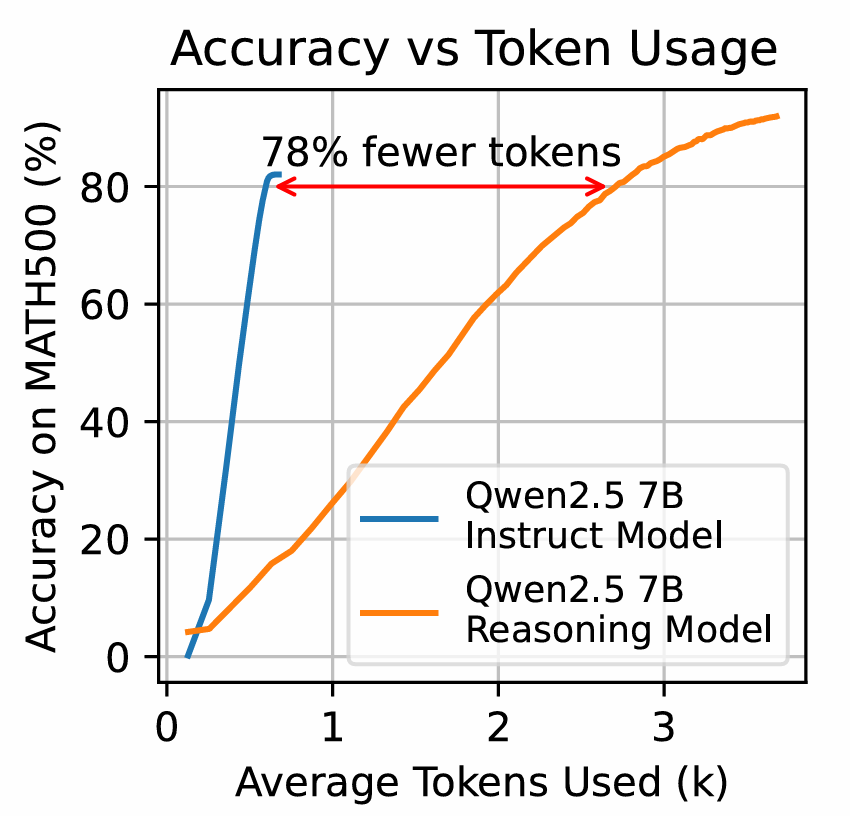
Claude-3.7 was tested on Pokémon Red, but what about more real-time games like Super Mario 🍄🌟?
We threw AI gaming agents into LIVE Super Mario games and found Claude-3.7 outperformed other models with simple heuristics. 🤯
Claude-3.5 is also strong, but less capable of planning complex maneuvers. Gemini-1.5-pro and GPT-4o perform less well.
We threw AI gaming agents into LIVE Super Mario games and found Claude-3.7 outperformed other models with simple heuristics. 🤯
Claude-3.5 is also strong, but less capable of planning complex maneuvers. Gemini-1.5-pro and GPT-4o perform less well.
We built Gaming agents to run platformers and puzzle video games in real time. Check out our demos and try our repo yourself to customize your own gaming agent! 🎮
In addition to Super Mario Bros, we also support 2048, as well as Tetris. More games are coming soon! 👾github.com/lmgame-org/Gam…
In addition to Super Mario Bros, we also support 2048, as well as Tetris. More games are coming soon! 👾github.com/lmgame-org/Gam…
In addition to the classics, our LMGames team also designs and hosts computer games for AI evaluations.
Our mission is to study new perspectives for AI evaluations and the evolving roles humans play in evaluations.
We believe games provide challenging and dynamic environments for testing LLM agents.
Checkout our released Roblox game as well as the leaderboard: lmgame.org/#/blog/ai_spac…
More information at: lmgame.org
Our mission is to study new perspectives for AI evaluations and the evolving roles humans play in evaluations.
We believe games provide challenging and dynamic environments for testing LLM agents.
Checkout our released Roblox game as well as the leaderboard: lmgame.org/#/blog/ai_spac…
More information at: lmgame.org
• • •
Missing some Tweet in this thread? You can try to
force a refresh