
 The idea is to define the ‘time horizon’ a human club player needs to match AI moves. Early AIs were easy to outplay quickly, but as you go up to 2400 ELO engines, you need more thinking time—and matching Stockfish might take years per move!
The idea is to define the ‘time horizon’ a human club player needs to match AI moves. Early AIs were easy to outplay quickly, but as you go up to 2400 ELO engines, you need more thinking time—and matching Stockfish might take years per move! 
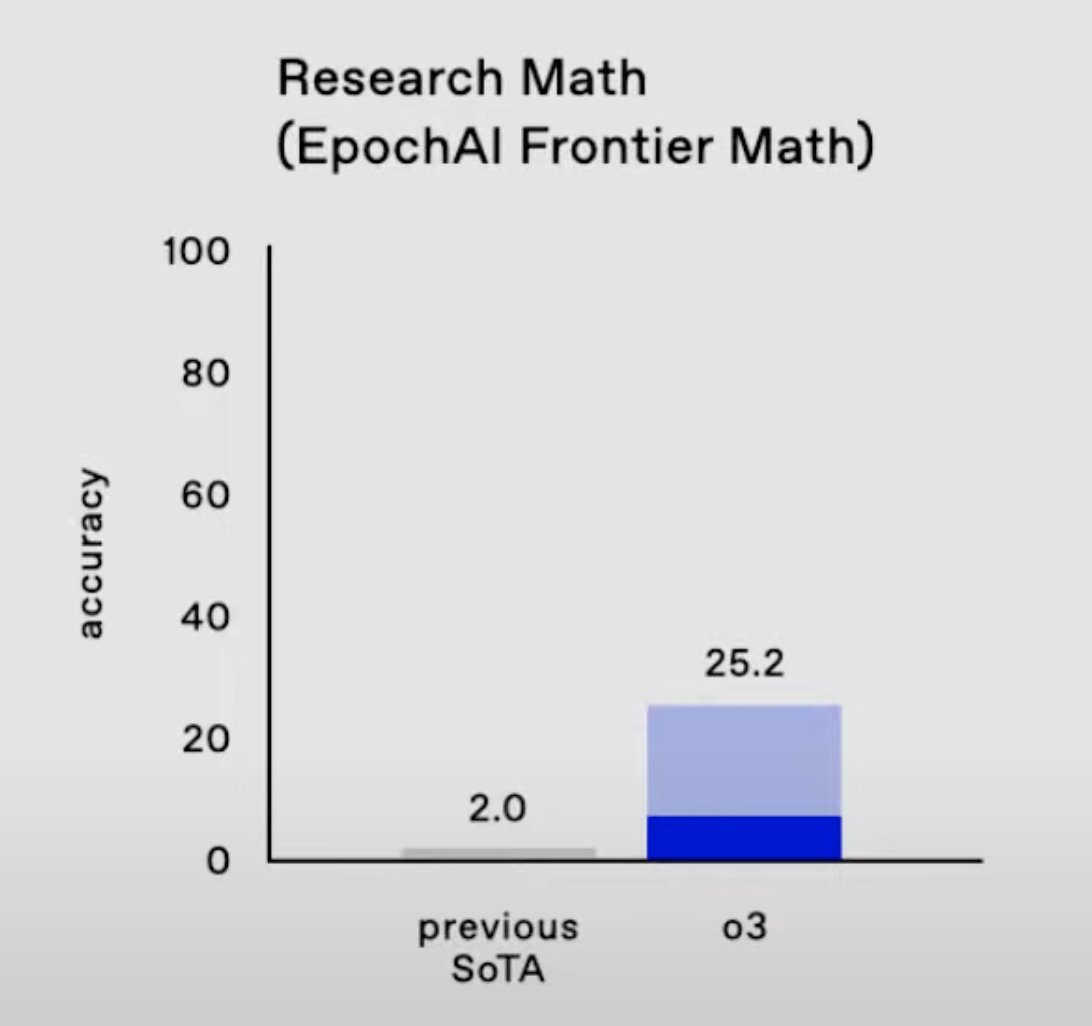 2/11 For context, FrontierMath is a brutally difficult benchmark with problems that would stump many mathematicians. The easier problems are as hard as IMO/Putnam; the hardest ones approach research-level complexity.
