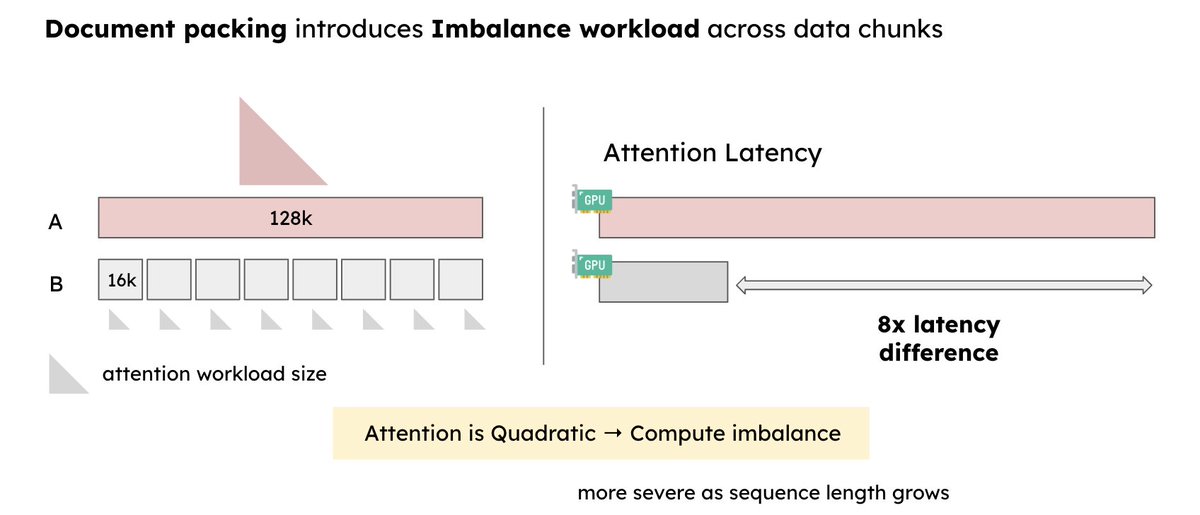
Training a long-context LLM model can suffer from severe workload imbalance caused by core-attention - the softmax(QK^T)V part.
Core-attention disaggregation (CAD) fundamentally eliminates workload imbalance by disaggregating core-attention from the rest of the model.
Long-context LLM training suffers from severe workload imbalance across GPUs.
Modern training systems use document packing to pack documents with different lengths into the same batch to save memory and increase compute utilization.
However, documents with variable lengths will have imbalanced CA computation, and such variance can cause batches to have drastically different compute workload.
Nov 19, 2025 • 6 tweets • 3 min read
(1/N) 🚀 We converted a high quality Wan2.2-MoE into an autoregressive model.
Preview checkpoint: huggingface.co/FastVideo/Caus…
- First autoregressive version of Wan2.2-A14B MoE
- I2V compatible
- 8-step distilled
- Potential backbone for streaming generation and world modeling
It is simply because Wan2.2 MoE is the best open source video model.
This is enabled by a neat MoE twist: instead of FFN experts, it has two diffusion transformer experts.
- High-noise expert: early steps → global structure & motion
- Low-noise expert: late steps → details & crispness
- Higher quality and motion compared to Wan2.1
Where the early steps correspond to all timesteps greater than or equal to some boundary timestep b and the late steps correspond to the rest!
(image from Wan2.2)
Sep 23, 2025 • 6 tweets • 4 min read
[1/N]🚀New decoding paradigm drop!🚀
Introducing Lookahead Reasoning(LR): step-level speculation that stacks with Speculative Decoding(SD).
It has been accepted to #NeurIPS2025 🎉
📖 Blog: hao-ai-lab.github.io/blogs/lookahea…
💻 Code: github.com/hao-ai-lab/Loo…
📄 Paper: arxiv.org/abs/2506.19830
[2/N]Token-level SD gives speedups, but it hits a ceiling: 1. Long drafts fail -> low acc. rates 2. Wrong drafts waste compute 3. Overhead grows
Even with powerful GPUs (H200, B200, Rubin), SD alone can’t fully use the FLOPs.
