
lead them to paradise
LisanBench: https://t.co/vorVk7NMCy
Impressum & Datenschutz: https://t.co/lFLgiu8EAU








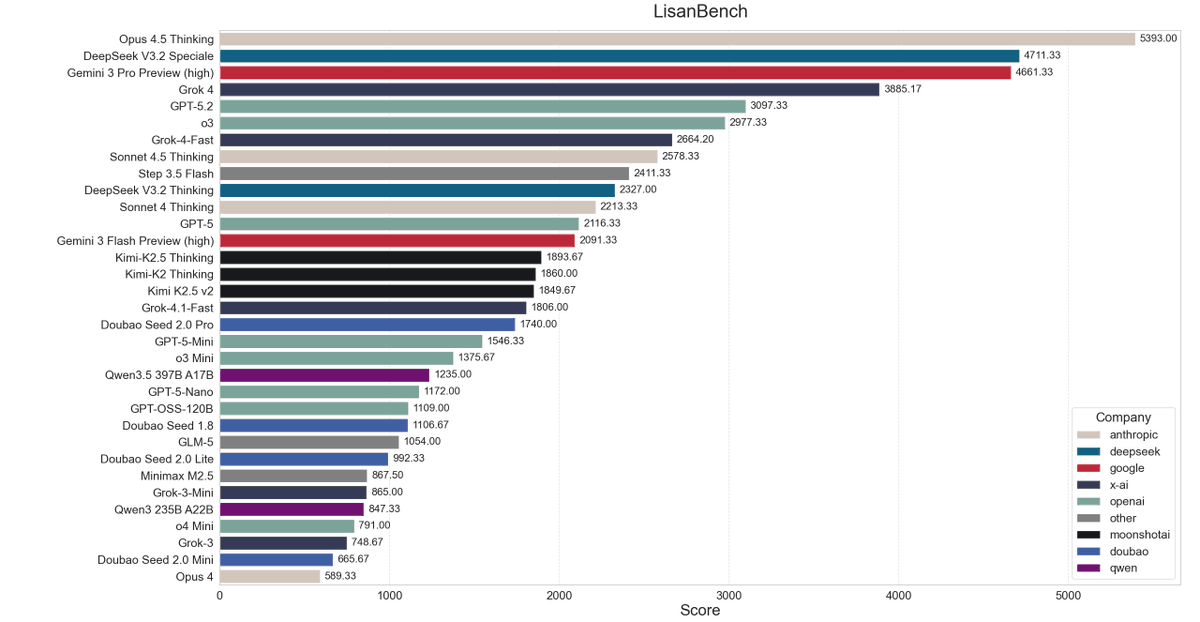
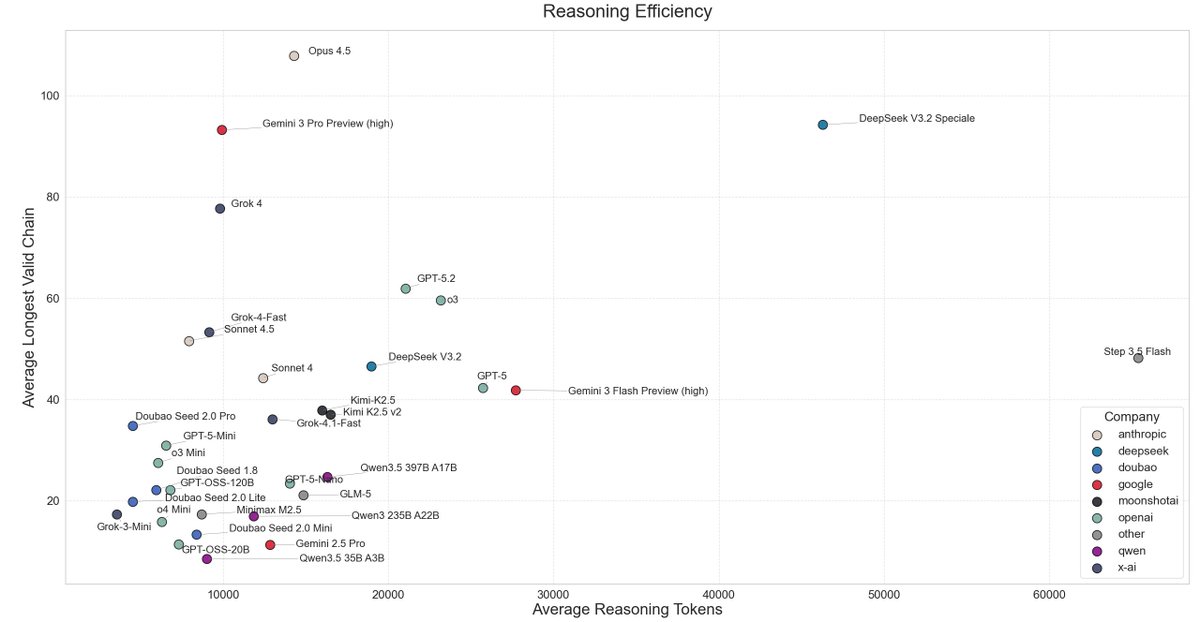
