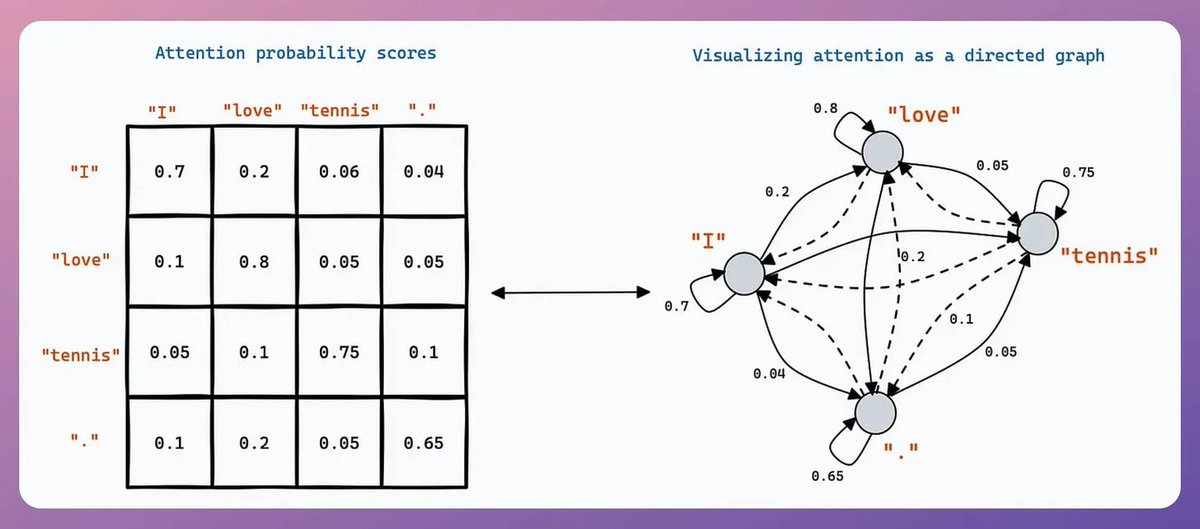
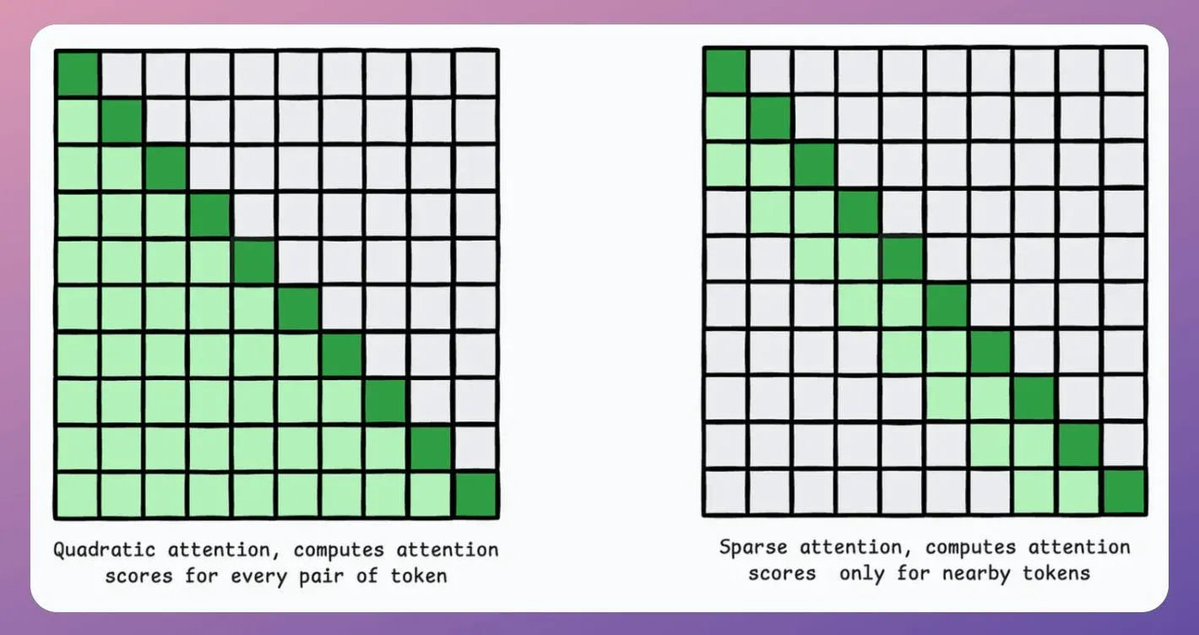
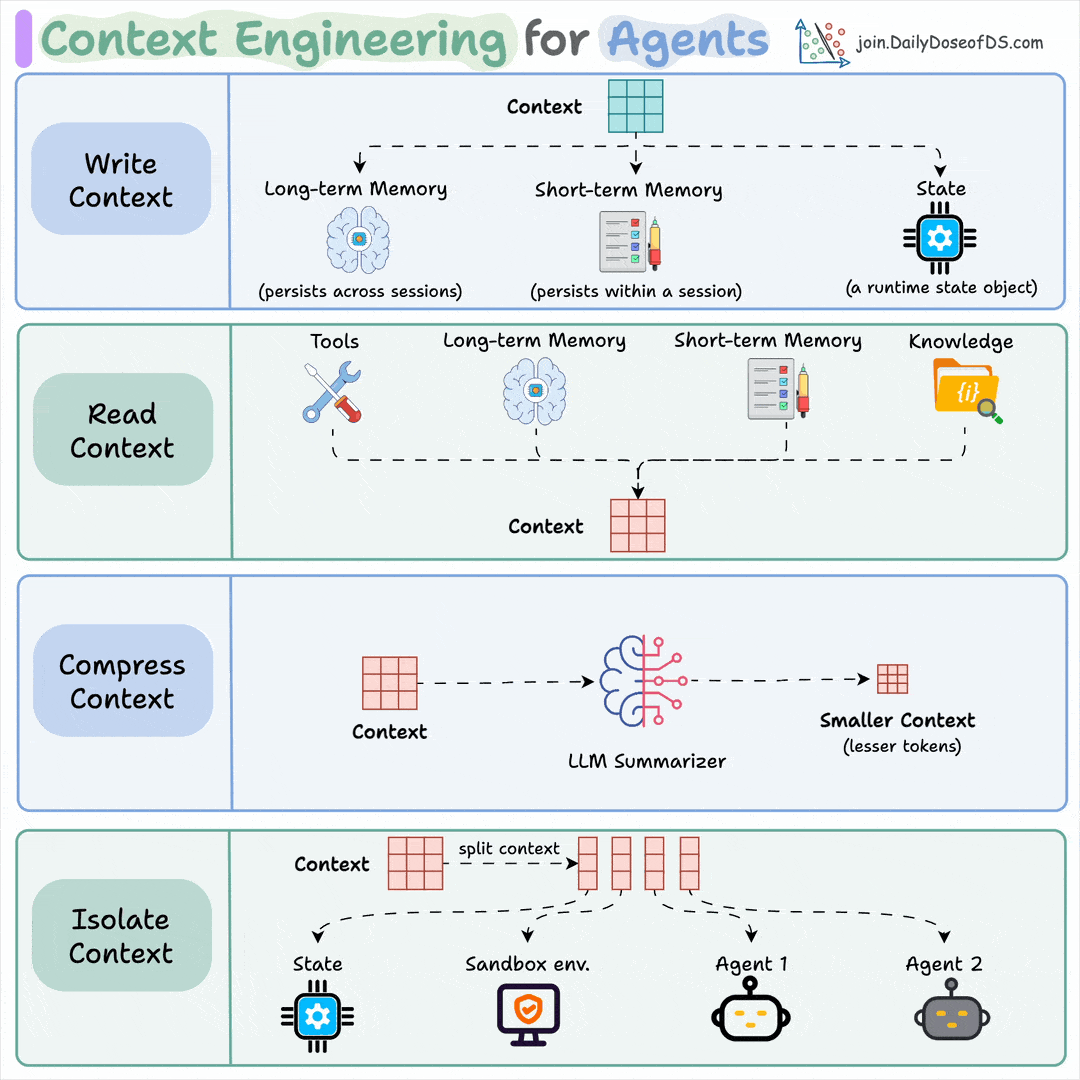
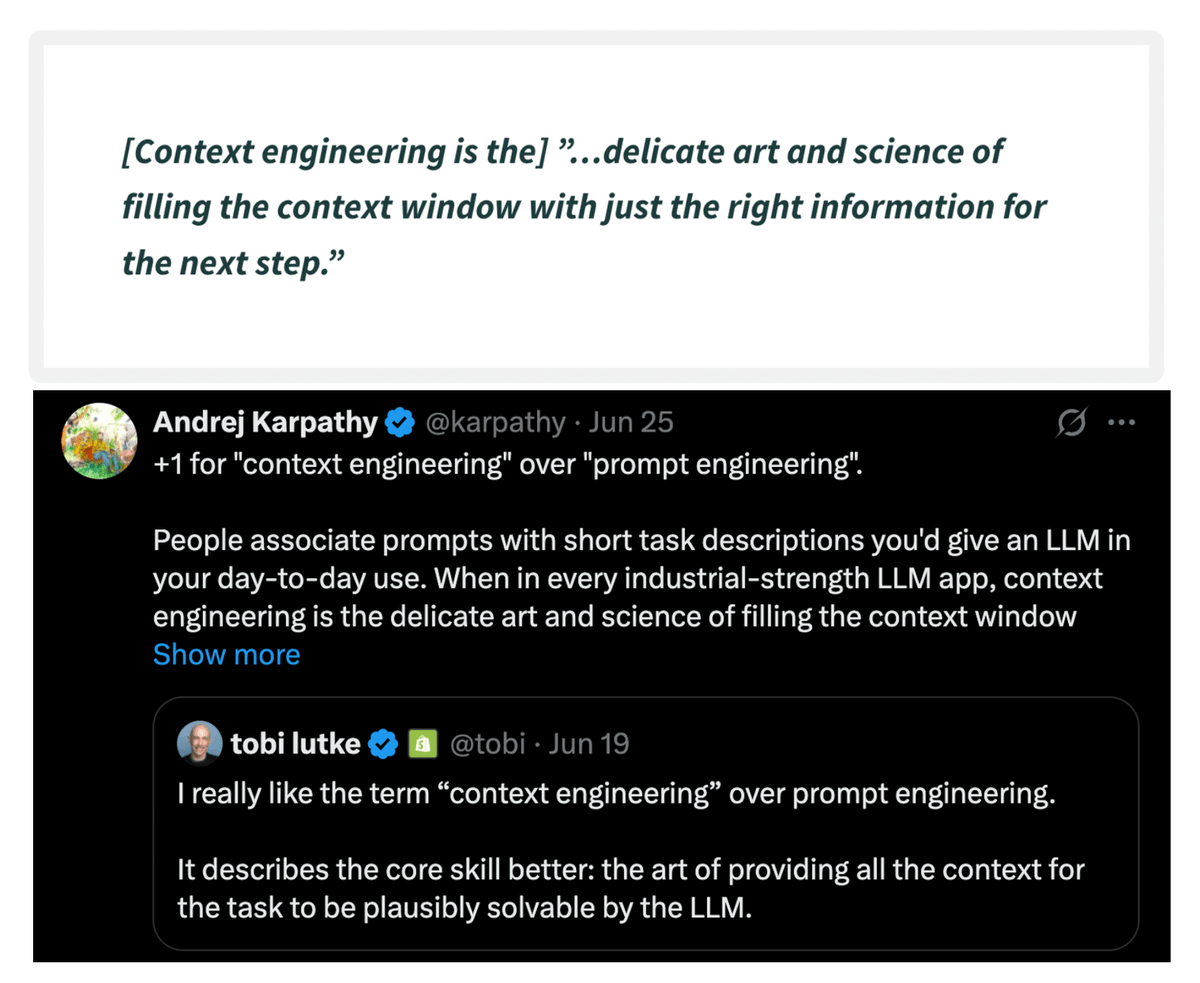
Let's build a mini-ChatGPT that's powered by DeepSeek-R1 (100% local):
Here's a mini-ChatGPT app that runs locally on your computer. You can chat with it just like you would chat with ChatGPT.
We use:
- @DeepSeek_AI R1 as the LLM
- @Ollama to locally serve R1
- @chainlit_io for the UI
Let's build it!
We use:
- @DeepSeek_AI R1 as the LLM
- @Ollama to locally serve R1
- @chainlit_io for the UI
Let's build it!
We begin with the import statements and define the start_chat method.
It is invoked as soon as a new chat session starts.
It is invoked as soon as a new chat session starts.

Next, we define another method which will be invoked to generate a response from the LLM:
• The user inputs a prompt.
• We add it to the interaction history.
• We generate a response from the LLM.
• We store the LLM response in the interaction history.
• The user inputs a prompt.
• We add it to the interaction history.
• We generate a response from the LLM.
• We store the LLM response in the interaction history.

Finally, we define the main method and run the app as follows:

Done!
This launches our 100% locally running mini-ChatGPT that is powered by DeepSeek-R1.
This launches our 100% locally running mini-ChatGPT that is powered by DeepSeek-R1.
That's a wrap!
If you enjoyed this tutorial:
Find me → @_avichawla
Every day, I share tutorials and insights on DS, ML, LLMs, and RAGs.
If you enjoyed this tutorial:
Find me → @_avichawla
Every day, I share tutorials and insights on DS, ML, LLMs, and RAGs.
• • •
Missing some Tweet in this thread? You can try to
force a refresh