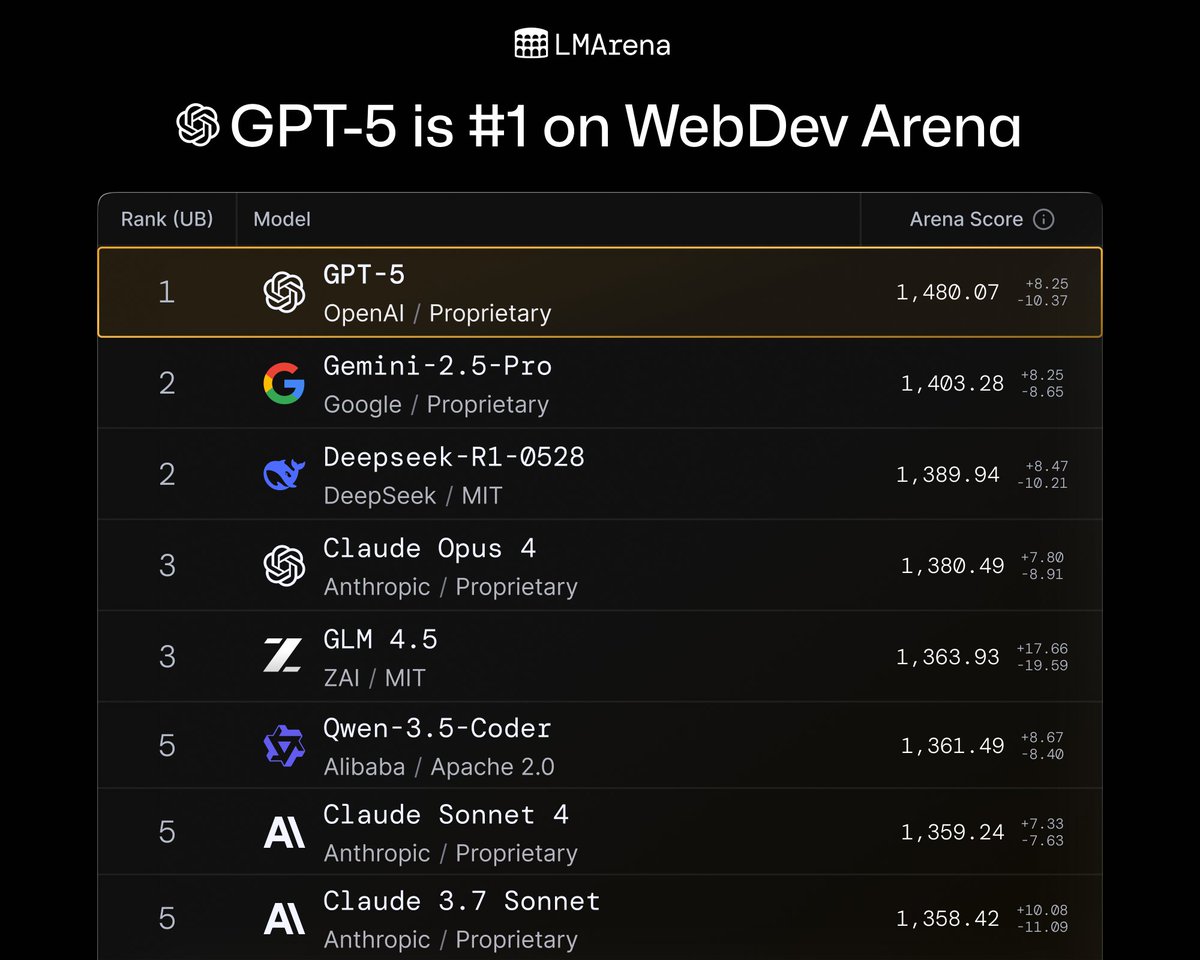
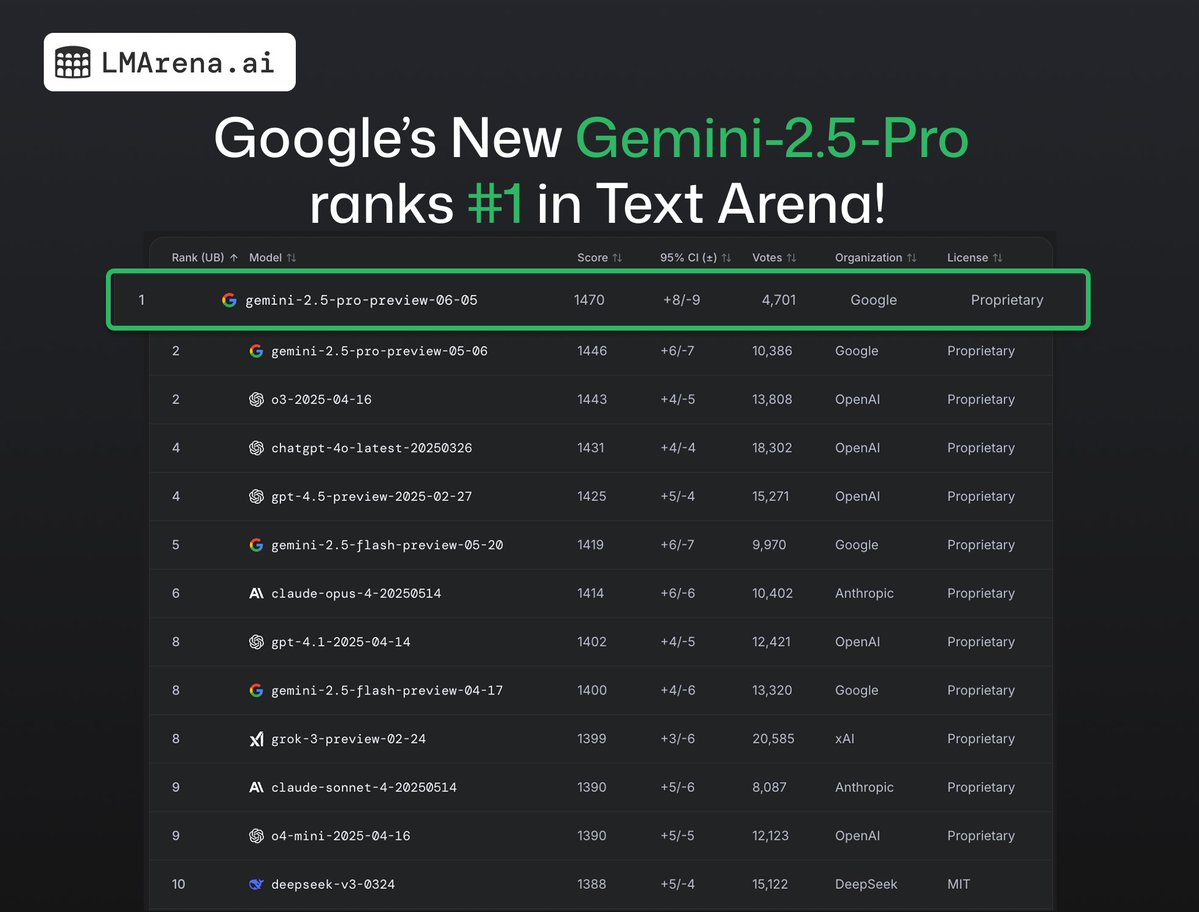