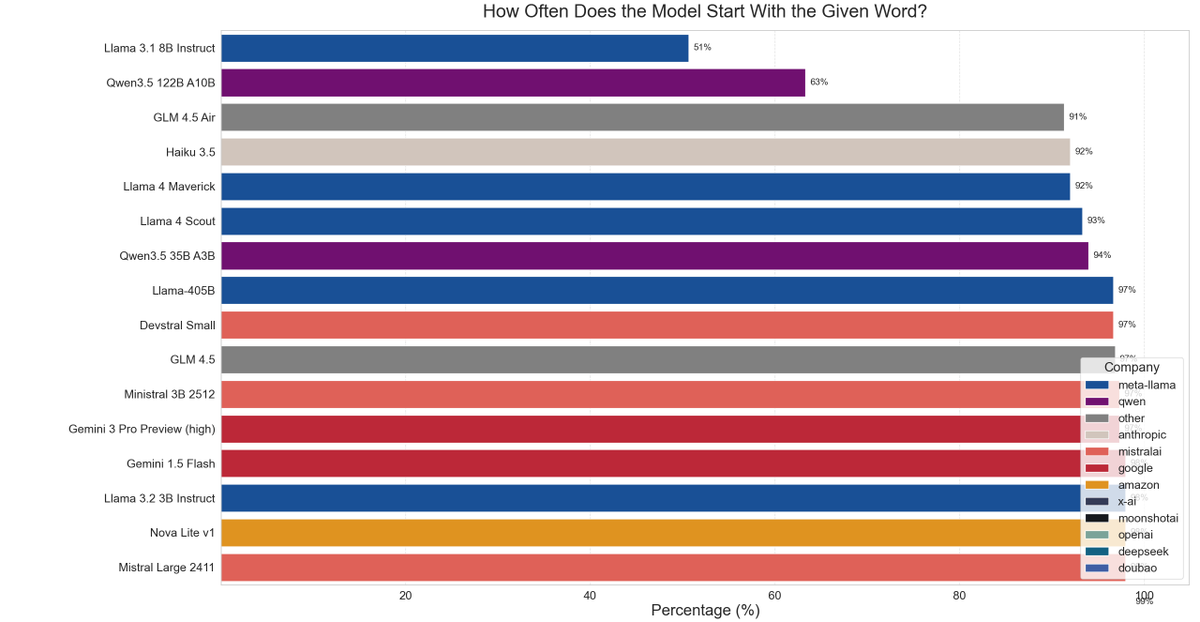 I had to run Kimi-K2.5 twice, because last time I tested LisanBench with Qwen3 I had to add a /nothink tag, that I then forgot.
