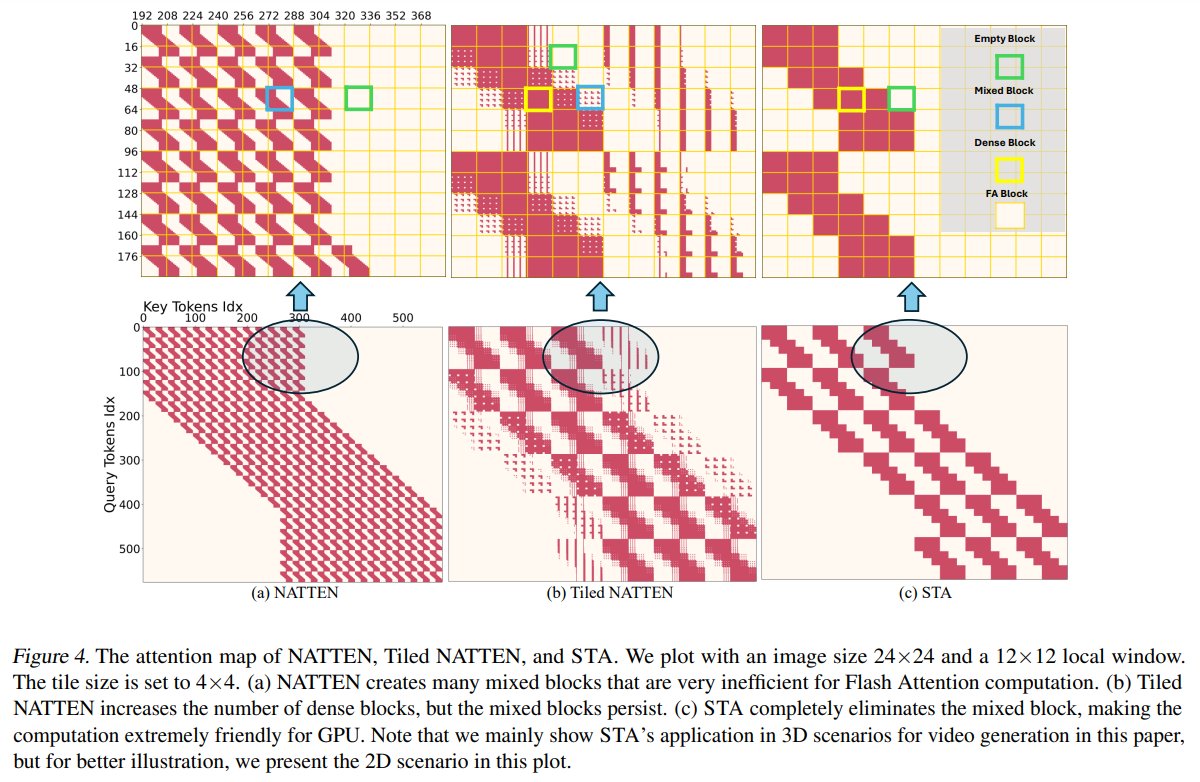
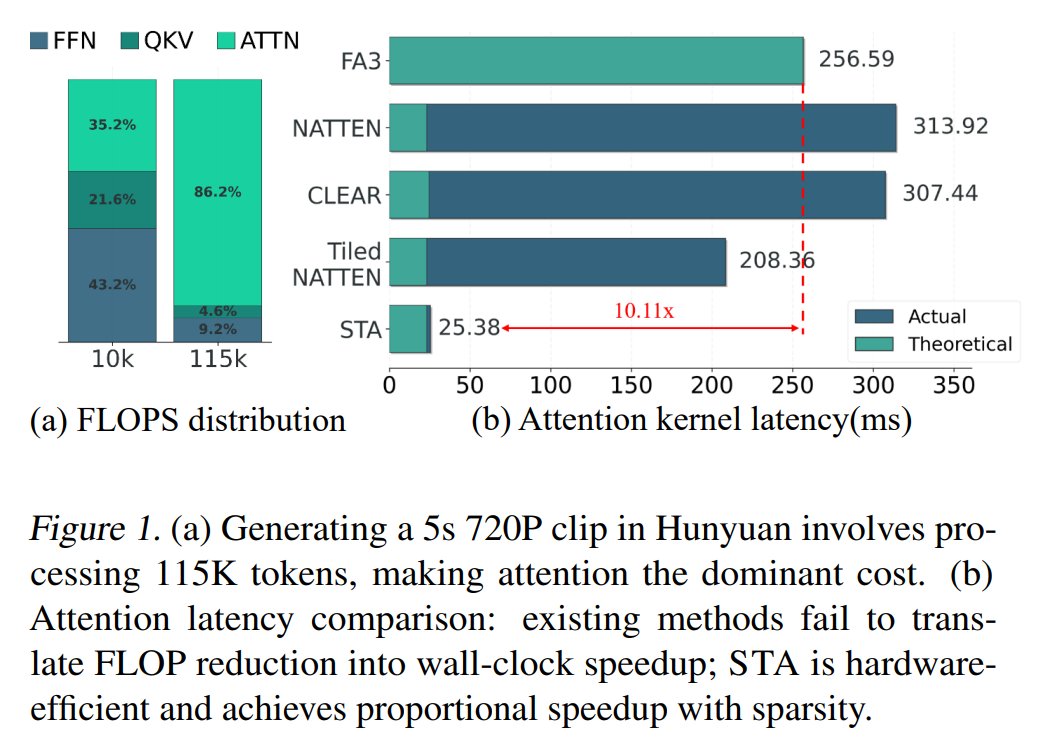
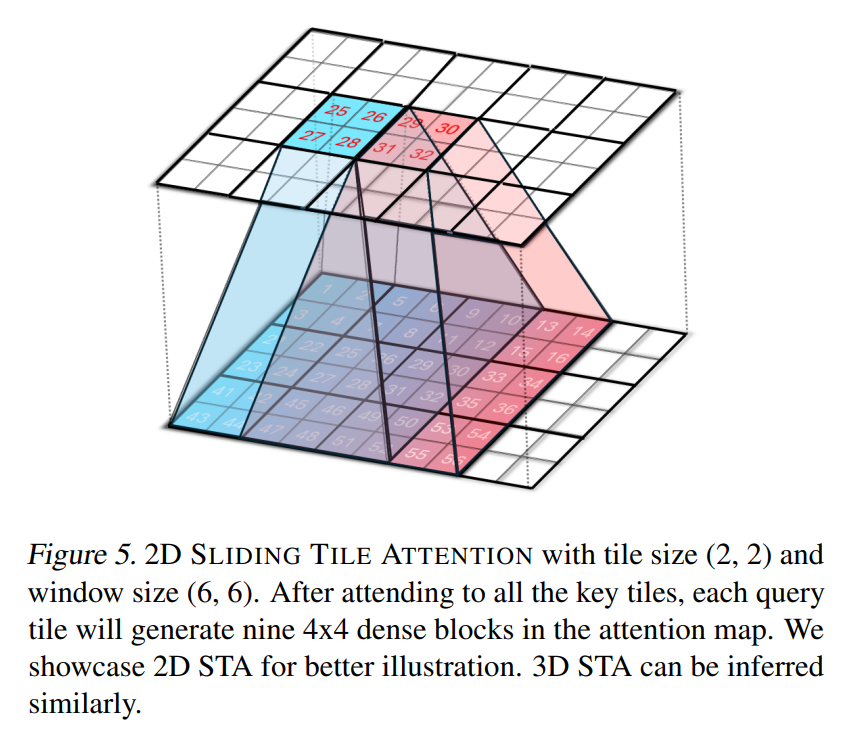
The freshest AI/ML research of the week:
Our top 9
▪️ SigLIP 2
▪️ Intuitive Physics Understanding Emerges from Self-Supervised Pretraining on Natural Videos
▪️ Native Sparse Attention
▪️ OctoTools
▪️ ReLearn
▪️ On the Trustworthiness of Generative Foundation Models
▪️ S* Test Time Scaling for Code Generation
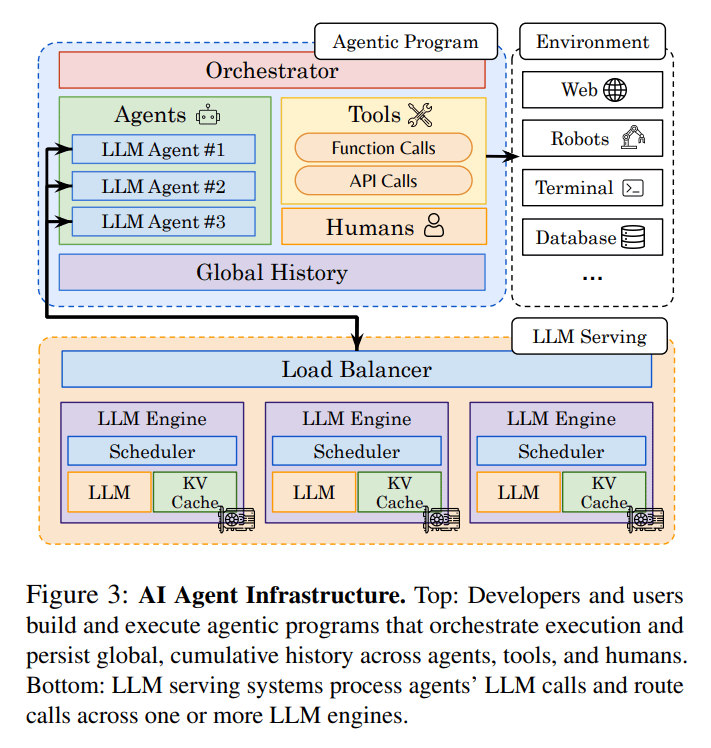
▪️ Autellix (Serving Engine for LLM Agents)
▪️ Is That Your Final Answer? Test-Time Scaling Improves Selective Question Answering
▪️ SurveyX
▪️ From RAG to Memory: Non-Parametric Continual Learning for LLMs
▪️ How Much Knowledge Can You Pack into a LoRA Adapter without Harming LLM?