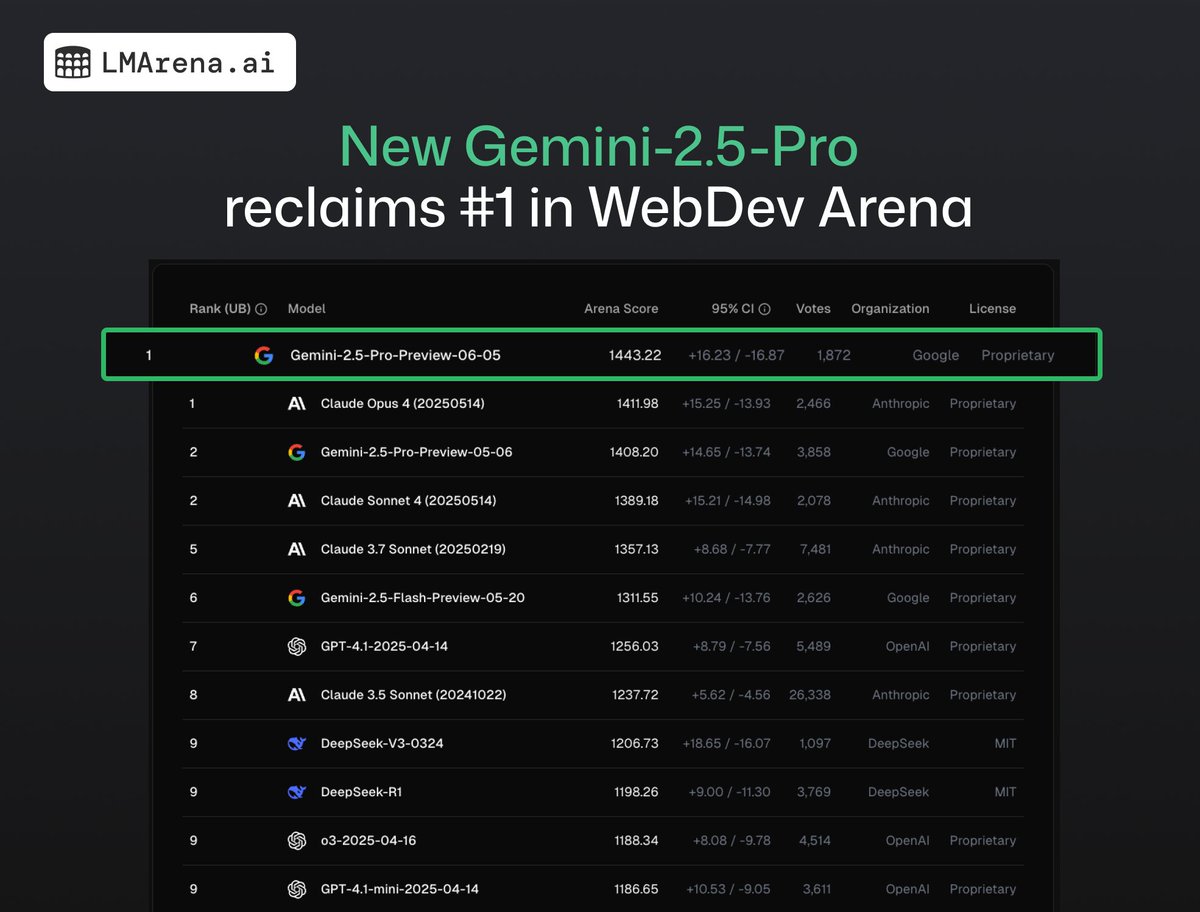
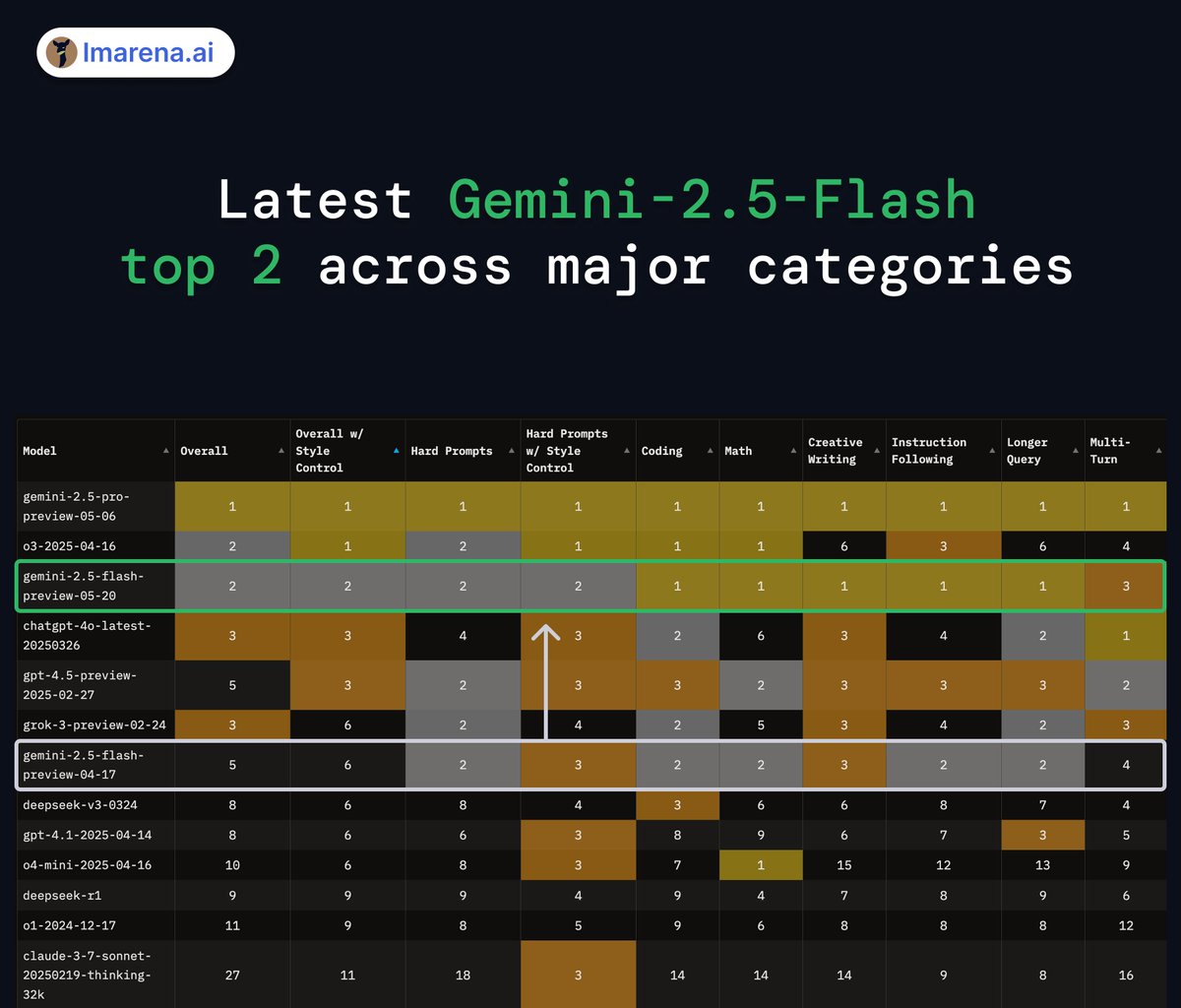
