Daily tutorials and insights on DS, ML, LLMs, and RAGs • Co-founder @dailydoseofds_ • IIT Varanasi • ex-AI Engineer @ MastercardAI

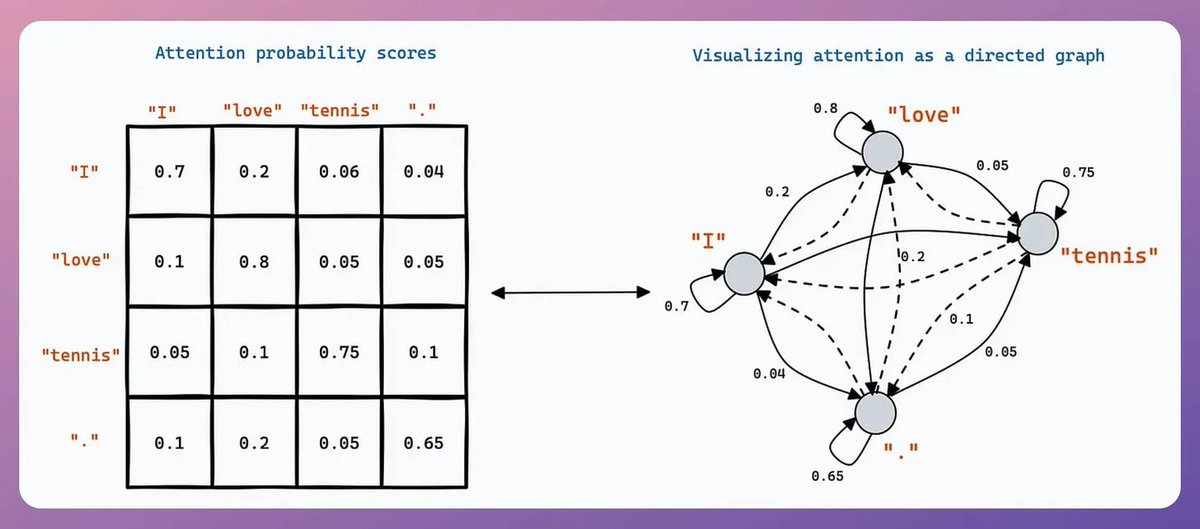
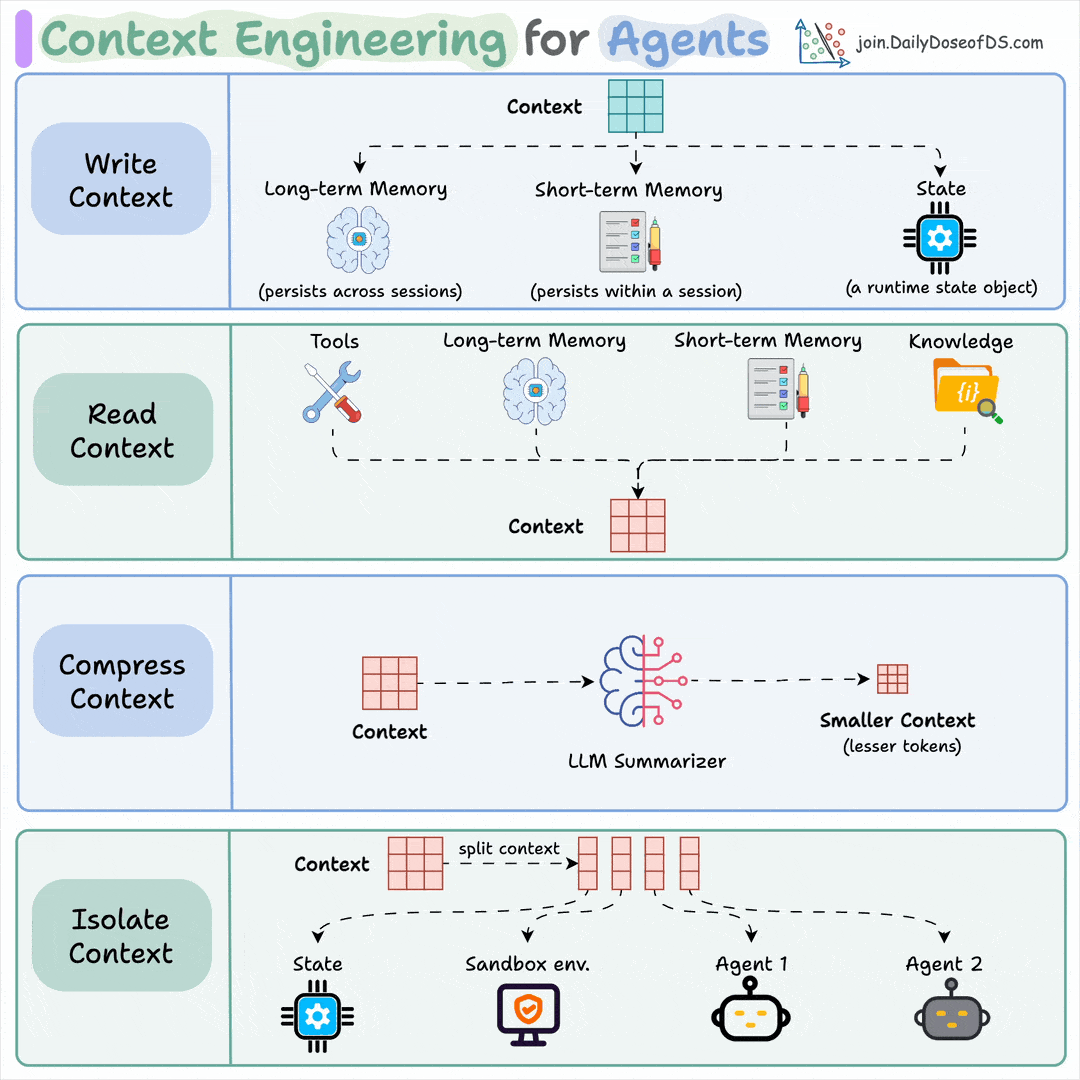 So, what is context engineering?