▪️ Train Small, Infer Large
▪️ Eager Updates for Overlapped Communication and Computation in DiLoCo
▪️ S^2R: Teaching LLMs to Self-verify and Self-correct via RL
▪️ Logic-RL
▪️ Discovering Highly Efficient Low-Weight Quantum Error-Correcting Codes with RL
▪️ Armap
▪️ Thinking Preference Optimization
▪️ Rethinking Diverse Human Preference Learning through Principal Component Analysis
▪️ Craw4LLM
▪️ LLMs and Mathematical Reasoning Failures
▪️ Small Models Struggle to Learn from Strong Reasoners
▪️ Flow-of-Options: Diversified and Improved LLM Reasoning by Thinking Through Options
🧵
Our top 9
▪️ SigLIP 2
▪️ Intuitive Physics Understanding Emerges from Self-Supervised Pretraining on Natural Videos
▪️ Native Sparse Attention
▪️ OctoTools
▪️ ReLearn
▪️ On the Trustworthiness of Generative Foundation Models
▪️ S* Test Time Scaling for Code Generation
▪️ Autellix (Serving Engine for LLM Agents)
▪️ Is That Your Final Answer? Test-Time Scaling Improves Selective Question Answering
▪️ SurveyX
▪️ From RAG to Memory: Non-Parametric Continual Learning for LLMs
▪️ How Much Knowledge Can You Pack into a LoRA Adapter without Harming LLM?
▪️ Train Small, Infer Large
▪️ Eager Updates for Overlapped Communication and Computation in DiLoCo
▪️ S^2R: Teaching LLMs to Self-verify and Self-correct via RL
▪️ Logic-RL
▪️ Discovering Highly Efficient Low-Weight Quantum Error-Correcting Codes with RL
▪️ Armap
▪️ Thinking Preference Optimization
▪️ Rethinking Diverse Human Preference Learning through Principal Component Analysis
▪️ Craw4LLM
▪️ LLMs and Mathematical Reasoning Failures
▪️ Small Models Struggle to Learn from Strong Reasoners
▪️ Flow-of-Options: Diversified and Improved LLM Reasoning by Thinking Through Options
🧵
1. SigLIP 2: Multilingual Vision-Language Encoders with Improved Semantic Understanding, @GoogleDeepMind
Advances vision-language learning with multilingual training and improved zero-shot capabilities
huggingface.co/papers/2502.14…
