
New research paper shows how LLMs can "think" internally before outputting a single token!
Unlike Chain of Thought, this "latent reasoning" happens in the model's hidden space.
TONS of benefits from this approach.
Let me break down this fascinating paper...
Unlike Chain of Thought, this "latent reasoning" happens in the model's hidden space.
TONS of benefits from this approach.
Let me break down this fascinating paper...
The key insight:
Human thinking often happens before we verbalize thoughts.
Traditional LLMs think by generating tokens (Chain of Thought), but this new approach lets models reason in their continuous latent space first.
Human thinking often happens before we verbalize thoughts.
Traditional LLMs think by generating tokens (Chain of Thought), but this new approach lets models reason in their continuous latent space first.

So what is it?
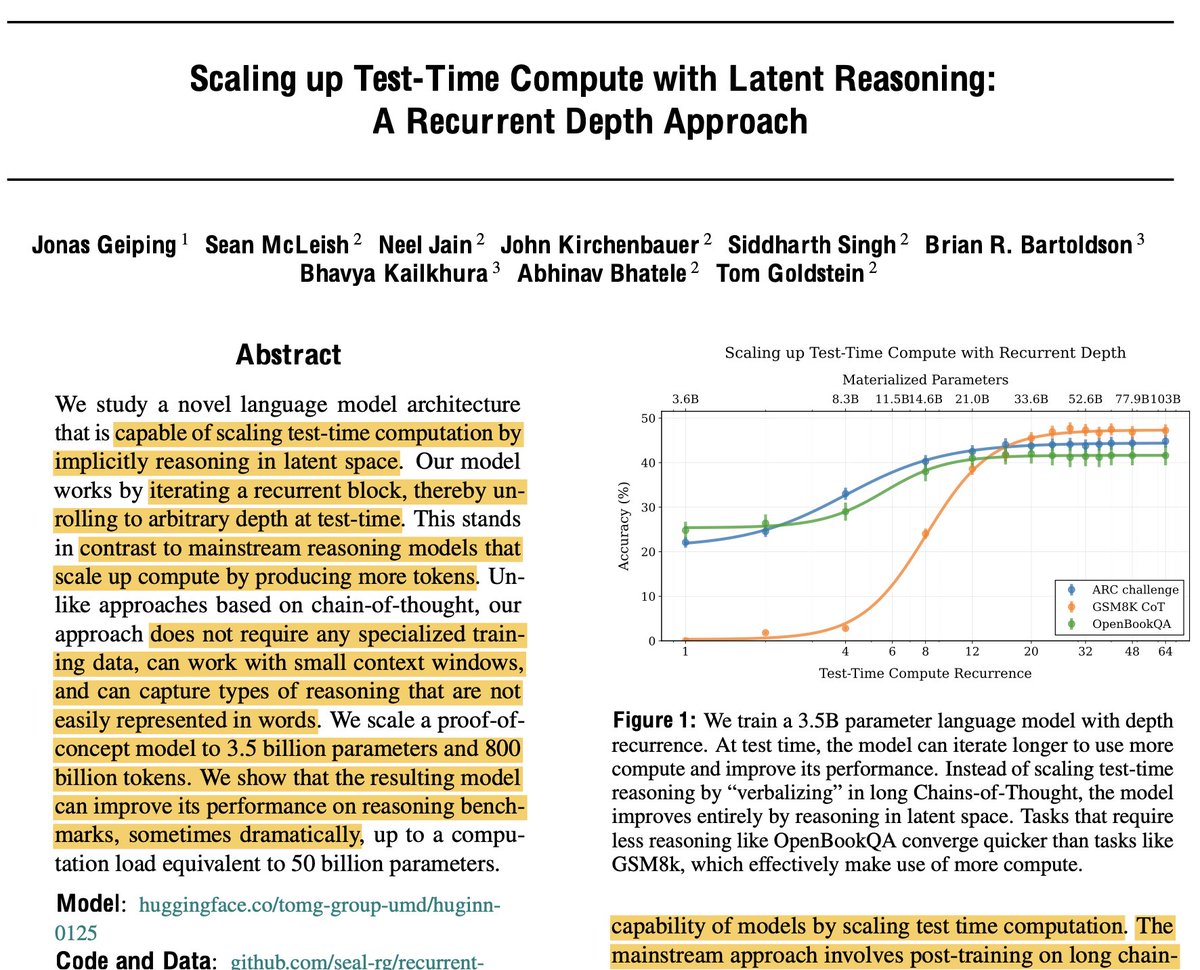
The researchers built a 3.5B parameter model with a recurrent architecture that can "think" repeatedly in latent space before generating any output.