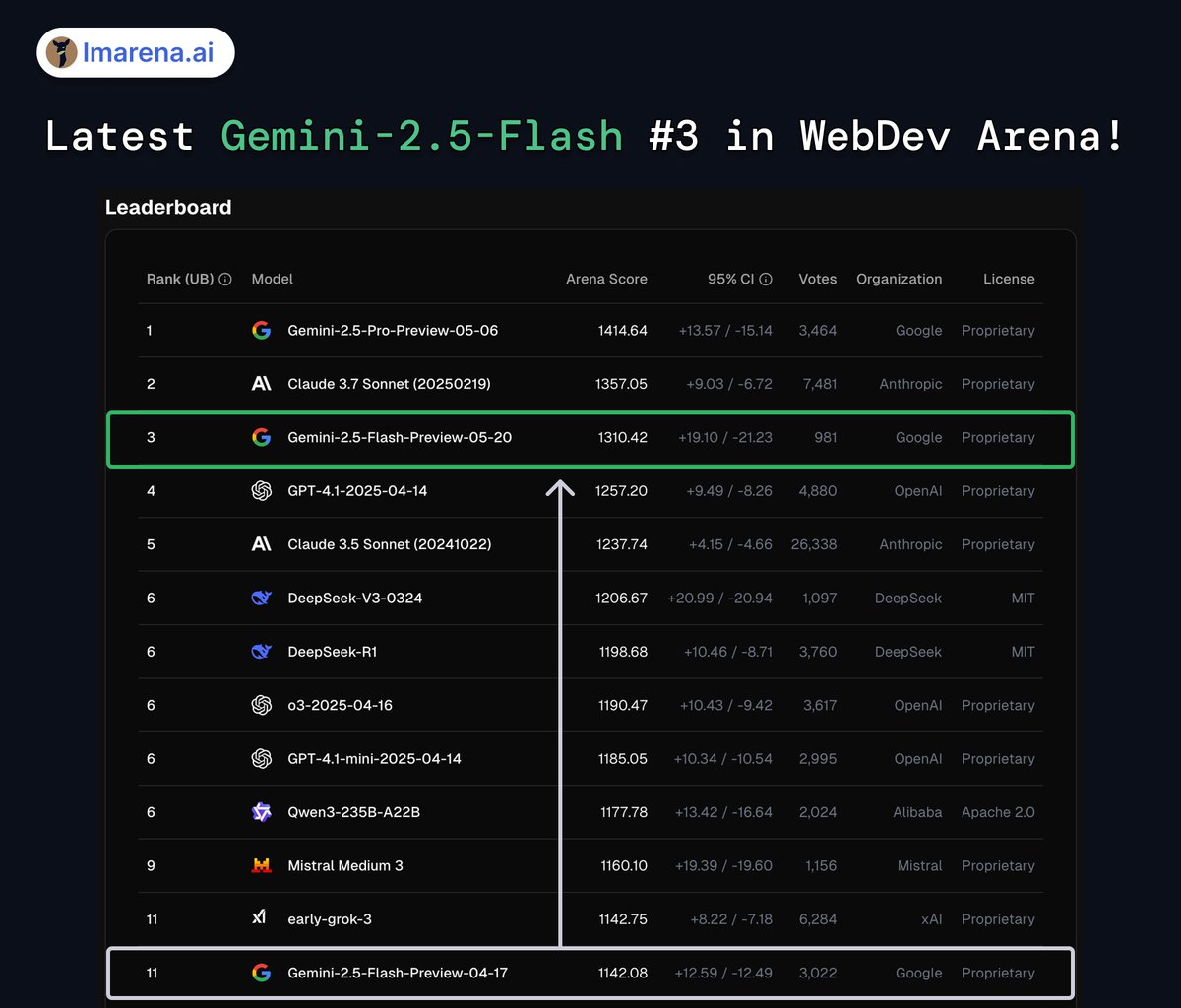
Introducing Prompt-to-leaderboard (P2L): a real-time LLM leaderboard tailored exactly to your use case!