Checkpoints: github.com/google-researc… x.com/12714828789589…
Advances vision-language learning with multilingual training and improved zero-shot capabilities
huggingface.co/papers/2502.14…
Checkpoints: github.com/google-researc… x.com/12714828789589…
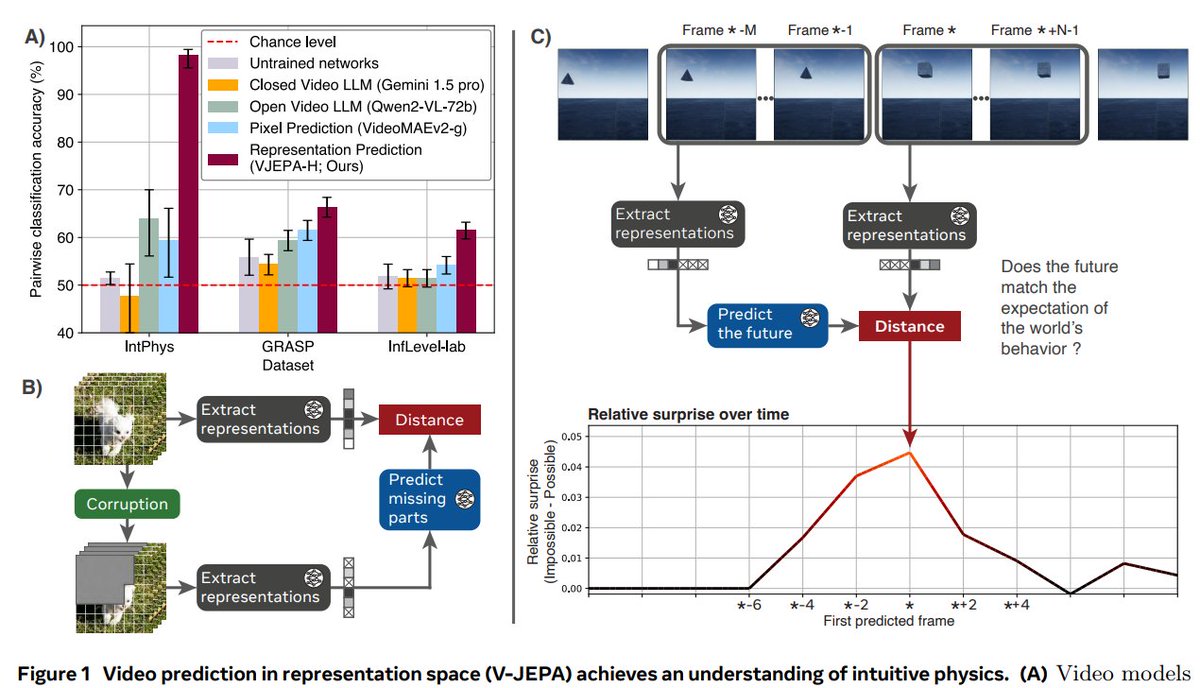
2. Intuitive Physics Understanding Emerges from Self-Supervised Pretraining on Natural Videos, @AIatMeta
Trains a model on video frame prediction to develop intuitive physics reasoning
huggingface.co/papers/2502.11…
Code and data: : github.com/facebookresear…
Trains a model on video frame prediction to develop intuitive physics reasoning
huggingface.co/papers/2502.11…
Code and data: : github.com/facebookresear…
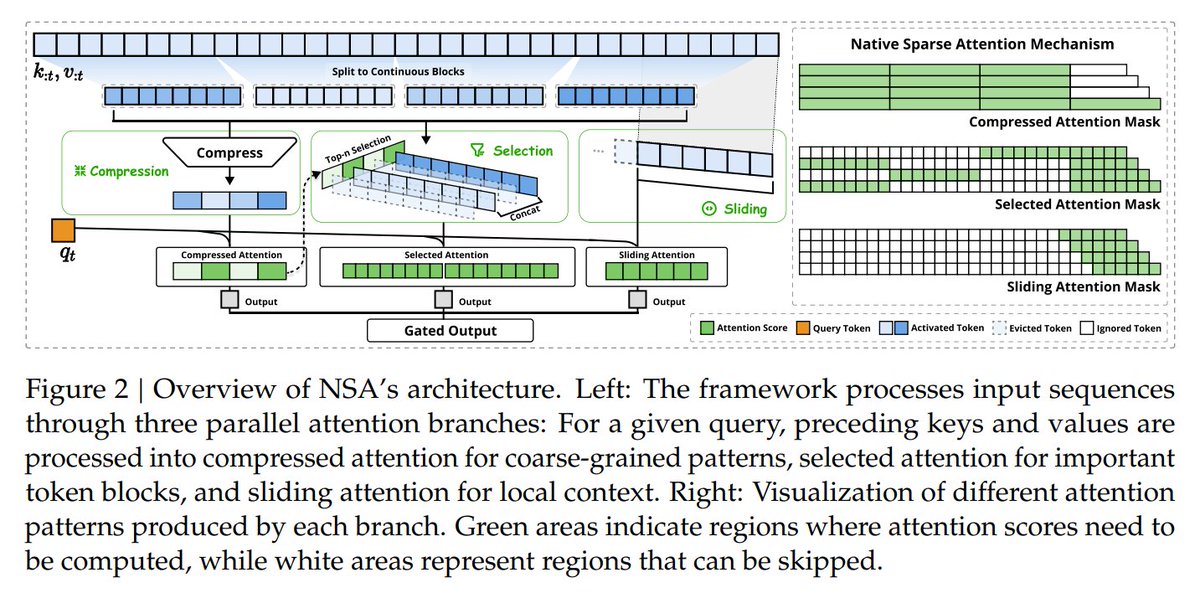
3. Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention, @deepseek_ai
Optimizes sparse attention for long-context models, significantly improving efficiency
huggingface.co/papers/2502.11…
Optimizes sparse attention for long-context models, significantly improving efficiency
huggingface.co/papers/2502.11…
4. OctoTools: An Agentic Framework with Extensible Tools for Complex Reasoning, @Stanford
Develops a tool-based system for multi-step decision-making and structured tool use
huggingface.co/papers/2502.11…
Project page: octotools.github.io x.com/12714828789589…
Develops a tool-based system for multi-step decision-making and structured tool use
huggingface.co/papers/2502.11…
Project page: octotools.github.io x.com/12714828789589…
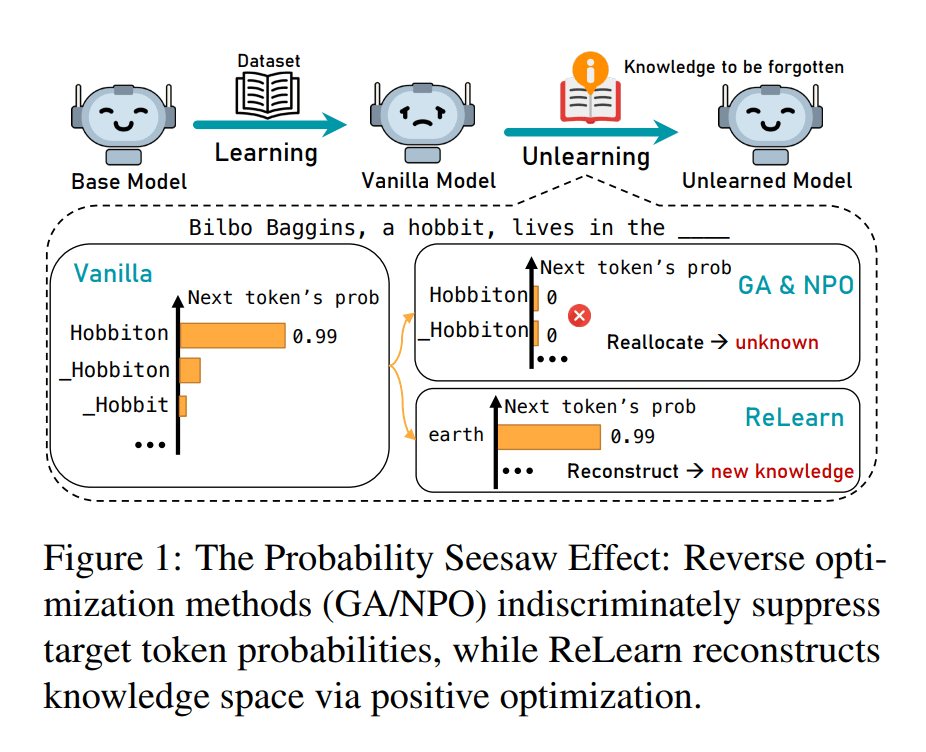
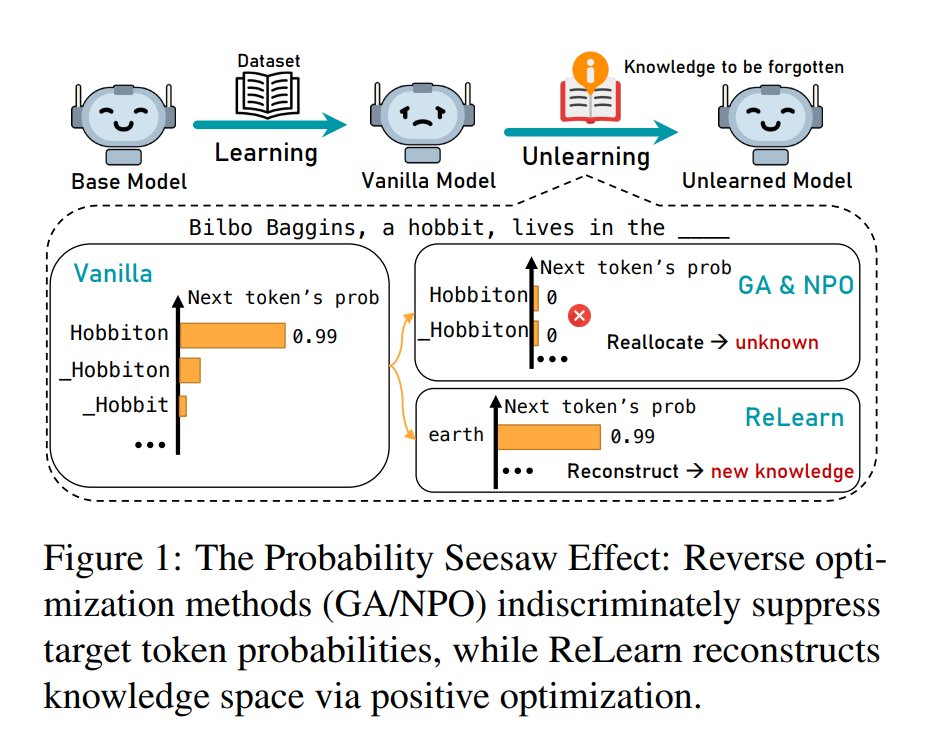
5. ReLearn: Unlearning via Learning for Large Language Models
Introduces a knowledge-unlearning method that removes sensitive knowledge without degrading fluency
huggingface.co/papers/2502.11…
Code: github.com/zjunlp/unlearn.
Introduces a knowledge-unlearning method that removes sensitive knowledge without degrading fluency
huggingface.co/papers/2502.11…
Code: github.com/zjunlp/unlearn.
