1/6 We haven't communicated clearly enough about FrontierMath's relationship with OpenAI, and I want to own that. By not being transparent from the start, we caused confusion for contributors, researchers, and the public.
2/6 OpenAI commissioned Epoch AI to produce 300 math problems for FrontierMath. Because it was a commissioned project, OpenAI owns those problems. They have access to the statements and solutions—except for a 50-question holdout set we're finalizing.
3/6 Epoch AI is free to conduct and publish evaluations of any models using the benchmark, as we have done already. We retain this right to evaluate models independently.
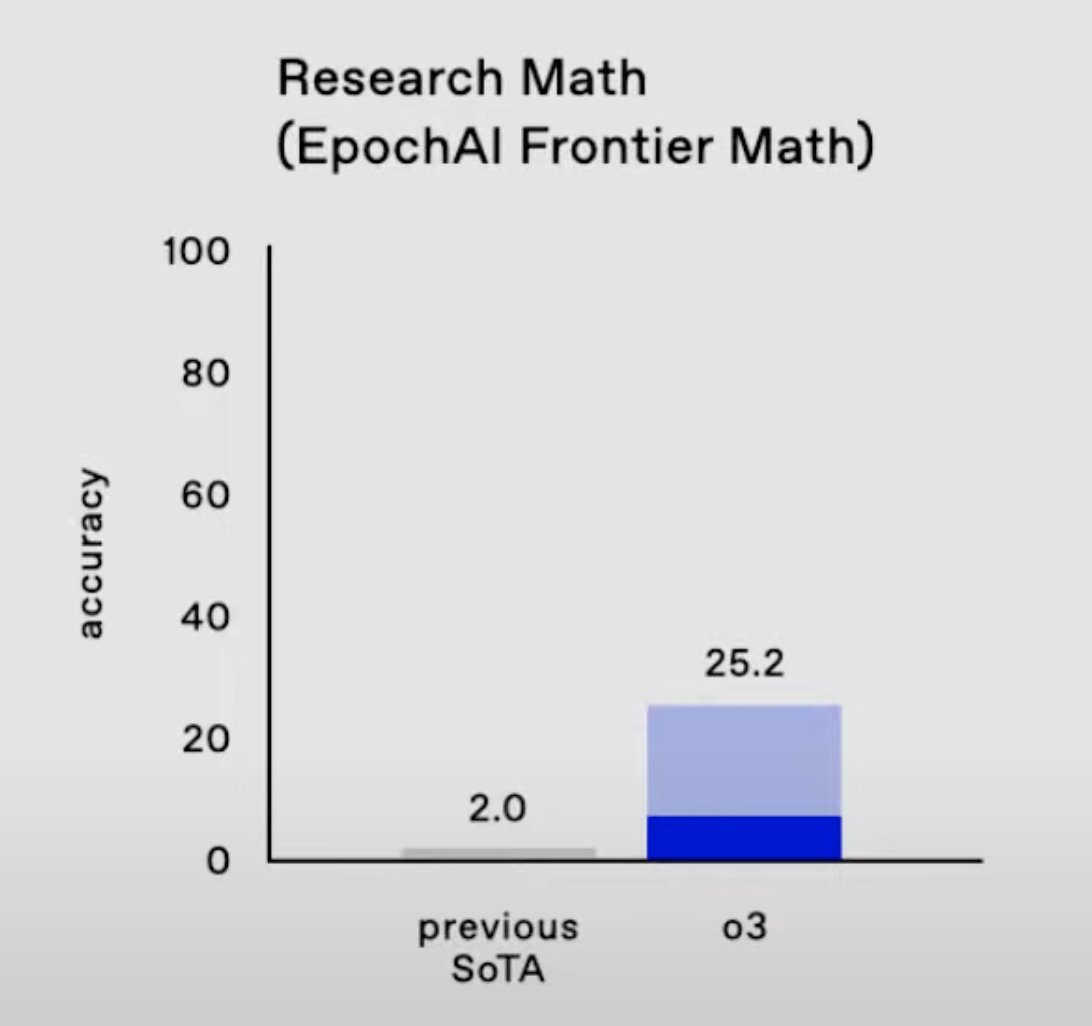
4/6 While we announced OpenAI's support before the o3 model launch in December, we didn't clearly communicate their data access and ownership agreements. We also failed to systematically inform contributors about industry sponsorship. That was a miss on our side.
5/6 This was our first project of this scale, involving nearly 100 contractors and complex agreements. Our lack of experience led to communication failures, particularly around industry sponsorship and data access agreements.
6/6 Going forward, we’ll proactively disclose industry sponsorship and data access agreements, and make sure contributors have that info up front. We can and will do better on transparency. More details in our blog post: epoch.ai/blog/openai-an…
And I appreciate Nat's clarity here. I do trust OpenAI's use of it is appropriate as a benchmark (not training on it, or otherwise targeting for it)
https://x.com/__nmca__/status/1882563758788358396
• • •
Missing some Tweet in this thread? You can try to
force a refresh