👉 We need to go beyond tokens to steps.
Apr 15, 2025 • 6 tweets • 4 min read
When Ilya Sutskever once explained why next-word prediction leads to intelligence, he made a metaphor: if you can piece together the clues and deduce the criminal’s name on the last page, you have a real understanding of the story. 🕵️♂️
Inspired by that idea, we turned to Ace Attorney to test AI's reasoning. It’s the perfect stage: the AI plays as a detective to collect clues, expose contradictions, and uncover the truth.
We put the latest top AI models—GPT-4.1, Gemini 2.5 Pro, Llama-4 Maverick, and more—to the test in Ace Attorney, to see if they could shout Objection! ⚖️, turn the case around, and uncover the truth behind the lies.
Phoenix Wright Ace Attorney is a popular visual novel known for its complex storytelling and courtroom drama. Like a detective novel, it challenges players to connect clues and evidence to expose contradictions and reveal the true culprit.
In our setup, models are tested on the intense cross-examination stage. It must spot contradictions and present the correct evidence to challenge witness testimony. Each level grants 5 lives, allowing limited tolerance for mistakes.
Apr 8, 2025 • 4 tweets • 2 min read
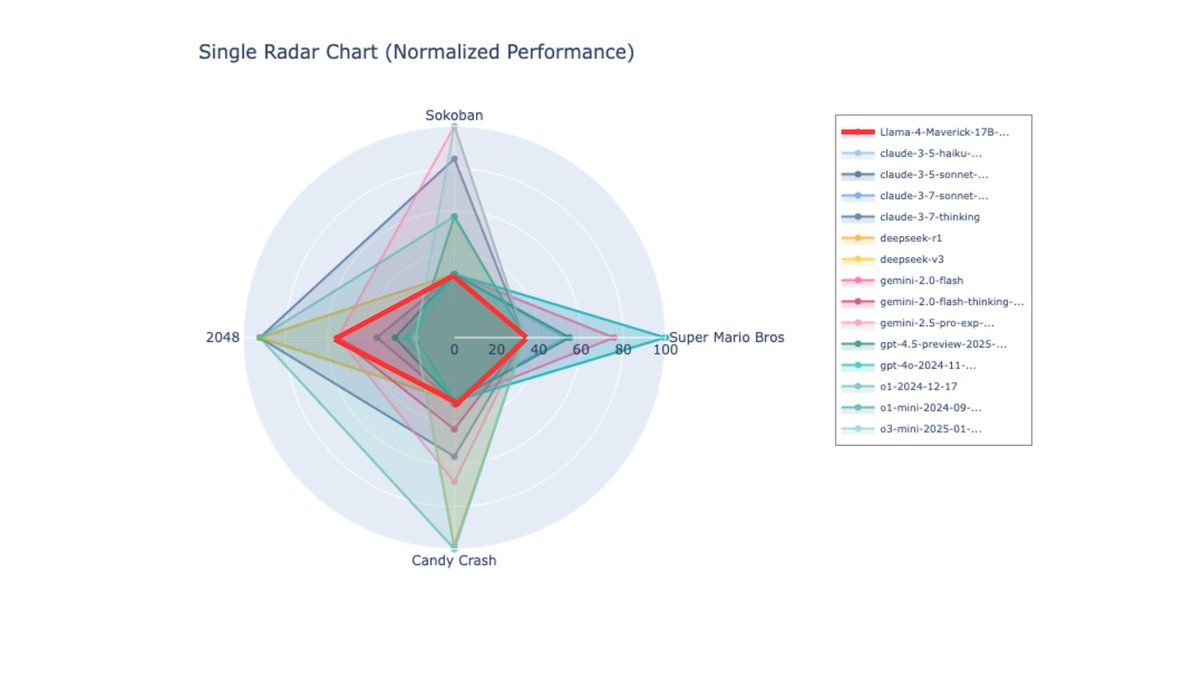
LLaMA-4 Maverick performs well on reasoning benchmarks and ranks 2nd on the Chatbot Arena, yet its true performance remains controversial. What if we put them in a transparent gaming environment? 🎮 Our benchmark tells a different story...🤔
Will true intelligence shine through play? Let’s find out 👇
We directly compared LLaMA-4 Maverick with its reported peers.