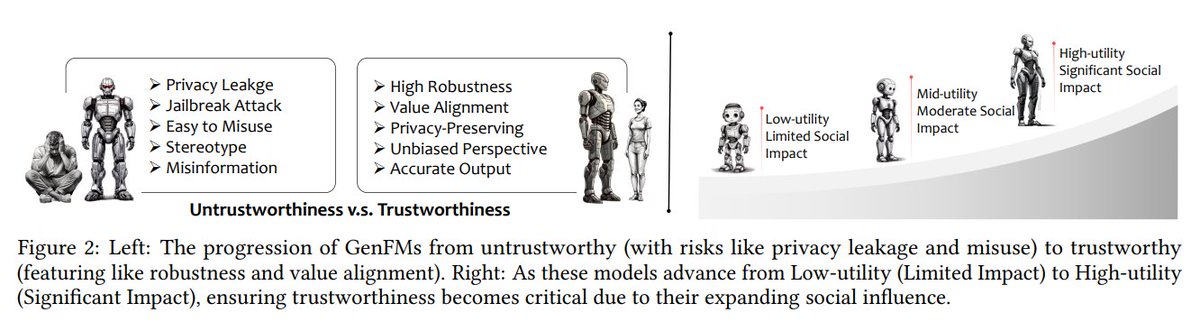
6. On the Trustworthiness of Generative Foundation Models – Guideline, Assessment, and Perspective
Develops a framework for evaluating trustworthiness in generative AI models
huggingface.co/papers/2502.14…
Develops a framework for evaluating trustworthiness in generative AI models
huggingface.co/papers/2502.14…
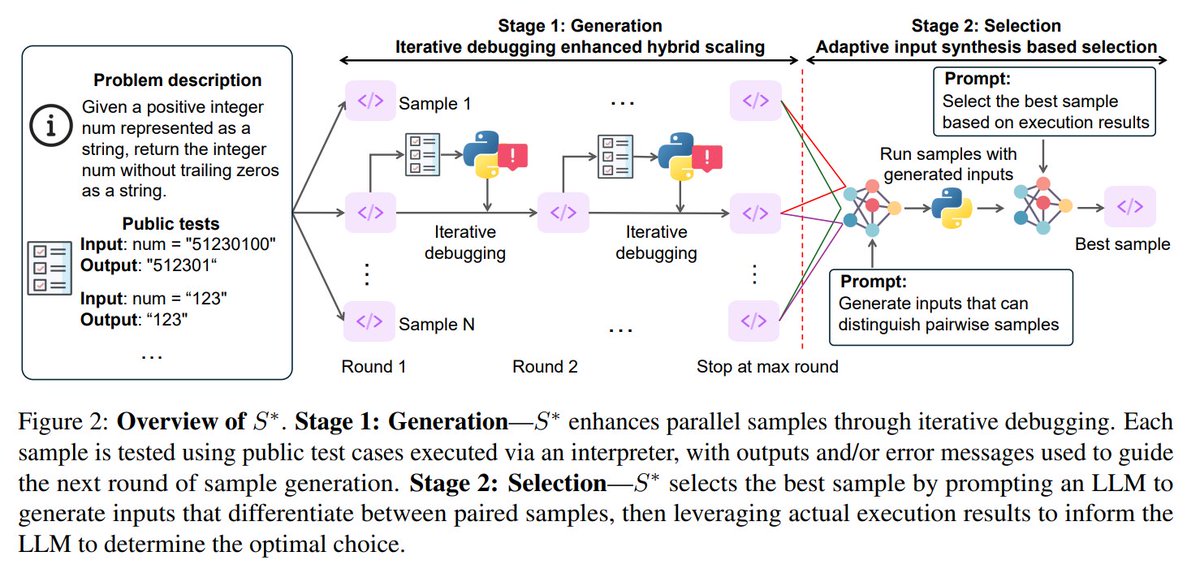
7. S* Test Time Scaling for Code Generation, @UofCalifornia
Introduces a test-time scaling framework that improves LLM-based code generation through iterative debugging
huggingface.co/papers/2502.14…
Code: github.com/NovaSky-AI/Sky…
Introduces a test-time scaling framework that improves LLM-based code generation through iterative debugging
huggingface.co/papers/2502.14…
Code: github.com/NovaSky-AI/Sky…
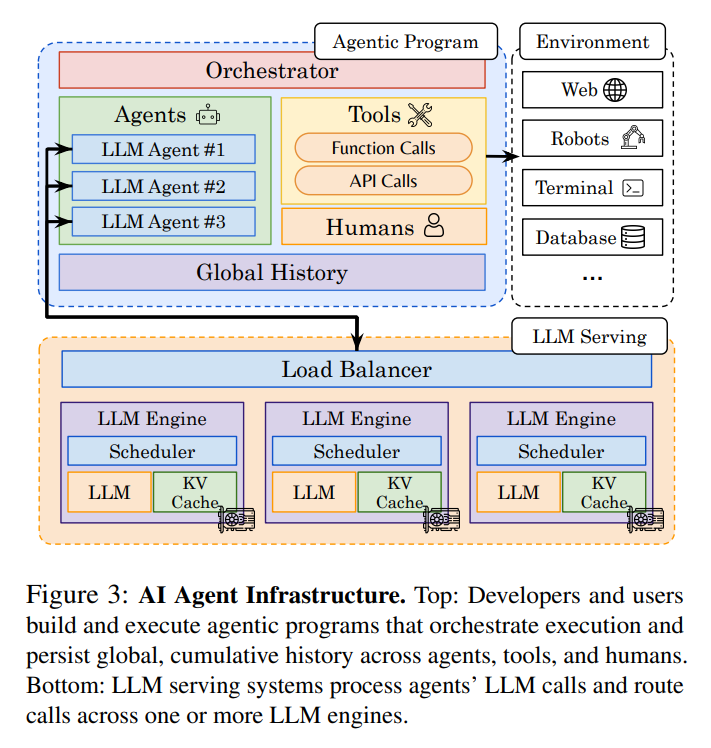
8. Autellix: An Efficient Serving Engine for LLM Agents as General Programs
Enhances LLM serving efficiency for agentic applications by optimizing request scheduling
huggingface.co/papers/2502.13…
Enhances LLM serving efficiency for agentic applications by optimizing request scheduling
huggingface.co/papers/2502.13…
9. Is That Your Final Answer? Test-Time Scaling Improves Selective Question Answering, @JohnsHopkins
Examines how inference scaling helps LLMs selectively answer questions with confidence
huggingface.co/papers/2502.13…
Examines how inference scaling helps LLMs selectively answer questions with confidence
huggingface.co/papers/2502.13…
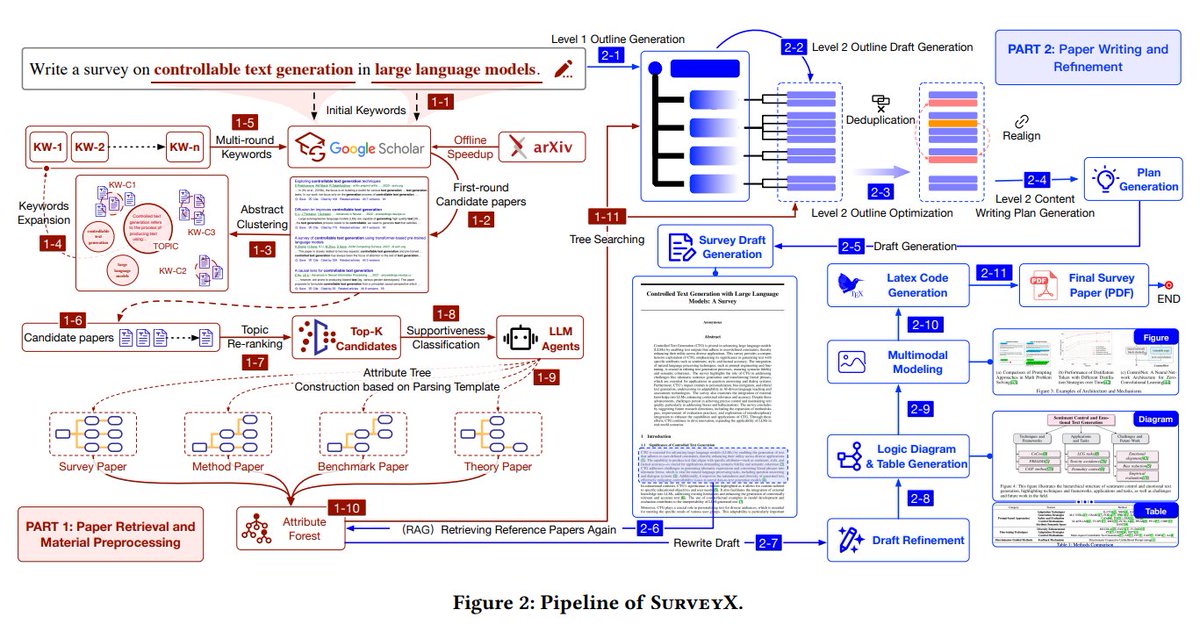
10. SurveyX: Academic Survey Automation via Large Language Models
Develops an automated system for generating high-quality academic surveys, improving citation precision and evaluation frameworks
huggingface.co/papers/2502.14…
Develops an automated system for generating high-quality academic surveys, improving citation precision and evaluation frameworks
huggingface.co/papers/2502.14…