2/11 For context, FrontierMath is a brutally difficult benchmark with problems that would stump many mathematicians. The easier problems are as hard as IMO/Putnam; the hardest ones approach research-level complexity.
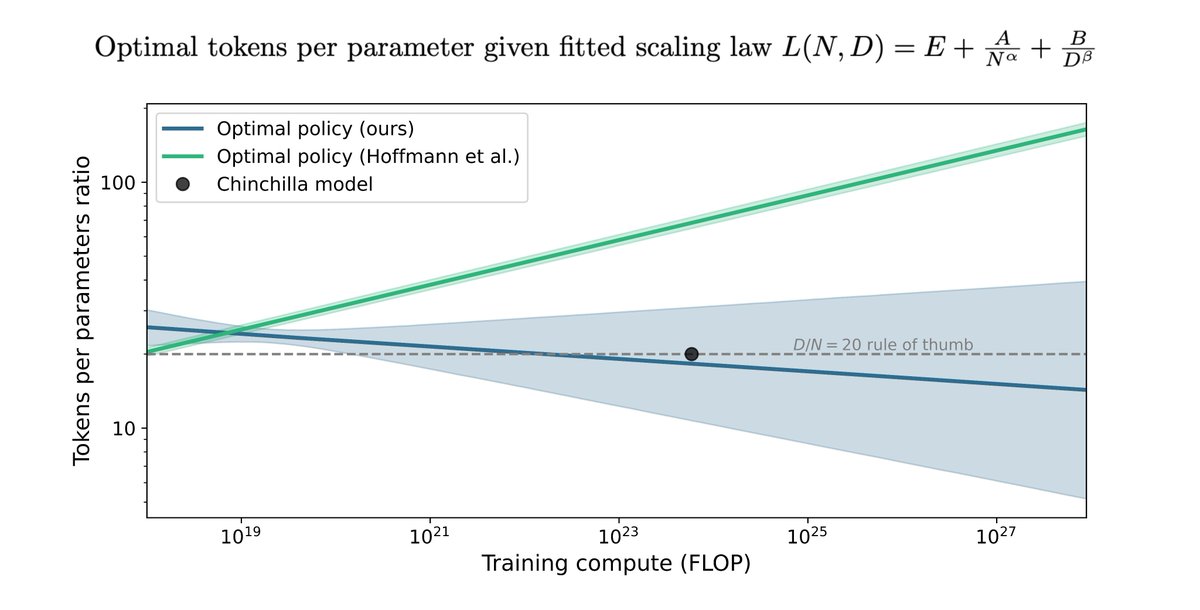 We reconstructed the data by extracting the SVG from the paper, parsing out the point locations & colors, mapping the coordinates to model size & FLOP, and mapping the colors to loss values. This let us closely approximate their original dataset from just the figure. (2/9)
We reconstructed the data by extracting the SVG from the paper, parsing out the point locations & colors, mapping the coordinates to model size & FLOP, and mapping the colors to loss values. This let us closely approximate their original dataset from just the figure. (2/9) 
 This rate of algorithmic progress is much faster than the two-year doubling time of Moore's Law for hardware improvements, and faster than other domains of software, like SAT-solvers, linear programs, etc. (2/10)
This rate of algorithmic progress is much faster than the two-year doubling time of Moore's Law for hardware improvements, and faster than other domains of software, like SAT-solvers, linear programs, etc. (2/10) 


 1840s—70s: Key manufacturing innovations occur (pneumatic process for cheap steel and sewing machine are invented); Transport (improvements in steam-engines. The Bollman bridge, air brake system, cable car are patented); Consumer Goods (board game, toothbrush, picture machine).
1840s—70s: Key manufacturing innovations occur (pneumatic process for cheap steel and sewing machine are invented); Transport (improvements in steam-engines. The Bollman bridge, air brake system, cable car are patented); Consumer Goods (board game, toothbrush, picture machine).