I had to run Kimi-K2.5 twice, because last time I tested LisanBench with Qwen3 I had to add a /nothink tag, that I then forgot.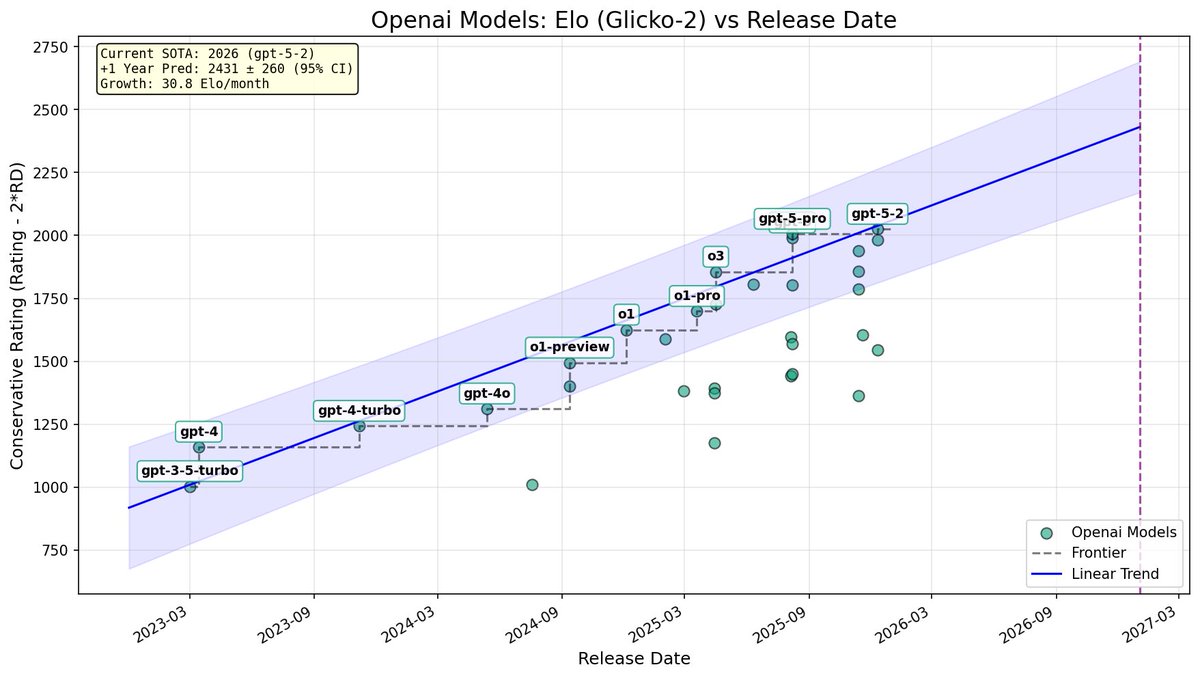
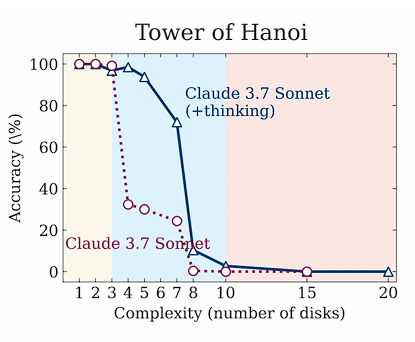
 Decomposing helps the model to focus more on reasoning as it keeps the problem size smaller but it will basically get lost in the algorithm and repeat steps.
Decomposing helps the model to focus more on reasoning as it keeps the problem size smaller but it will basically get lost in the algorithm and repeat steps.