11. From RAG to Memory: Non-Parametric Continual Learning for Large Language Models
Introduces HippoRAG 2, a retrieval-augmented generation method that enhances long-term memory and retrieval
huggingface.co/papers/2502.14…
Code and data github.com/OSU-NLP-Group/…
Introduces HippoRAG 2, a retrieval-augmented generation method that enhances long-term memory and retrieval
huggingface.co/papers/2502.14…
Code and data github.com/OSU-NLP-Group/…
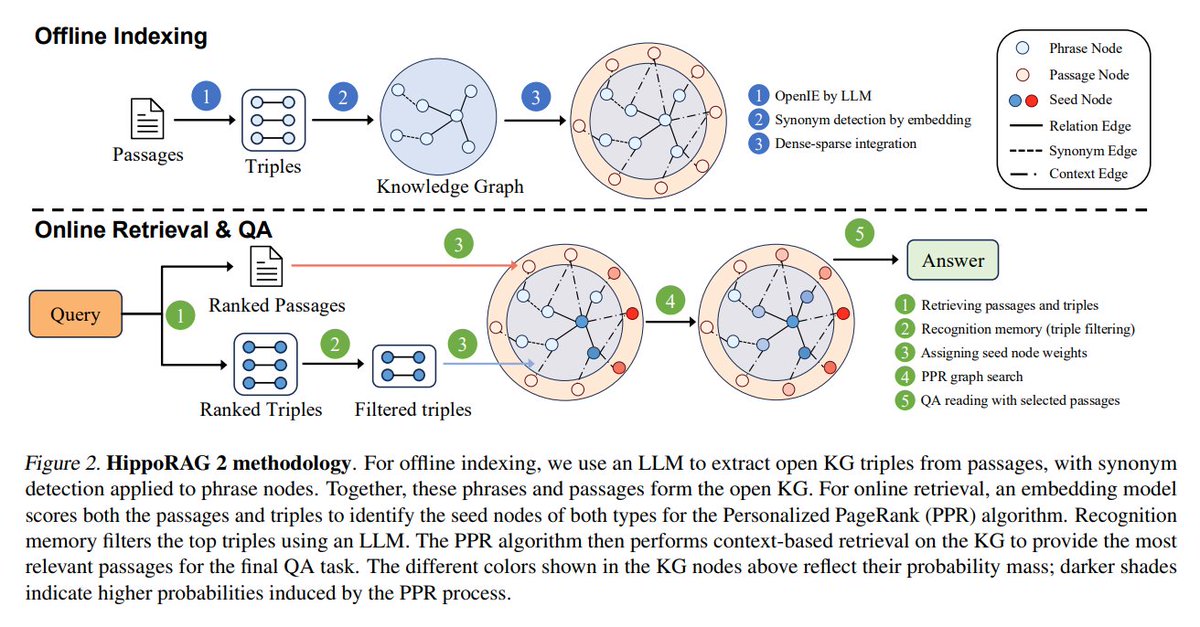
12. How Much Knowledge Can You Pack into a LoRA Adapter without Harming LLM?
Examines the trade-offs in integrating new knowledge into LLMs using Low-Rank Adaptation (LoRA)
huggingface.co/papers/2502.14…
Examines the trade-offs in integrating new knowledge into LLMs using Low-Rank Adaptation (LoRA)
huggingface.co/papers/2502.14…
13. Train Small, Infer Large: Memory-Efficient LoRA Training for Large Language Models
Develops LORAM, a memory-efficient fine-tuning approach that enables large model training on low-resource hardware
huggingface.co/papers/2502.13…
Code: github.com/junzhang-zj/Lo…
Develops LORAM, a memory-efficient fine-tuning approach that enables large model training on low-resource hardware
huggingface.co/papers/2502.13…
Code: github.com/junzhang-zj/Lo…
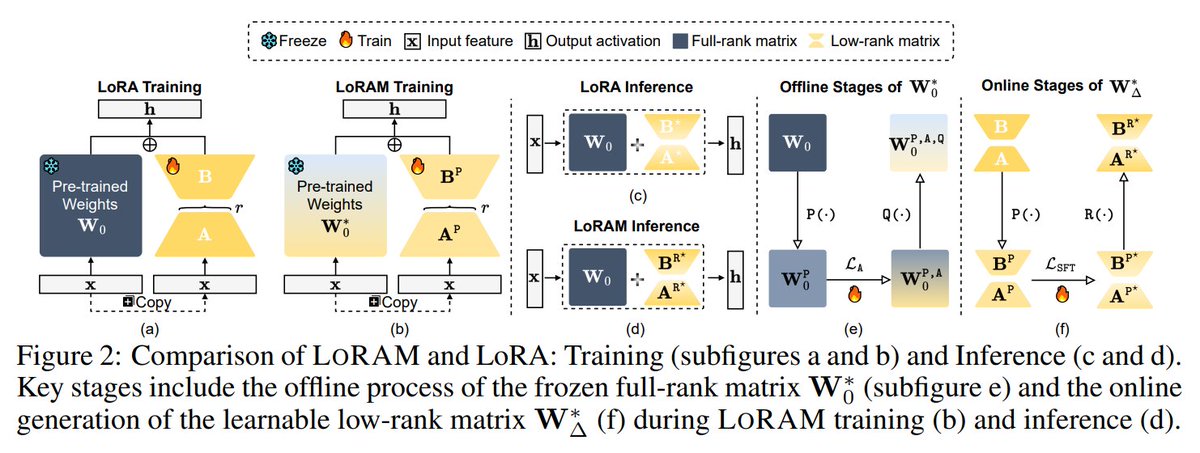
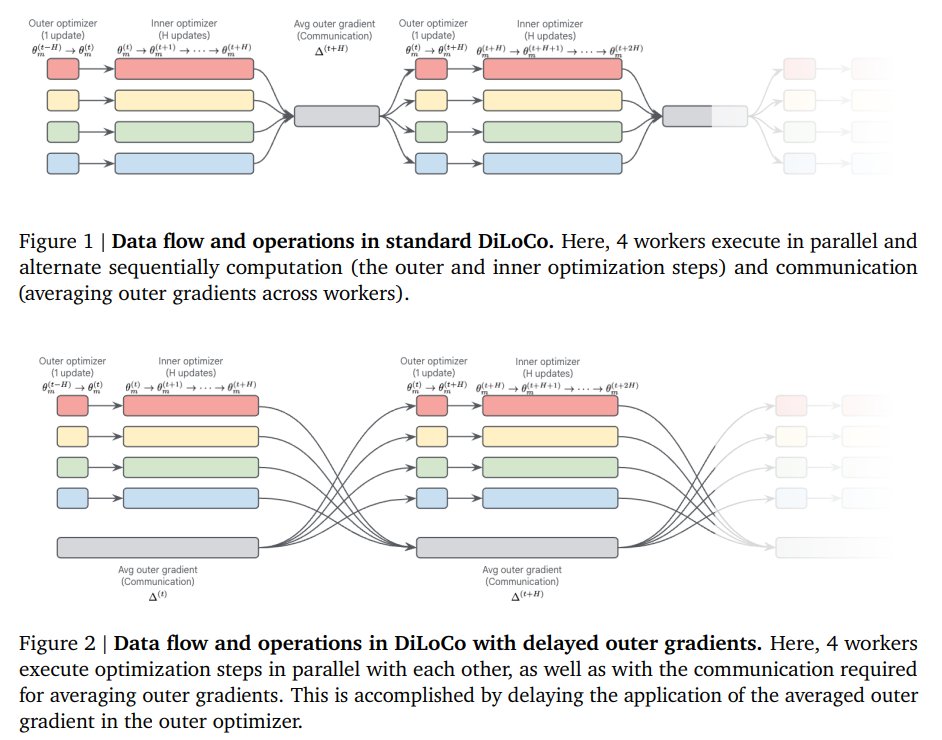
14. Eager Updates for Overlapped Communication and Computation in DiLoCo, @GoogleDeepMind
Reduces communication bottlenecks in distributed LLM training by overlapping updates with computation
huggingface.co/papers/2502.12…
Reduces communication bottlenecks in distributed LLM training by overlapping updates with computation
huggingface.co/papers/2502.12…
15. S^2R: Teaching LLMs to Self-verify and Self-correct via RL
Develops a framework to improve LLM reasoning by teaching self-verification and self-correction
huggingface.co/papers/2502.12…
Code and data: github.com/NineAbyss/S2R.