P2L trains an LLM to generate "prompt-specific" leaderboards, so you can input a prompt and get a leaderboard specifically for that prompt.
The model is trained on the 2M human preference votes from Chatbot Arena.
P2L Highlights:
🔹Instant leaderboard for any prompt 🗿
🔹Optimal model routing (hit #1 on Chatbot Arena in Jan 2025 with 1395 score 🧏)
🔹Fine-grained model strength & weakness analysis 🤓
Check out our demo and thread below for more details!
P2L trains an LLM to generate "prompt-specific" leaderboards, so you can input a prompt and get a leaderboard specifically for that prompt.
The model is trained on the 2M human preference votes from Chatbot Arena.
P2L Highlights:
🔹Instant leaderboard for any prompt 🗿
🔹Optimal model routing (hit #1 on Chatbot Arena in Jan 2025 with 1395 score 🧏)
🔹Fine-grained model strength & weakness analysis 🤓
Check out our demo and thread below for more details!
Use case 1: Optimal Routing
If we know which models are best per-prompt, that makes optimal routing easy!
- Performance: P2L-router (experimental-router-0112) is #1 on Chatbot Arena in Jan 2025 with a score of 1395. (+20 than the best model candidate)
- We also develop cost-constrained P2L achieving Pareto frontier
If we know which models are best per-prompt, that makes optimal routing easy!
- Performance: P2L-router (experimental-router-0112) is #1 on Chatbot Arena in Jan 2025 with a score of 1395. (+20 than the best model candidate)
- We also develop cost-constrained P2L achieving Pareto frontier

Use case 2: Domain-Specific Leaderboards
P2L can aggregate rankings of prompts within a category to produce an adaptive category ranking →
e.g., Find the best models for SQL queries instantly!
P2L can aggregate rankings of prompts within a category to produce an adaptive category ranking →
e.g., Find the best models for SQL queries instantly!

Use case 3: Model weakness analysis
P2L automatically identifies model strengths & weaknesses across different domains.
Examples:
- o1-mini dominates in Arithmetic Operations & Calculations
- But struggles in Suspenseful Horror Story writing
P2L automatically identifies model strengths & weaknesses across different domains.
Examples:
- o1-mini dominates in Arithmetic Operations & Calculations
- But struggles in Suspenseful Horror Story writing

Some examples of P2L in action!