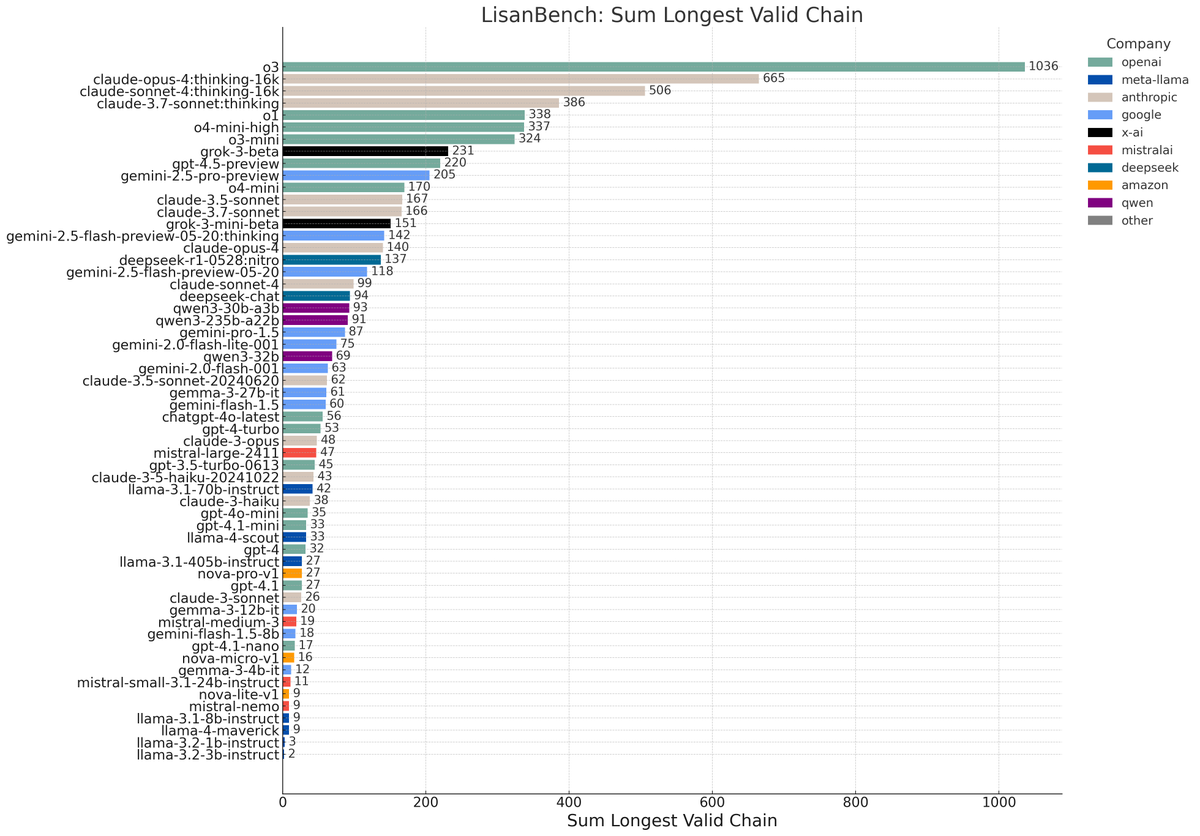
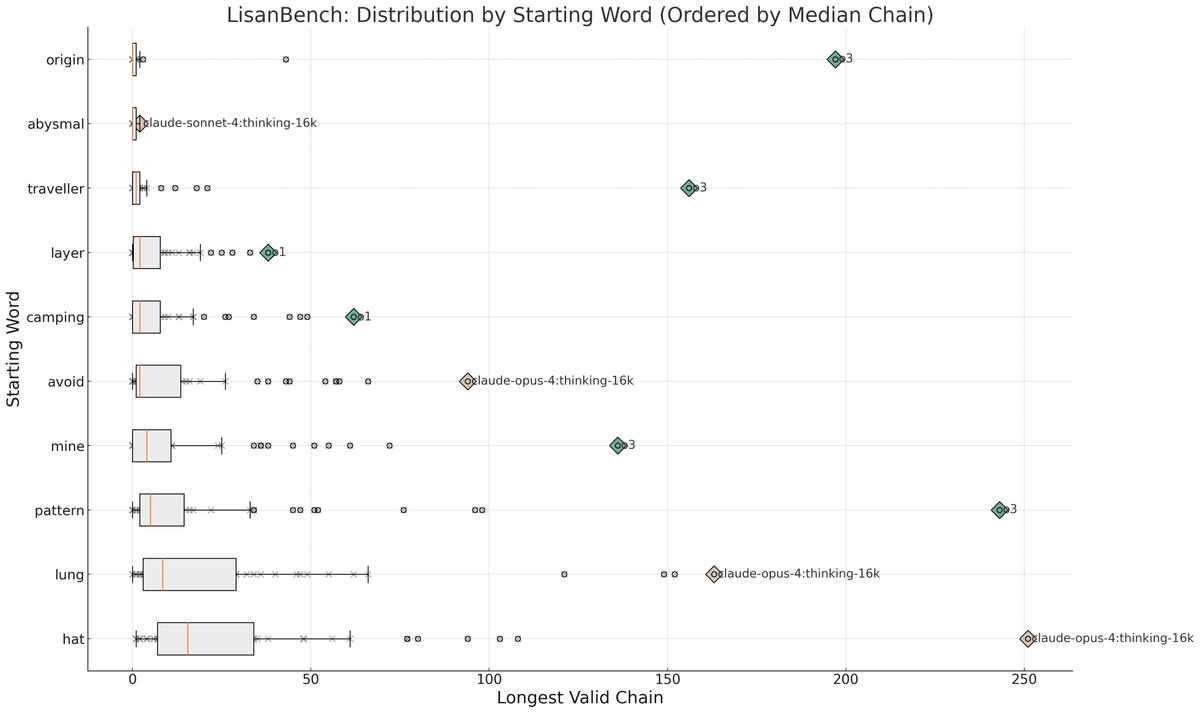 Full Leaderboard:
Full Leaderboard: 
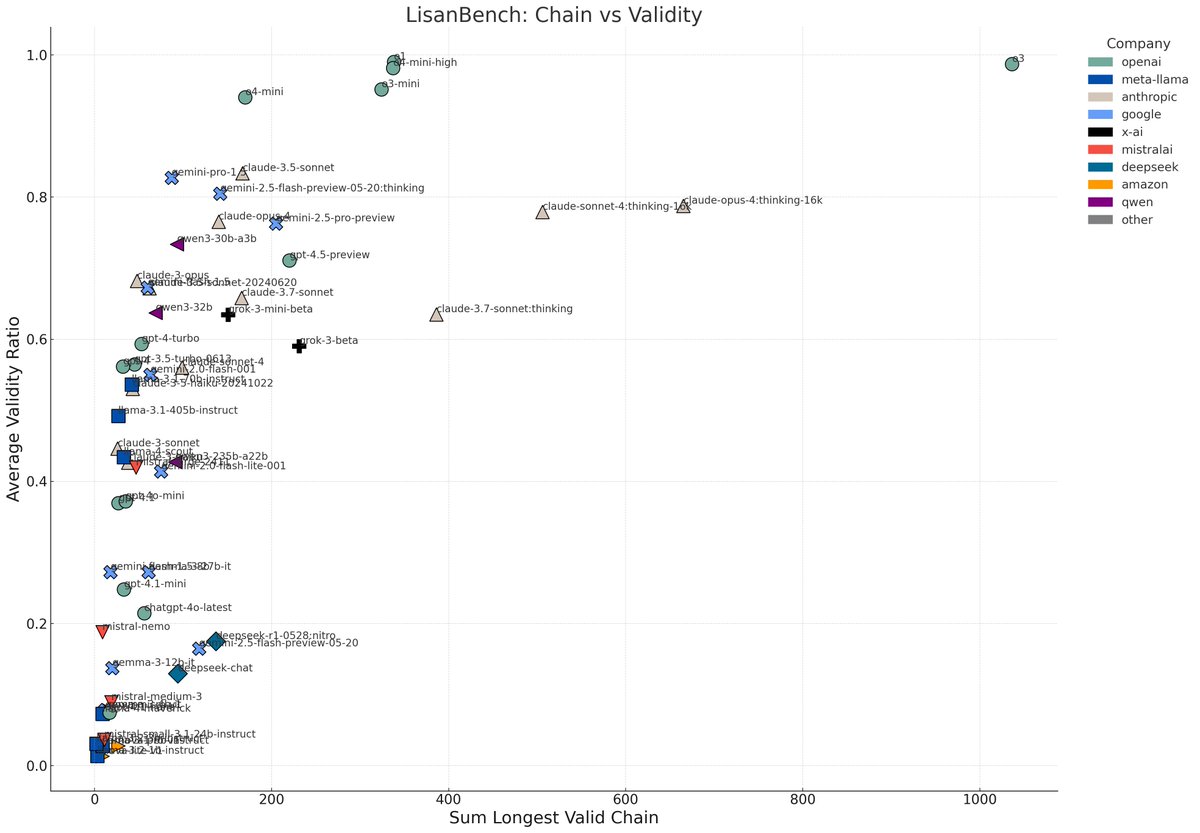
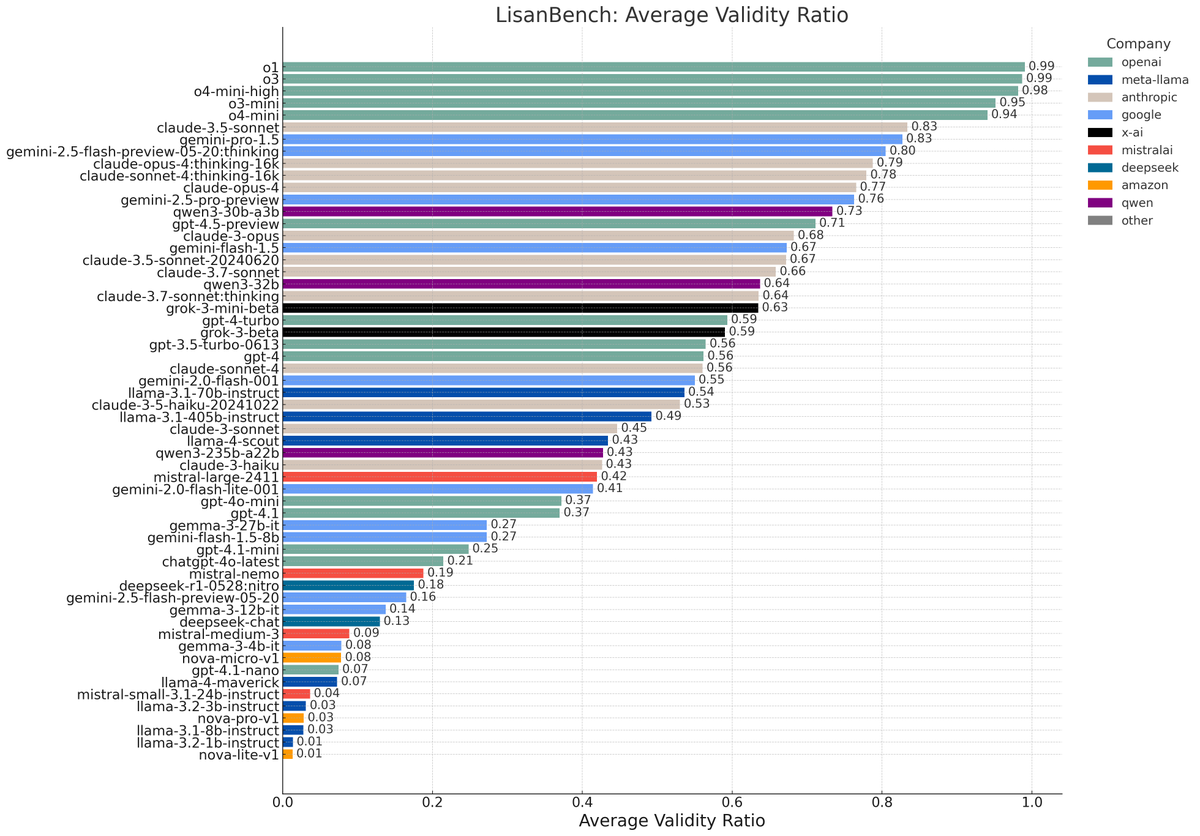
 GPT-4.5 Research