Develops a framework to improve LLM reasoning by teaching self-verification and self-correction
huggingface.co/papers/2502.12…
Code and data: github.com/NineAbyss/S2R.
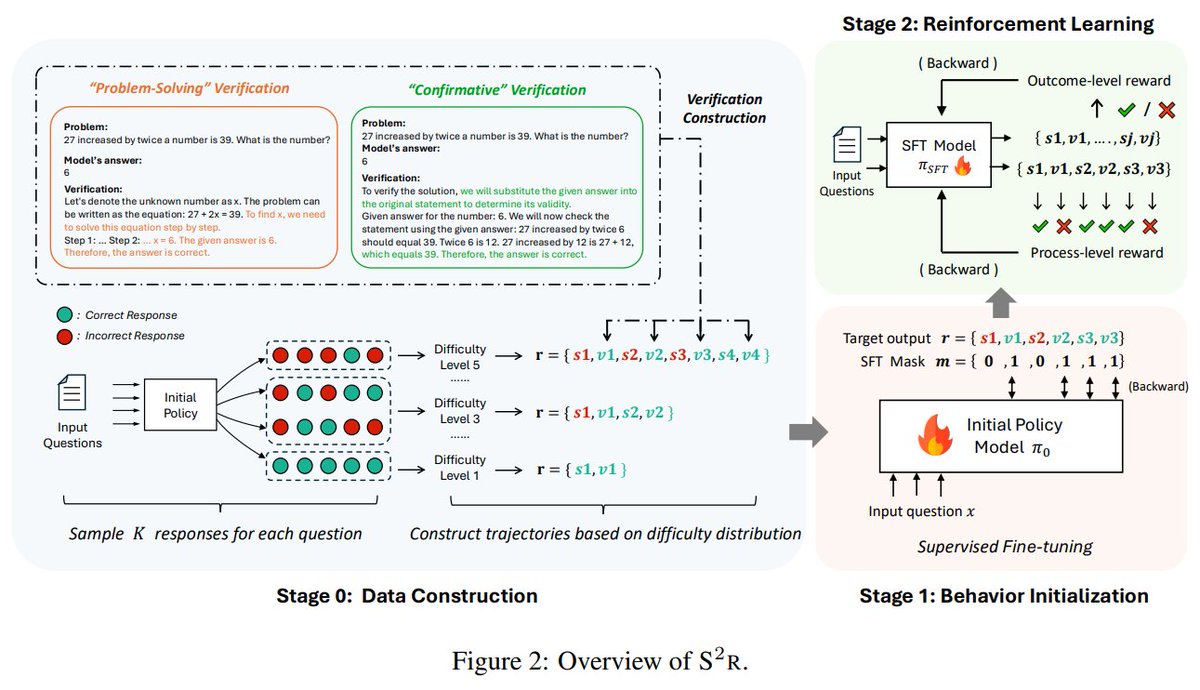
16. Logic-RL: Unleashing LLM Reasoning with Rule-Based RL, @MSFTResearch Asia
Uses RL to enhance logical reasoning capabilities
huggingface.co/papers/2502.14…
Uses RL to enhance logical reasoning capabilities
huggingface.co/papers/2502.14…
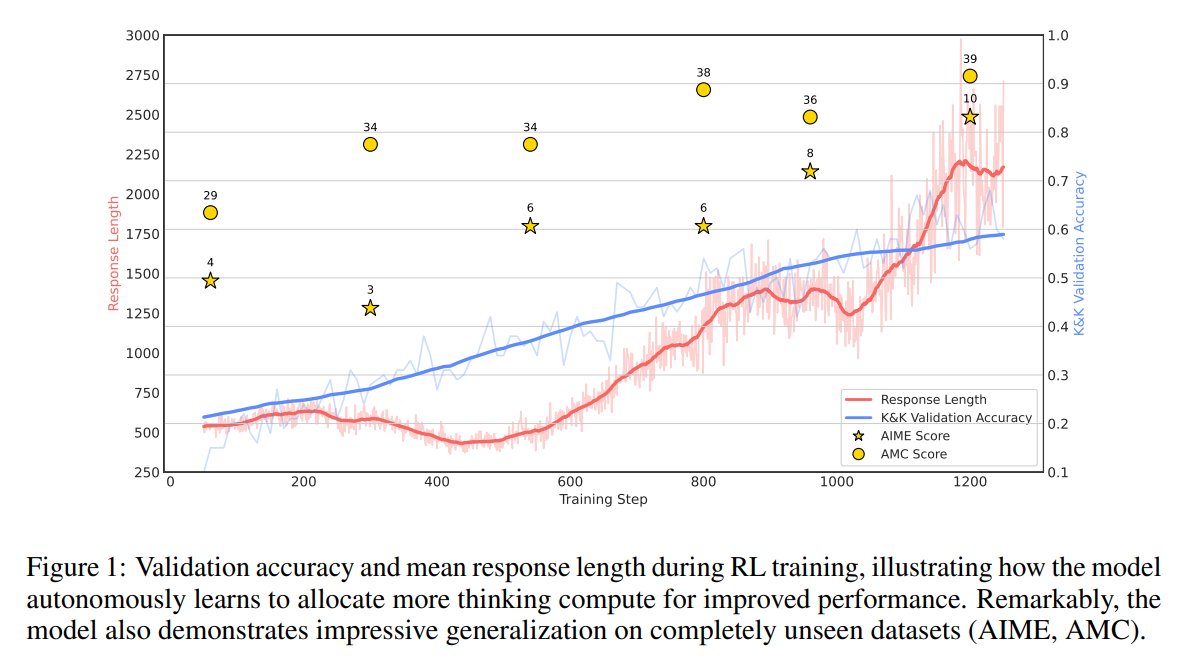
17. Discovering Highly Efficient Low-Weight Quantum Error-Correcting Codes with RL
Optimizes quantum error-correcting codes using RL, reducing physical qubit overhead
huggingface.co/papers/2502.14…
Optimizes quantum error-correcting codes using RL, reducing physical qubit overhead
huggingface.co/papers/2502.14…
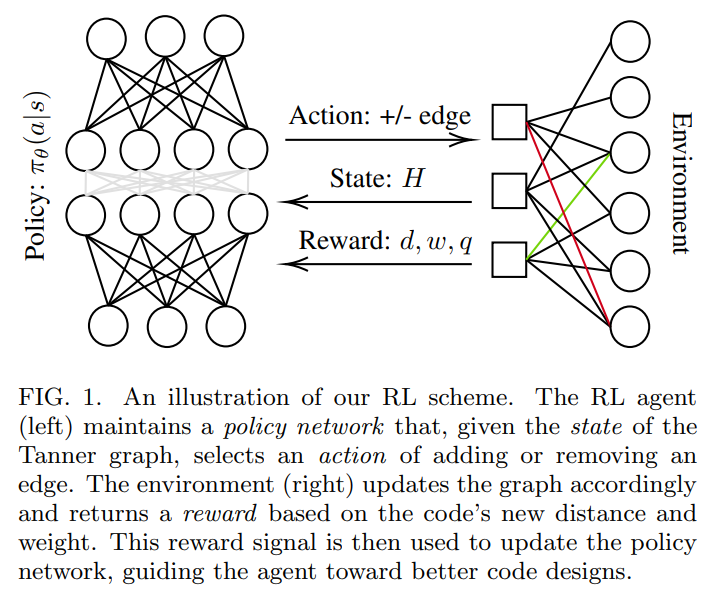
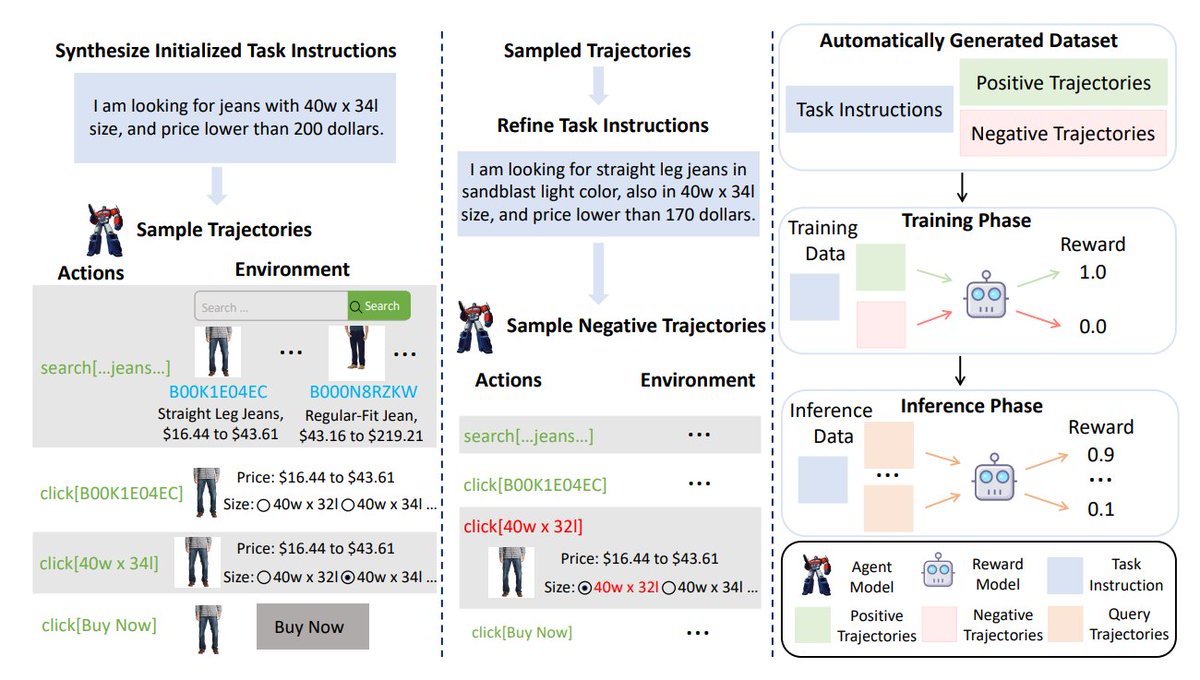
18. Armap: Scaling Autonomous Agents via Automatic Reward Modeling and Planning
Introduces a decision-making framework that learns rewards automatically, improving agent-based reasoning
huggingface.co/papers/2502.12…
Introduces a decision-making framework that learns rewards automatically, improving agent-based reasoning
huggingface.co/papers/2502.12…
