KV caching in LLMs, clearly explained (with visuals):
KV caching is a technique used to speed up LLM inference.
Before understanding the internal details, look at the inference speed difference in the video:
- with KV caching → 9 seconds
- without KV caching → 42 seconds (~5x slower)
Let's dive in!
Before understanding the internal details, look at the inference speed difference in the video:
- with KV caching → 9 seconds
- without KV caching → 42 seconds (~5x slower)
Let's dive in!
To understand KV caching, we must know how LLMs output tokens.
- Transformer produces hidden states for all tokens.
- Hidden states are projected to vocab space.
- Logits of the last token is used to generate the next token.
- Repeat for subsequent tokens.
Check this👇
- Transformer produces hidden states for all tokens.
- Hidden states are projected to vocab space.
- Logits of the last token is used to generate the next token.
- Repeat for subsequent tokens.
Check this👇
Thus, to generate a new token, we only need the hidden state of the most recent token.
None of the other hidden states are required.
Next, let's see how the last hidden state is computed within the transformer layer from the attention mechanism.
None of the other hidden states are required.
Next, let's see how the last hidden state is computed within the transformer layer from the attention mechanism.
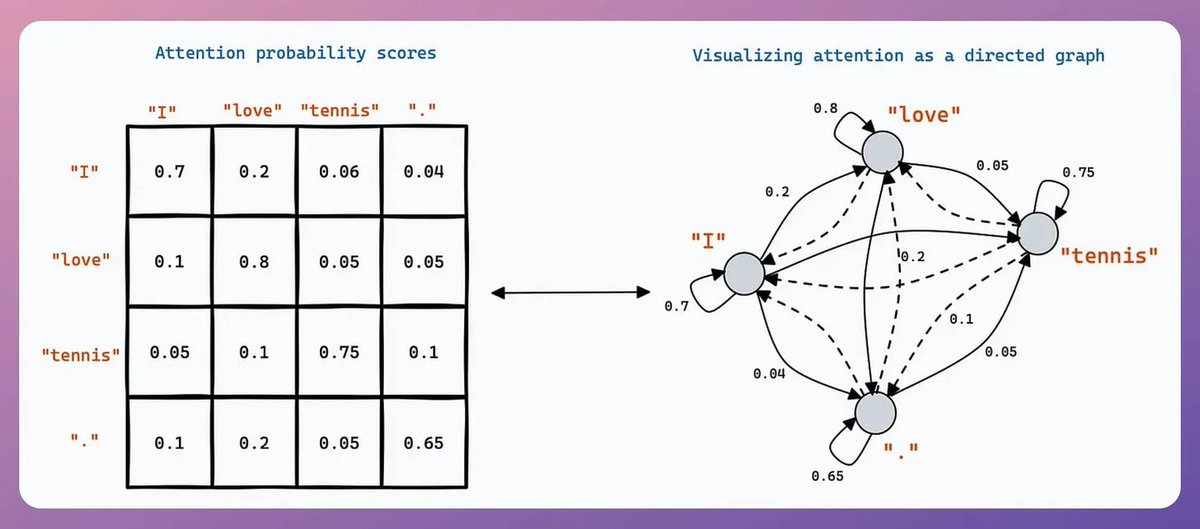
During attention:
The last row of query-key-product involves:
- the last query vector.
- all key vectors.
Also, the last row of the final attention result involves:
- the last query vector.
- all key & value vectors.
Check this visual to understand better:
The last row of query-key-product involves:
- the last query vector.
- all key vectors.
Also, the last row of the final attention result involves:
- the last query vector.
- all key & value vectors.