Engineer Interviews
GPT-4.5 Research Engineer Interviews 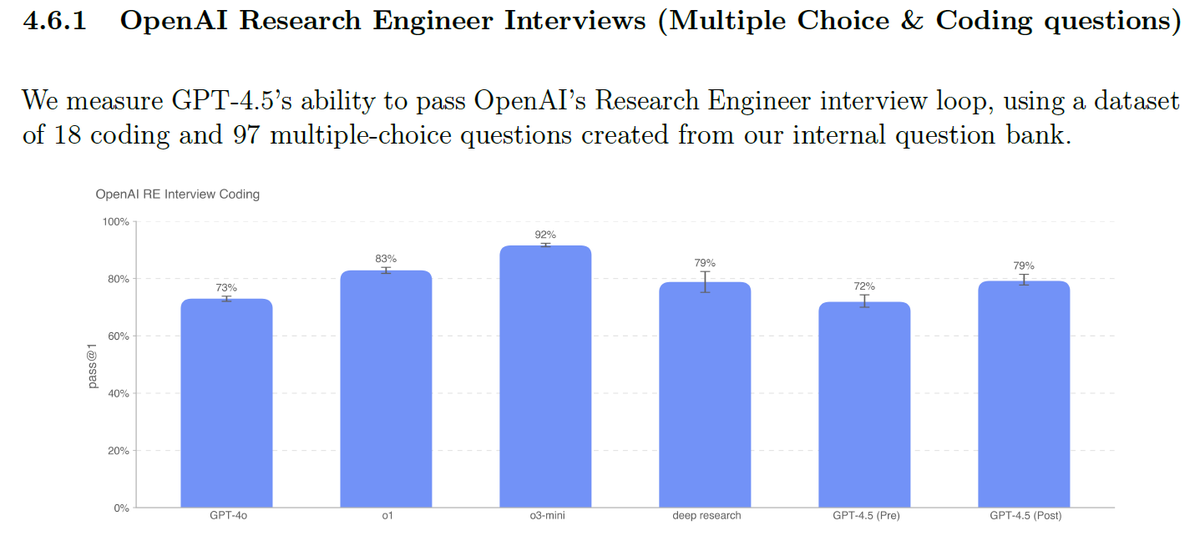