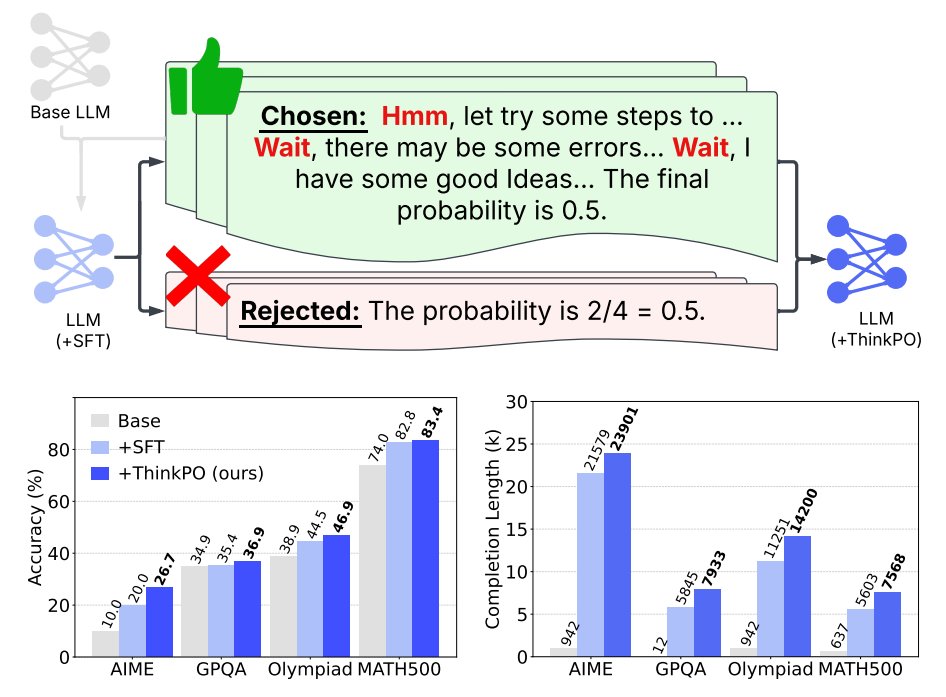
19. Thinking Preference Optimization
Enhances LLM reasoning by refining preference-based optimization of reasoning steps
huggingface.co/papers/2502.13…
Code: github.com/uservan/ThinkPO
Enhances LLM reasoning by refining preference-based optimization of reasoning steps
huggingface.co/papers/2502.13…
Code: github.com/uservan/ThinkPO
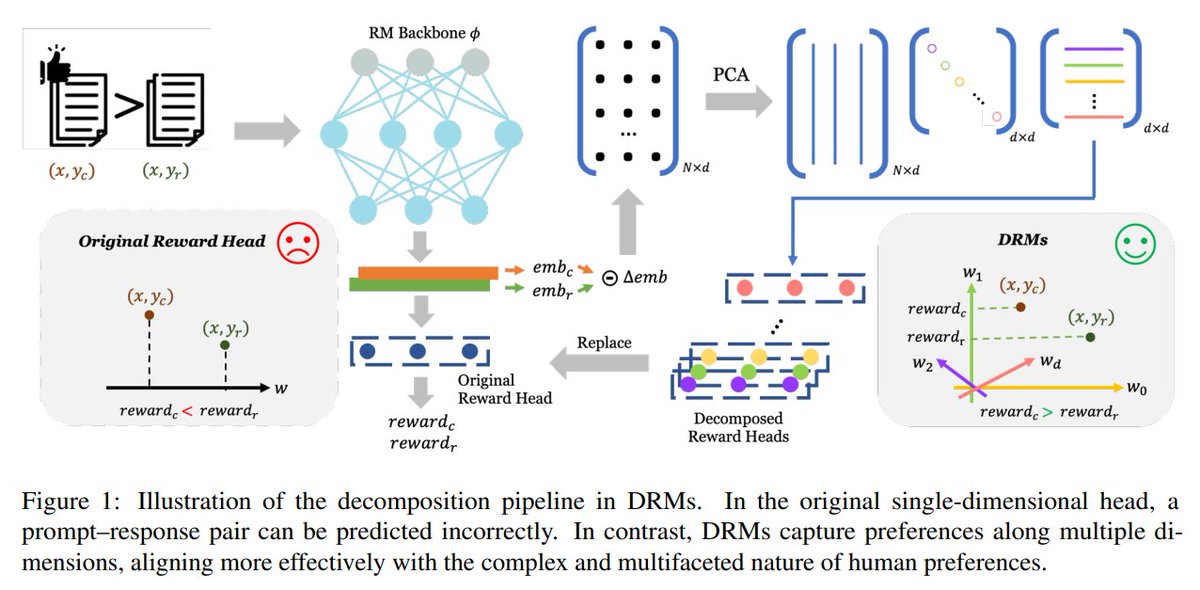
20. Rethinking Diverse Human Preference Learning through Principal Component Analysis
Improves human preference modeling using principal component analysis (PCA) for better LLM alignment
huggingface.co/papers/2502.13…
Improves human preference modeling using principal component analysis (PCA) for better LLM alignment
huggingface.co/papers/2502.13…
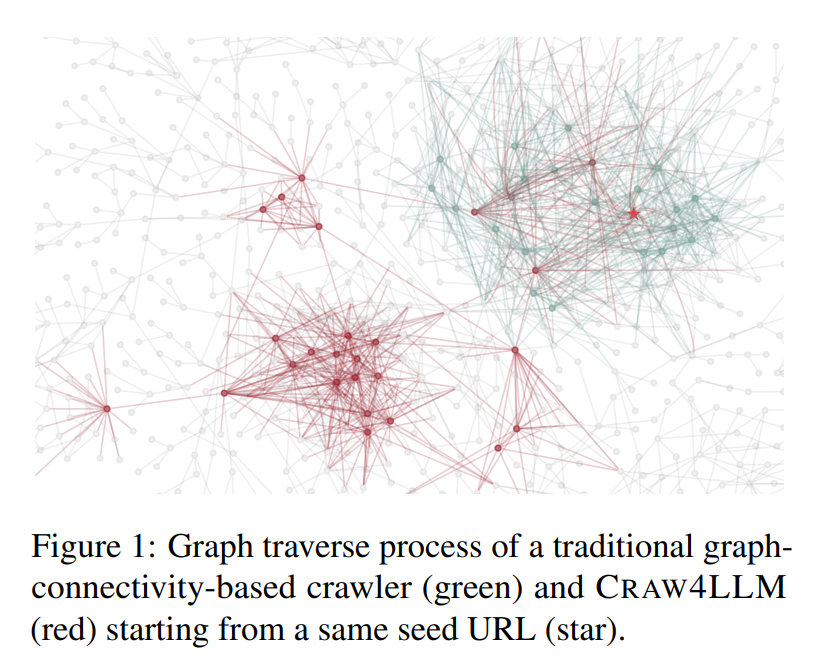
21. Craw4LLM: Efficient Web Crawling for LLM Pretraining
Optimizes web crawling for LLM training by prioritizing the most impactful pages
huggingface.co/papers/2502.13…
Code: github.com/cxcscmu/Crawl4…
Optimizes web crawling for LLM training by prioritizing the most impactful pages
huggingface.co/papers/2502.13…
Code: github.com/cxcscmu/Crawl4…
22. LLMs and Mathematical Reasoning Failures