Check this visual to understand better:
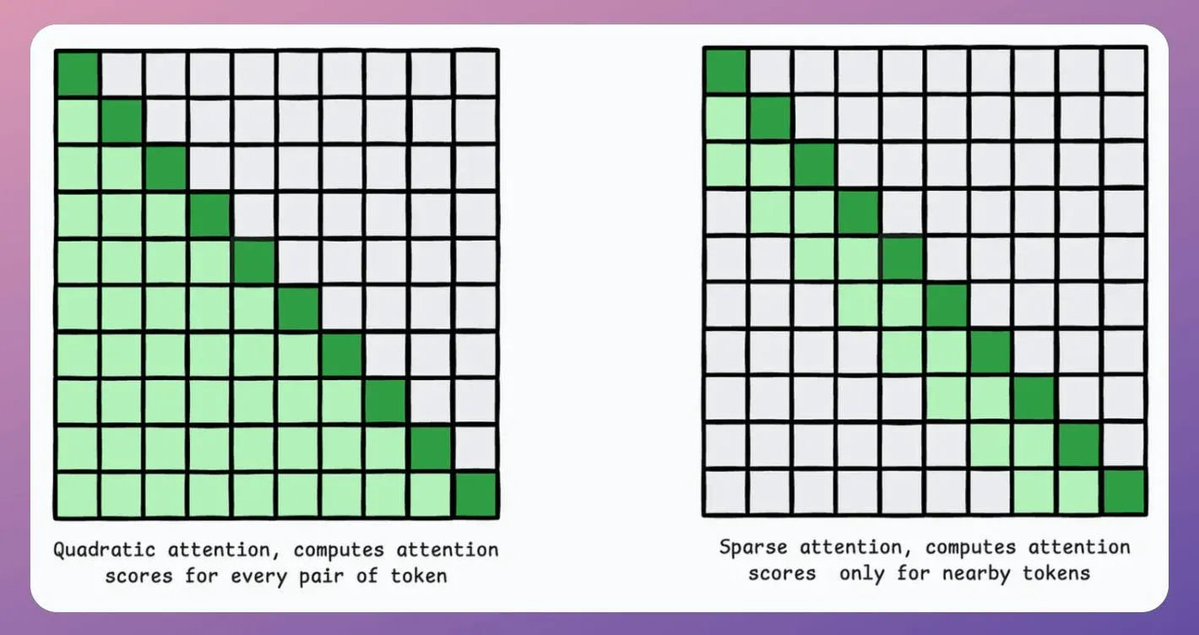
The above insight suggests that to generate a new token, every attention operation in the network only needs:
- query vector of the last token.
- all key & value vectors.
But, there's one more key insight here.
- query vector of the last token.
- all key & value vectors.
But, there's one more key insight here.
As we generate new tokens:
- The KV vectors used for ALL previous tokens do not change.
Thus, we just need to generate a KV vector for the token generated one step before.
Rest of the KV vectors can be retrieved from a cache to save compute and time.
- The KV vectors used for ALL previous tokens do not change.
Thus, we just need to generate a KV vector for the token generated one step before.
Rest of the KV vectors can be retrieved from a cache to save compute and time.
This is called KV caching!
To reiterate, instead of redundantly computing KV vectors of all context tokens, cache them.
To generate a token:
- Generate QKV vector for the token generated one step before.
- Get all other KV vectors from cache.
- Compute attention.
Check this👇
To reiterate, instead of redundantly computing KV vectors of all context tokens, cache them.
To generate a token:
- Generate QKV vector for the token generated one step before.
- Get all other KV vectors from cache.
- Compute attention.
Check this👇
KV caching saves time during inference.
In fact, this is why ChatGPT takes some time to generate the first token than the subsequent tokens.
During that time, it is computing the KV cache of the prompt.
In fact, this is why ChatGPT takes some time to generate the first token than the subsequent tokens.
During that time, it is computing the KV cache of the prompt.
That said, KV cache also takes a lot of memory.
Llama3-70B has:
- total layers = 80
- hidden size = 8k
- max output size = 4k
Here:
- Every token takes up ~2.5 MB in KV cache.
- 4k tokens will take up 10.5 GB.
More users → more memory.
I'll cover KV optimization soon.
Llama3-70B has:
- total layers = 80
- hidden size = 8k
- max output size = 4k
Here:
- Every token takes up ~2.5 MB in KV cache.
- 4k tokens will take up 10.5 GB.
More users → more memory.
I'll cover KV optimization soon.
That's a wrap!
If you enjoyed this tutorial:
Find me → @_avichawla
Every day, I share tutorials and insights on DS, ML, LLMs, and RAGs.
If you enjoyed this tutorial:
Find me → @_avichawla
Every day, I share tutorials and insights on DS, ML, LLMs, and RAGs.
• • •
Missing some Tweet in this thread? You can try to
force a refresh