Despite of LLaMA-4’s strong performance on static benchmarks, in 2048, DeepSeek V3 still outperforms LLaMA-4, reaching a tile value of 256, whereas LLaMA-4 only reaches 128, the same as a random move algorithm.
In Candy Crush and Sokoban, which demand spatial reasoning capability, LLaMA 4 struggles and fails to crack the first level in both 🧩.
Checkout our leaderboard for more detailed results!
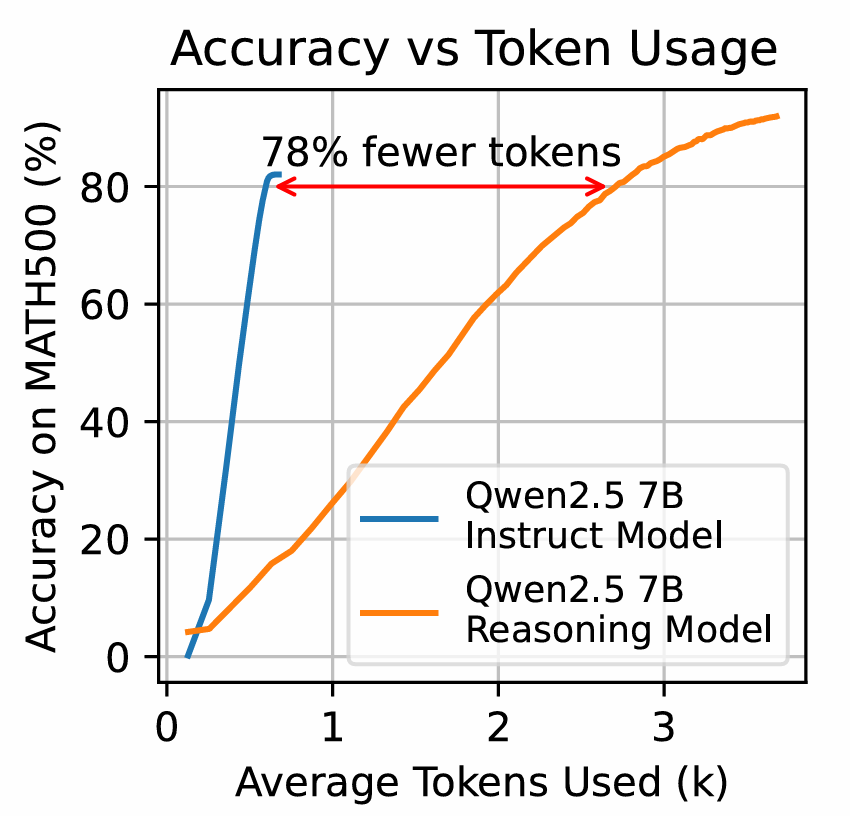
Reasoning models often waste tokens self-doubting.
Dynasor saves you up to 81% tokens to arrive at the correct answer! 🧠✂️
- Probe the model halfway to get the certainty
- Use Certainty to stop reasoning
- 100% Training-Free, Plug-and-play
🎮Demo: hao-ai-lab.github.io/demo/dynasor-c…
[2/n] Observation: Reasoning models (🟠) use WAY more tokens than needed vs traditional models (🔵).
Although reasoning models achieve higher acc%, they consume much more tokens than traditional models. User who can accept a lower acc% will waste tons more money💰💰.