So, what is context engineering?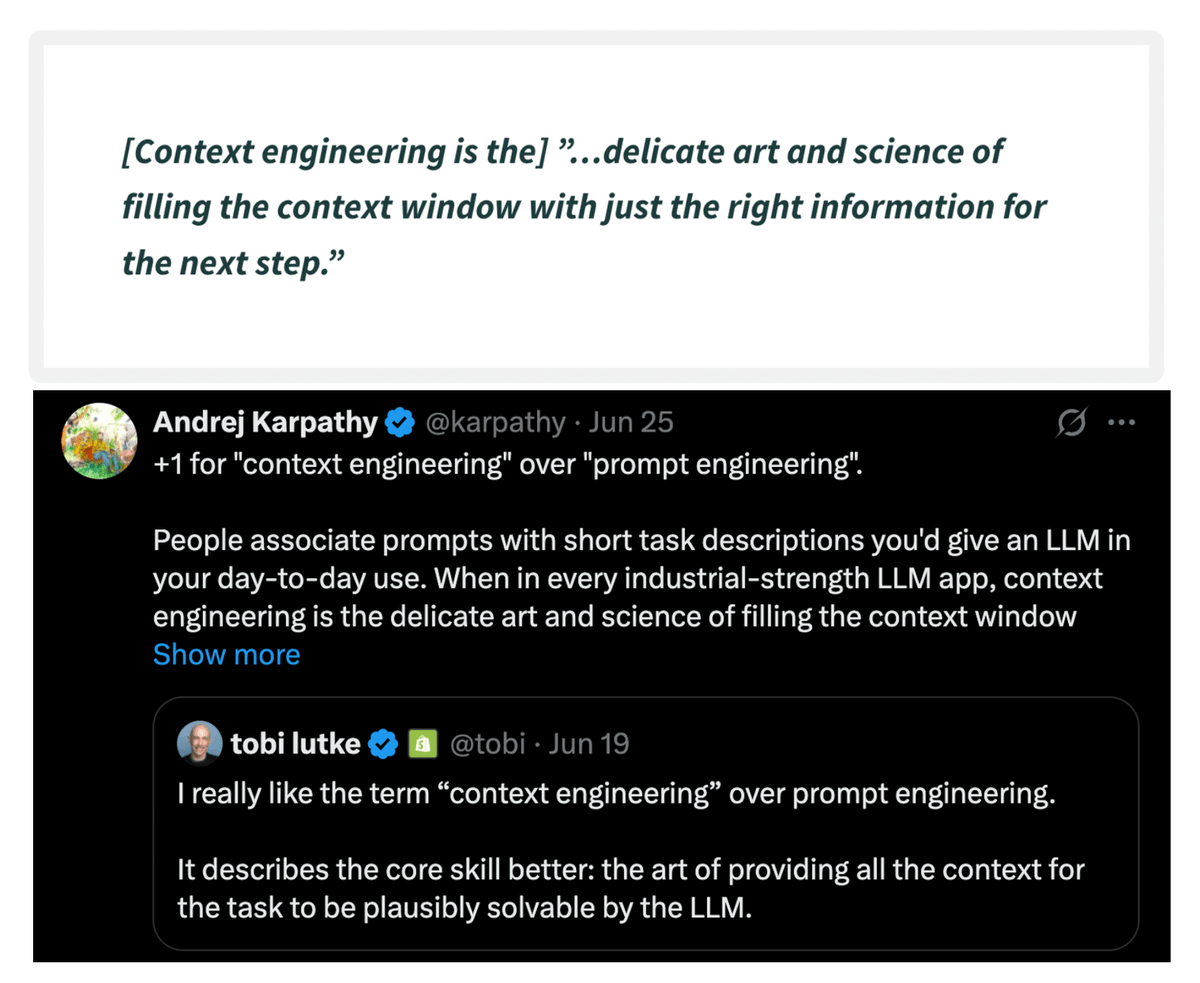
 1️⃣ Prompt engineering
1️⃣ Prompt engineering