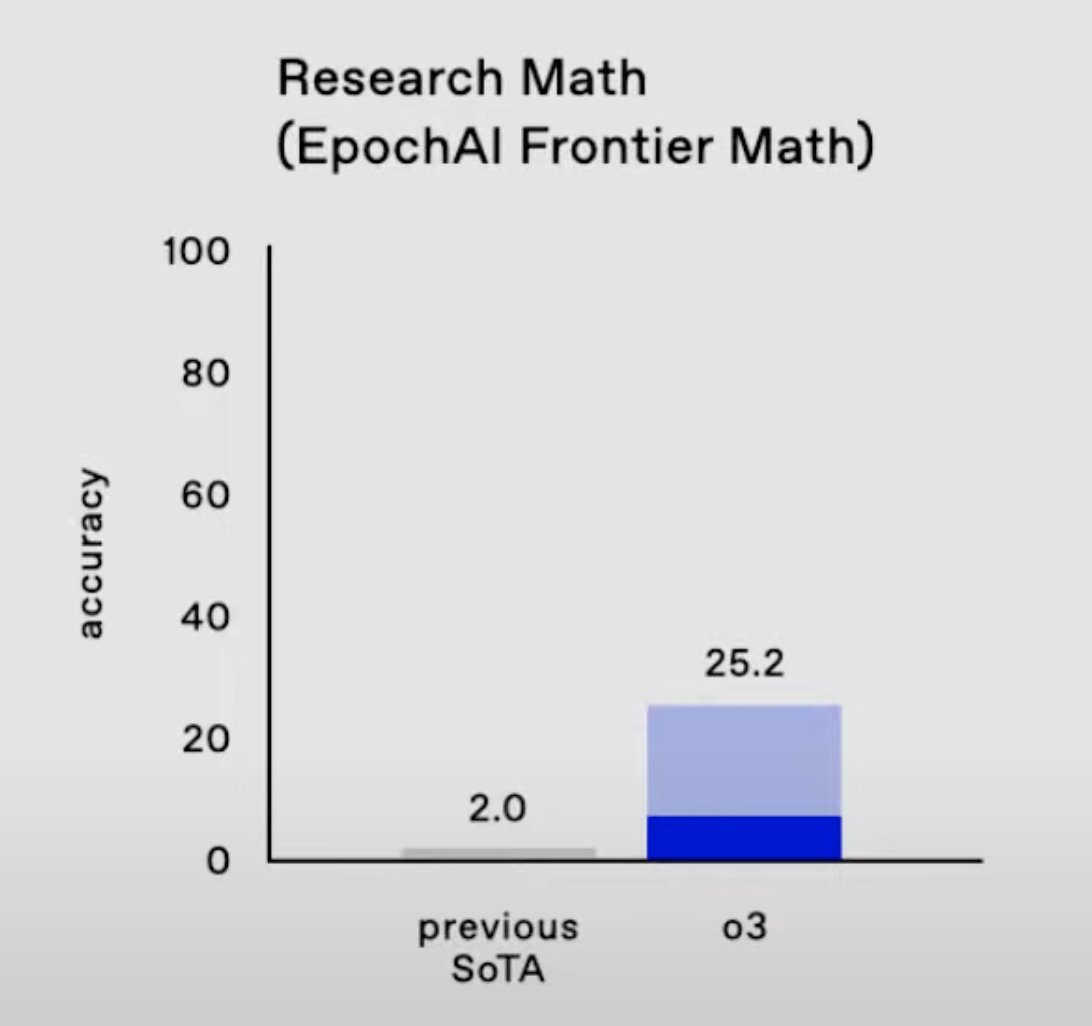
1/11 I’m genuinely impressed by OpenAI’s 25.2% Pass@1 performance on FrontierMath—this marks a major leap from prior results and arrives about a year ahead of my median expectations. 
2/11 For context, FrontierMath is a brutally difficult benchmark with problems that would stump many mathematicians. The easier problems are as hard as IMO/Putnam; the hardest ones approach research-level complexity.
https://x.com/MatthewJBar/status/1855406568717664760
3/11 With earlier models like o1-preview, Pass@1 performance (solving on first attempt) was only around 2%. When allowing 8 attempts per problem (Pass@8) and counting problems solved at least once, we saw ~6% performance. o3's 25.2% at Pass@1 is substantially more impressive.
4/11 It’s important to note that while the average problem difficulty is extremely high, FrontierMath problems vary in difficulty.
Roughly: 25% are Tier 1 (advanced IMO/Putnam level), 50% are Tier 2 (extremely challenging grad-level), and 25% are Tier 3 (research problems).
Roughly: 25% are Tier 1 (advanced IMO/Putnam level), 50% are Tier 2 (extremely challenging grad-level), and 25% are Tier 3 (research problems).
5/11 Even Tier 1 and 2 problems can take hours for experts to solve. Tier 3 problems are what Tao and Gowers called "exceptionally hard," often requiring days of effort from top mathematicians.
6/11 Because of this range in difficulty, it’s too soon to say o3 excels at the hardest research-level tasks. It’s likely solving some Tier 3 problems, but I suspect its average performance on them remains fairly low.
7/11 How do they claim 25.2% was achieved? During the release, they said they used “test time settings”.
For o1, which reported results with similar solid/shaded bars that, they used majority vote (consensus) with 64 samples.
For o1, which reported results with similar solid/shaded bars that, they used majority vote (consensus) with 64 samples.


8/11 For ARC-AGI, OpenAI scaled to tens of dollars to a few thousands per task.
If they applied similar scaling to FrontierMath, this would represent inference scaling of 2-3 OOMs above baseline.
If they applied similar scaling to FrontierMath, this would represent inference scaling of 2-3 OOMs above baseline.

9/11 This is notable because our earlier tests showed only a few percentage points performance gained per OOM. o3's increase to 25% suggests both improved per-token reasoning and better scaling behavior.
10/11 I previously predicted a 25% performance by Dec 31, 2025 (my median forecast with an 80% CI of 14–60%). o3 has reached it earlier than I'd have expected on average.
https://x.com/tamaybes/status/1870256365350072794
11/11 Still, 25% means it’s not close to “solving” FrontierMath (e.g. >80% performance). Yet, I find o3’s performance genuinely impressive.
While it's not yet conquering the whole benchmark, I don't expect that to take more than a year or two.
While it's not yet conquering the whole benchmark, I don't expect that to take more than a year or two.
12/11 We’ll certainly need even stronger benchmarks going forward. If our hardest research problems are “Tier 3,” maybe it’s time for a “Tier 4"?
• • •
Missing some Tweet in this thread? You can try to
force a refresh