The more thinking iterations, the better the performance!
The researchers built a 3.5B parameter model with a recurrent architecture that can "think" repeatedly in latent space before generating any output.
The more thinking iterations, the better the performance!
How it works:
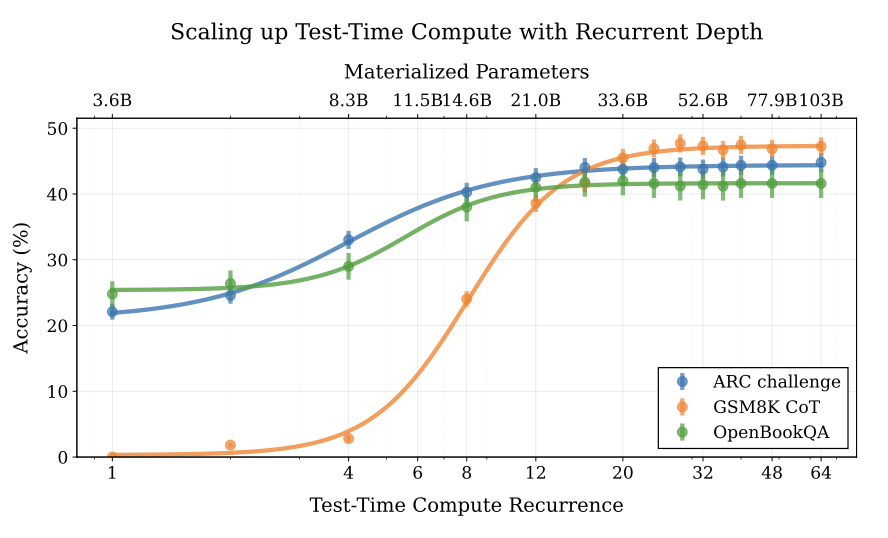
The model has 3 parts:
• Prelude: Embeds input into latent space
• Recurrent Core: Does the actual thinking
• Coda: Converts thoughts back to tokens
The model has 3 parts:
• Prelude: Embeds input into latent space
• Recurrent Core: Does the actual thinking
• Coda: Converts thoughts back to tokens
The cool part?
The model can dynamically adjust how much "thinking" it needs based on the task:
• Math problems → More iterations
• Simple tasks → Fewer iterations
Just like humans do!
The model can dynamically adjust how much "thinking" it needs based on the task:
• Math problems → More iterations
• Simple tasks → Fewer iterations
Just like humans do!
Key advantages over traditional Chain of Thought:
• No special training data needed
• Works with smaller context windows
• Can capture reasoning that's hard to put into words
• No special training data needed
• Works with smaller context windows
• Can capture reasoning that's hard to put into words

Weird finding:
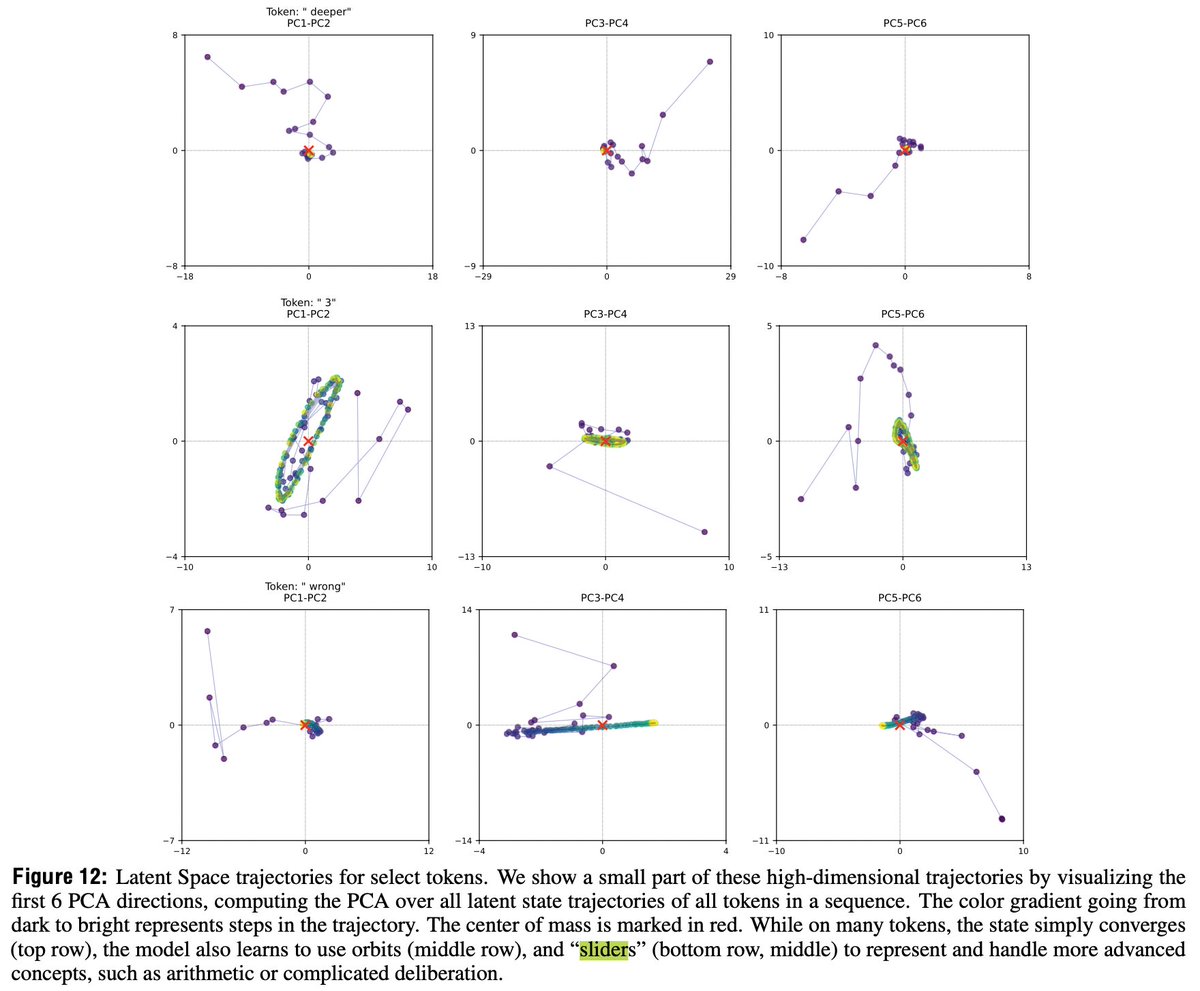
The researchers found fascinating patterns in how the model thinks - it develops "orbits" and "sliders" in latent space to represent different types of reasoning!
The researchers found fascinating patterns in how the model thinks - it develops "orbits" and "sliders" in latent space to represent different types of reasoning!
Is it good?
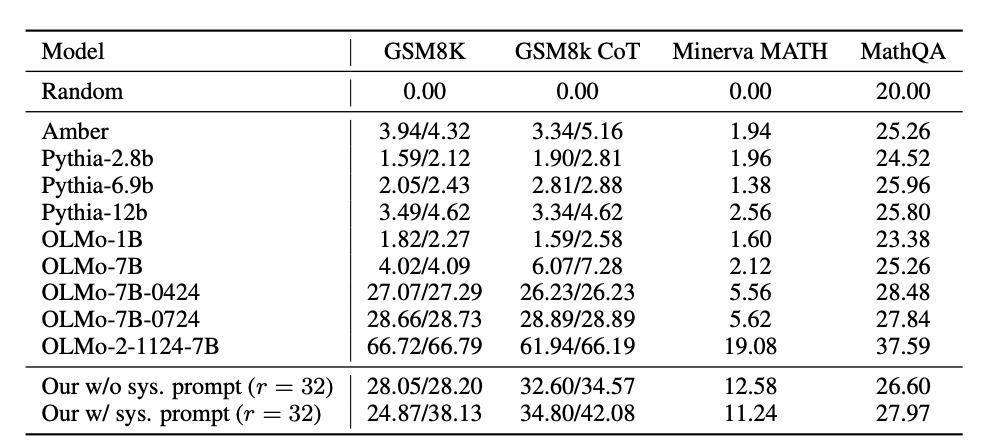
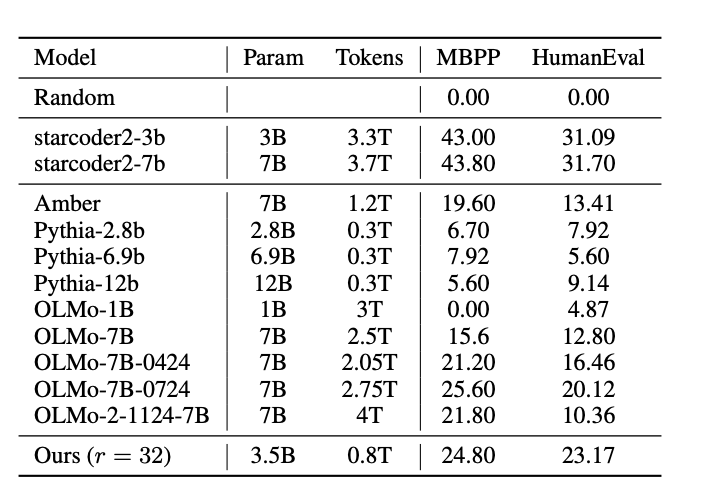
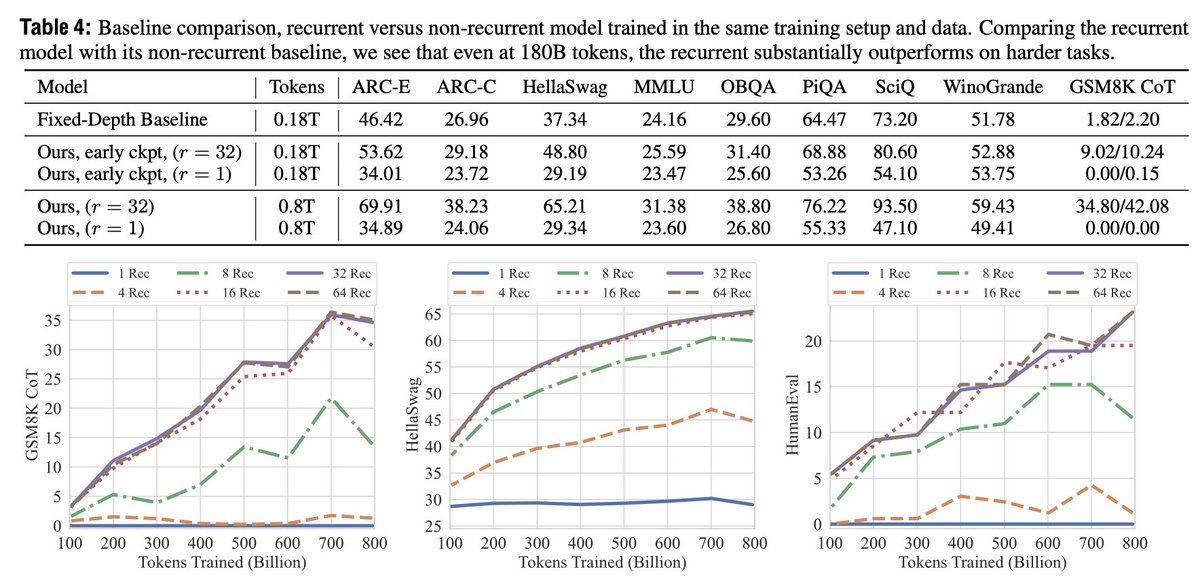
Performance scales impressively with compute - at 32 recurrent iterations, it matches models 2x its size on many tasks.
And it can go even further!
Performance scales impressively with compute - at 32 recurrent iterations, it matches models 2x its size on many tasks.
And it can go even further!
This architecture also enables some neat tricks:
• Zero-shot adaptive compute
• KV cache sharing
• Continuous chain-of-thought
All without special training!
• Zero-shot adaptive compute
• KV cache sharing
• Continuous chain-of-thought
All without special training!
The implications are huge:
This could be a missing piece in getting LLMs to truly reason rather than just manipulate language.
This could be a missing piece in getting LLMs to truly reason rather than just manipulate language.
It's especially interesting given Yann LeCun's critiques that LLMs can't truly reason.
This latent approach might bridge that gap.
This latent approach might bridge that gap.
https://x.com/ylecun/status/1728867808875082017
While still a proof of concept, the results suggest this could be a powerful new direction for language models - combining internal reasoning with traditional token generation.

• • •
Missing some Tweet in this thread? You can try to
force a refresh