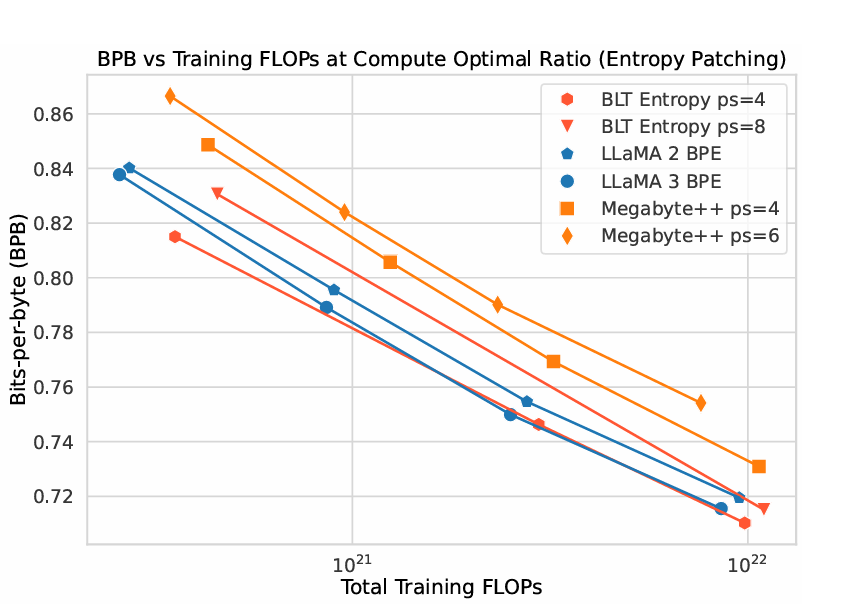
 Paper Link: ai.meta.com/research/publi…
Paper Link: ai.meta.com/research/publi…