Evaluates LLMs on newly designed math problems, exposing weaknesses in multi-step problem-solving
huggingface.co/papers/2502.11…
Evaluates LLMs on newly designed math problems, exposing weaknesses in multi-step problem-solving
huggingface.co/papers/2502.11…
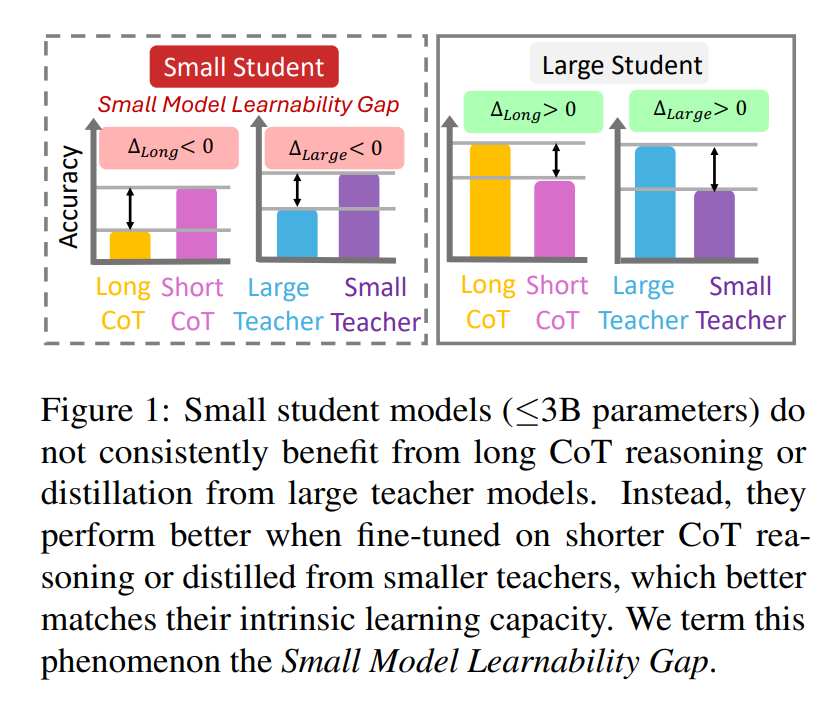
23. Small Models Struggle to Learn from Strong Reasoners
Identifies the limitations of small LLMs in benefiting from chain-of-thought distillation from larger models
huggingface.co/papers/2502.12…
Project page: small-model-gap.github.io
Identifies the limitations of small LLMs in benefiting from chain-of-thought distillation from larger models
huggingface.co/papers/2502.12…
Project page: small-model-gap.github.io
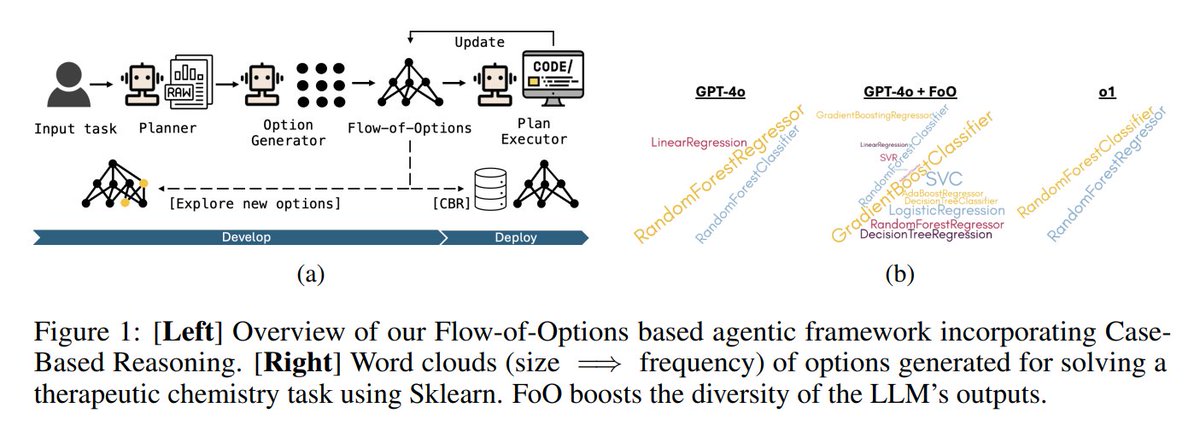
24. Flow-of-Options: Diversified and Improved LLM Reasoning by Thinking Through Options
Enhances LLM problem-solving by systematically exploring multiple solution paths
huggingface.co/papers/2502.12…
Enhances LLM problem-solving by systematically exploring multiple solution paths
huggingface.co/papers/2502.12…
Find other important AI and ML news in our free weekly newsletter: huggingface.co/blog/Kseniase/…
• • •
Missing some Tweet in this thread? You can try to
force a refresh