Some notes on the DeepSeek-V3 Technical Report :)
The most insane thing to me:
The whole training only cost $5.576 million or ~55 days on a 2048xH800 cluster. This is TINY compared to the Llama, GPT or Claude training runs.
- 671B MoE with 37B activate params
- DeepSeek MoE architecture: 1 shared expert and 256 routed experts, 8 active routed experts for each token
- Multi-head Latent Attention (low-rank joint compression for attention keys and values)
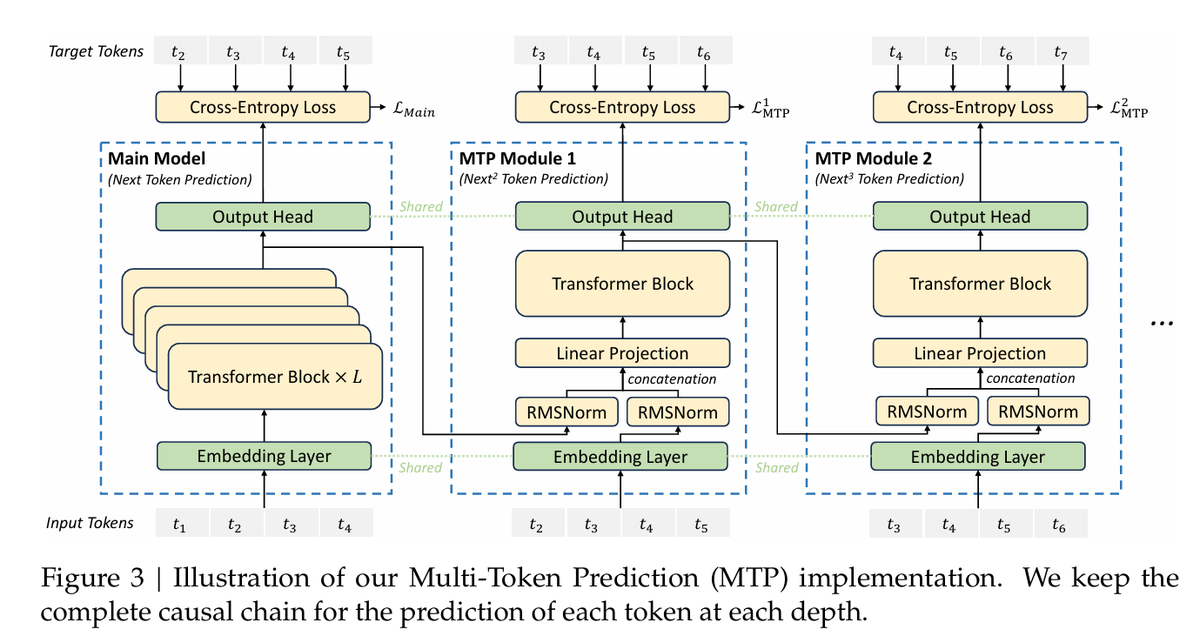
- Multi-token prediction (useful for spec decoding and better usage of training data) - for D additional tokens you want to predict there are D additional sequential modules
- some ablation study results for MTP:
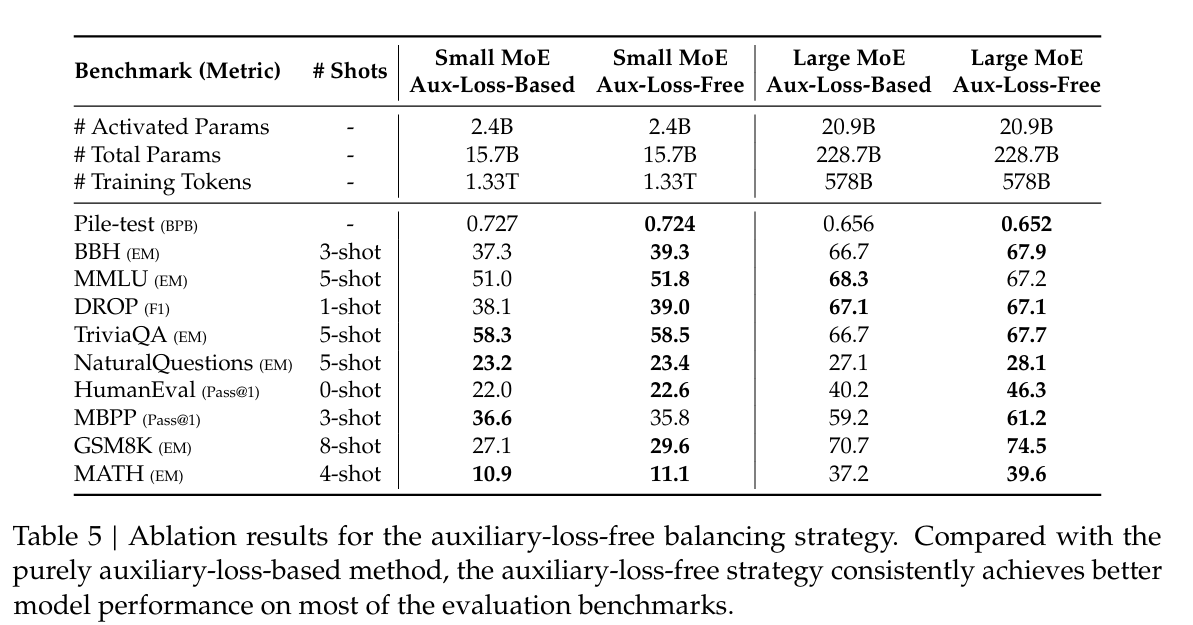
- auxiliary-loss-free load-balancing to prevent MoE collapse; ablation study below:
- 14.8T training tokens
- BPE tokenizer 128k vocab
- only 61 layers :(
- 2.788M H800 training hours with FP8 mixed precision
- pre-training --> two stage context length expansion, first to 32k tokens and then to 128k tokens
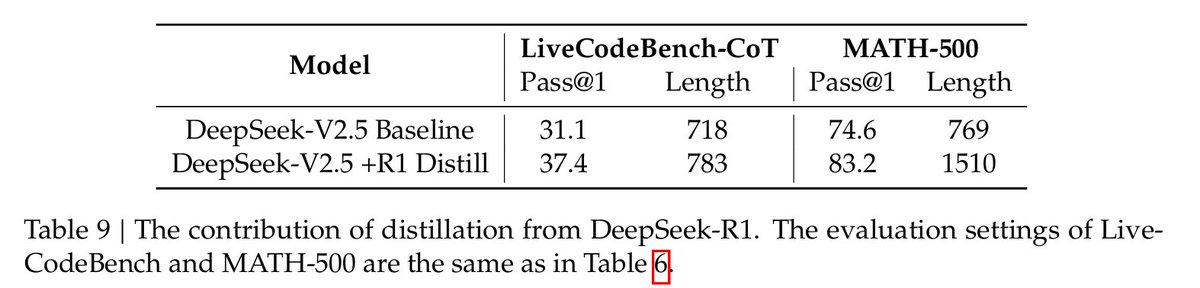
--> post-training uses SFT and RL to align with human preferences and for distilling R1 reasoning capabilities
- a bunch of interesting stuff on the infrastructure, and how they got the FP8 training to work (I don't really care about that), but worth reading if you are into that
The most insane thing to me:
The whole training only cost $5.576 million or ~55 days on a 2048xH800 cluster. This is TINY compared to the Llama, GPT or Claude training runs.
- 671B MoE with 37B activate params
- DeepSeek MoE architecture: 1 shared expert and 256 routed experts, 8 active routed experts for each token
- Multi-head Latent Attention (low-rank joint compression for attention keys and values)
- Multi-token prediction (useful for spec decoding and better usage of training data) - for D additional tokens you want to predict there are D additional sequential modules
- some ablation study results for MTP:
- auxiliary-loss-free load-balancing to prevent MoE collapse; ablation study below:
- 14.8T training tokens
- BPE tokenizer 128k vocab
- only 61 layers :(
- 2.788M H800 training hours with FP8 mixed precision
- pre-training --> two stage context length expansion, first to 32k tokens and then to 128k tokens
--> post-training uses SFT and RL to align with human preferences and for distilling R1 reasoning capabilities
- a bunch of interesting stuff on the infrastructure, and how they got the FP8 training to work (I don't really care about that), but worth reading if you are into that

• • •
Missing some Tweet in this thread? You can try to
force a refresh