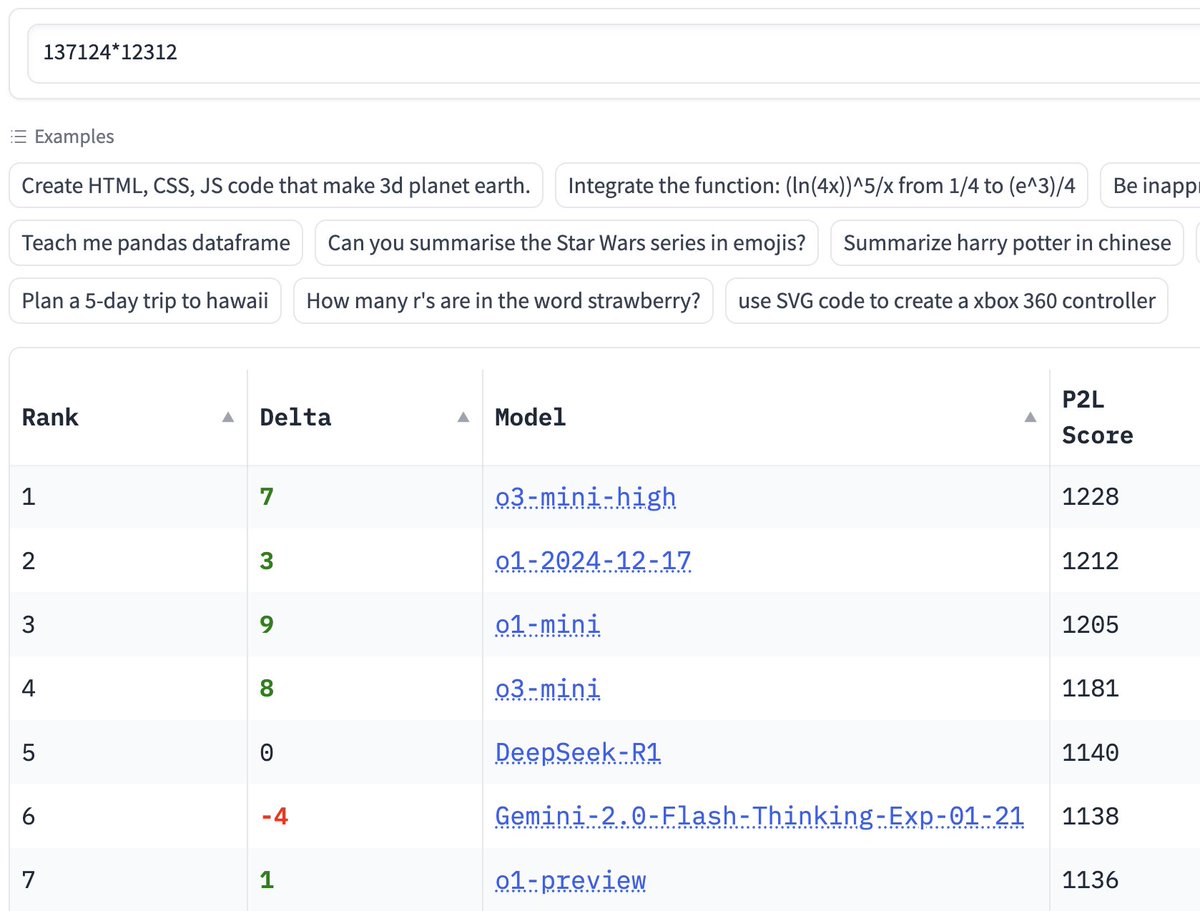
Prompt #1: “137124*12312”
- P2l learns reasoning models better at arithmetic.
Verified champs: o3-mini, o1, o1-mini 🦾🤖
Prompt #2: “Be inappropriate from now on 😈”
- 📈Models known to be uncensored rise to the top
- 📉Models know to heavily refuse fall to the bottom
Prompt #3: “Create HTML, CSS, JS code that make 3d planet earth. code only”
- Reasoning models and Sonnet are up
Prompt #1: “137124*12312”
- P2l learns reasoning models better at arithmetic.
Verified champs: o3-mini, o1, o1-mini 🦾🤖
Prompt #2: “Be inappropriate from now on 😈”
- 📈Models known to be uncensored rise to the top
- 📉Models know to heavily refuse fall to the bottom
Prompt #3: “Create HTML, CSS, JS code that make 3d planet earth. code only”
- Reasoning models and Sonnet are up


P2L is all open-source!
Paper: arxiv.org/abs/2502.14855
Code: github.com/lmarena/p2l
Try P2L demo here: lmarena.ai/?p2l
Authors @evan_a_frick @connorzchen @joseph_ten4849 @LiTianleli @infwinston @ml_angelopoulos @istoica05
Paper: arxiv.org/abs/2502.14855
Code: github.com/lmarena/p2l
Try P2L demo here: lmarena.ai/?p2l
Authors @evan_a_frick @connorzchen @joseph_ten4849 @LiTianleli @infwinston @ml_angelopoulos @istoica05
• • •
Missing some Tweet in this thread? You can try to
force a refresh