When will AI systems be able to carry out long projects independently?
In new research, we find a kind of “Moore’s Law for AI agents”: the length of tasks that AIs can do is doubling about every 7 months.
In new research, we find a kind of “Moore’s Law for AI agents”: the length of tasks that AIs can do is doubling about every 7 months.

At a high level, our method is simple:
1. We ask both skilled humans and AI systems to attempt tasks in similar conditions.
2. We measure how long the humans take.
3. We then measure how AI success rates vary depending on how long the humans took to do those tasks.
1. We ask both skilled humans and AI systems to attempt tasks in similar conditions.
2. We measure how long the humans take.
3. We then measure how AI success rates vary depending on how long the humans took to do those tasks.

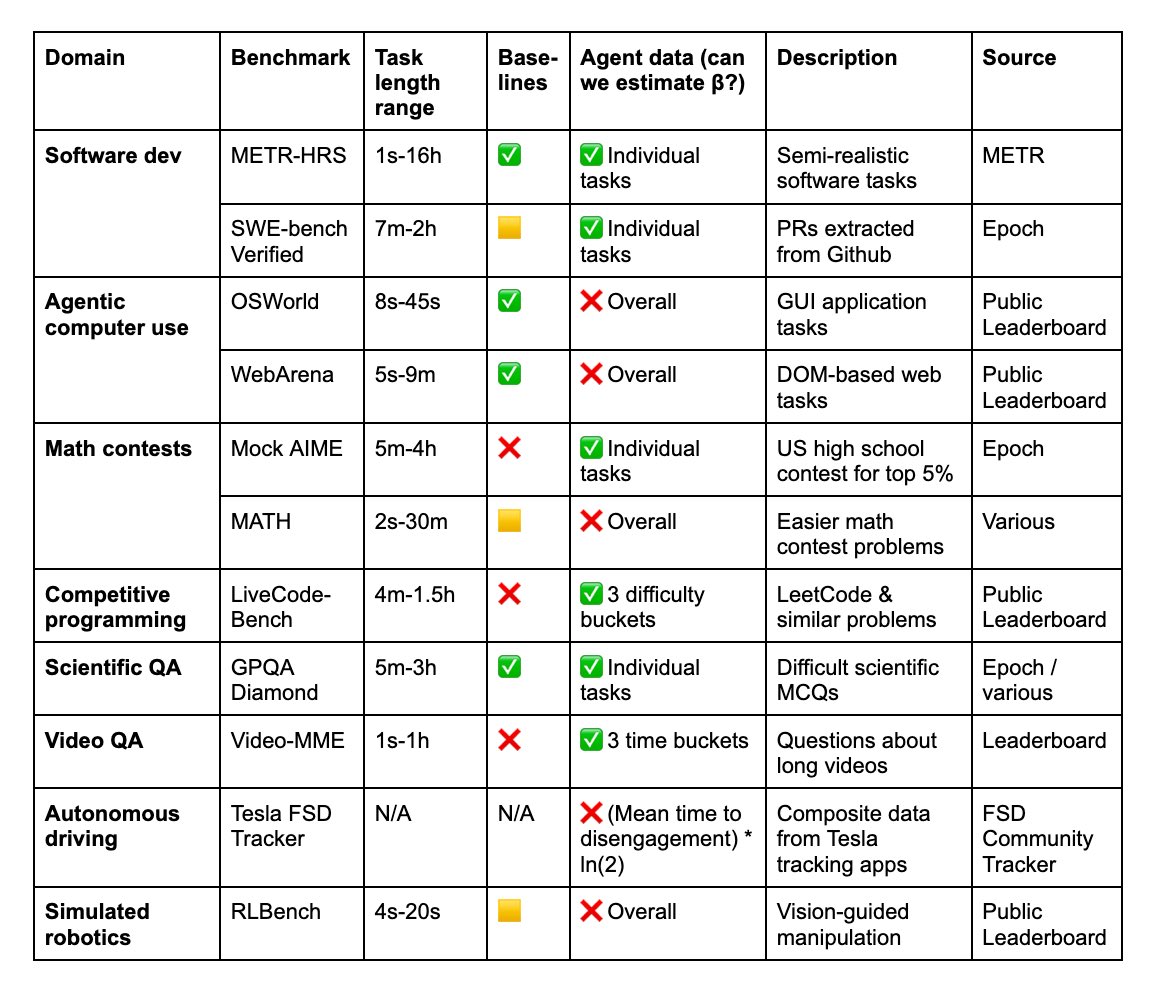
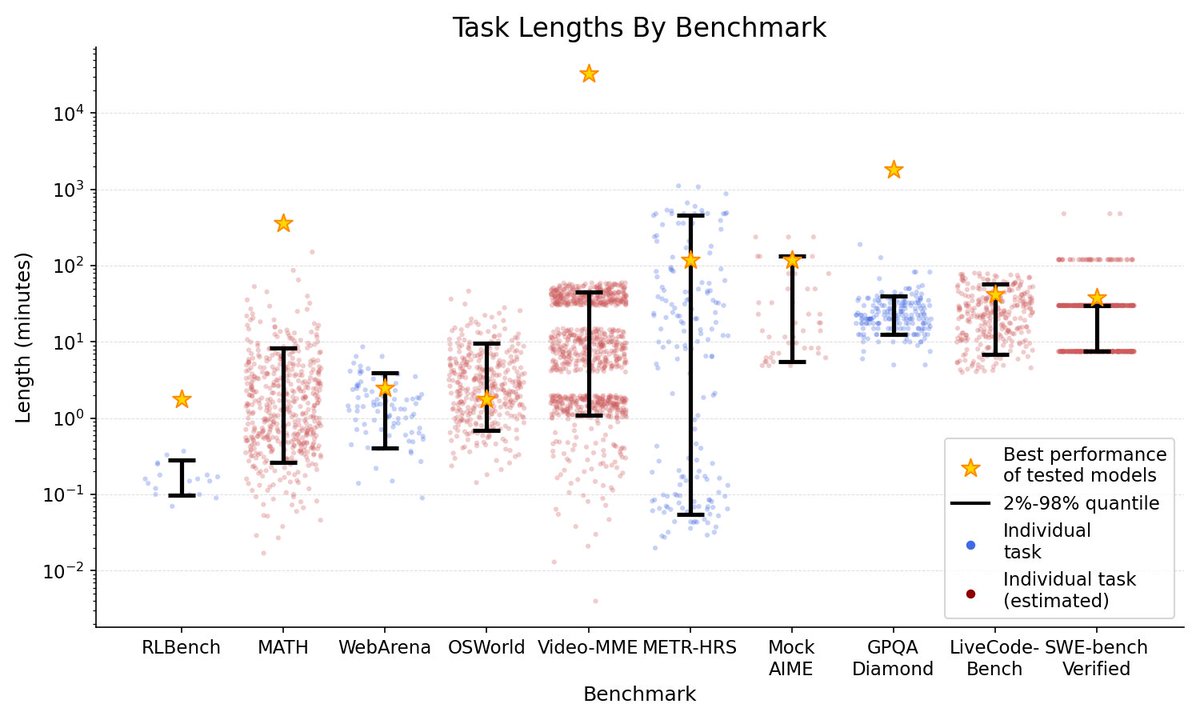
We measure human and AI performance on a variety of software tasks, some sourced from existing METR benchmarks like HCAST and some brand new.
Human completion times on these tasks range from 1 second to 16 hours.
Human completion times on these tasks range from 1 second to 16 hours.
https://twitter.com/idavidrein/status/1901647558839353363
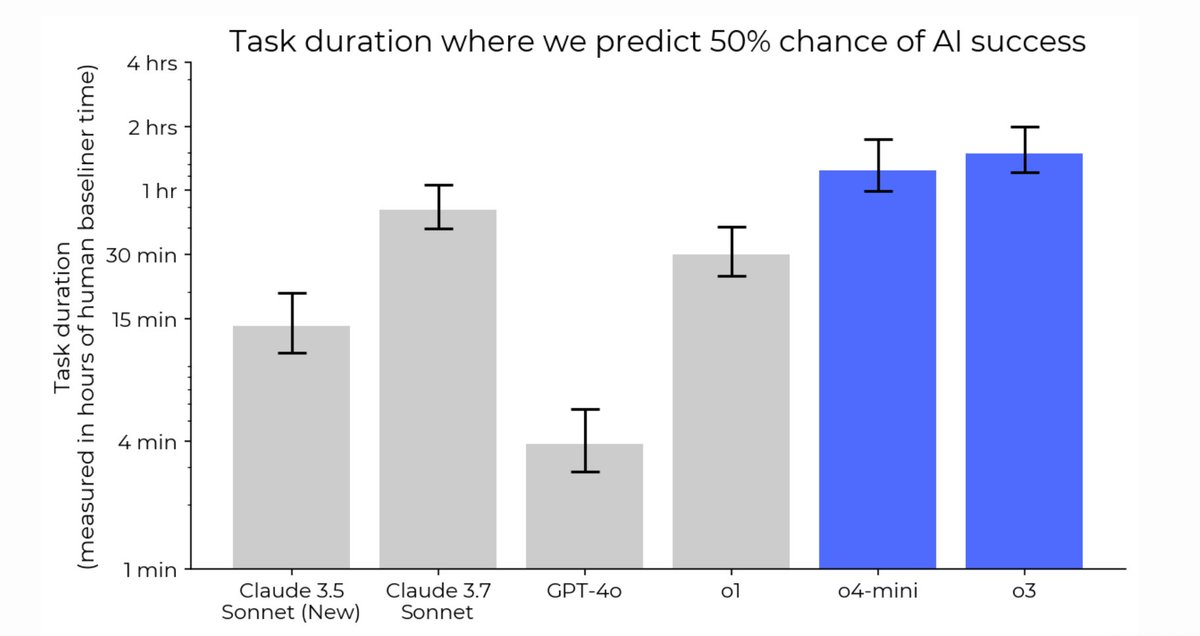
We then fit a curve that predicts the success rate of an AI based on how long it took humans to do each task. This curve characterizes how capable an AI is at different task lengths. We then summarize the curve with the task length at which a model’s success rate is 50%.

This metric - the 50% task completion time horizon - gives us a way to track progress in model autonomy over time.
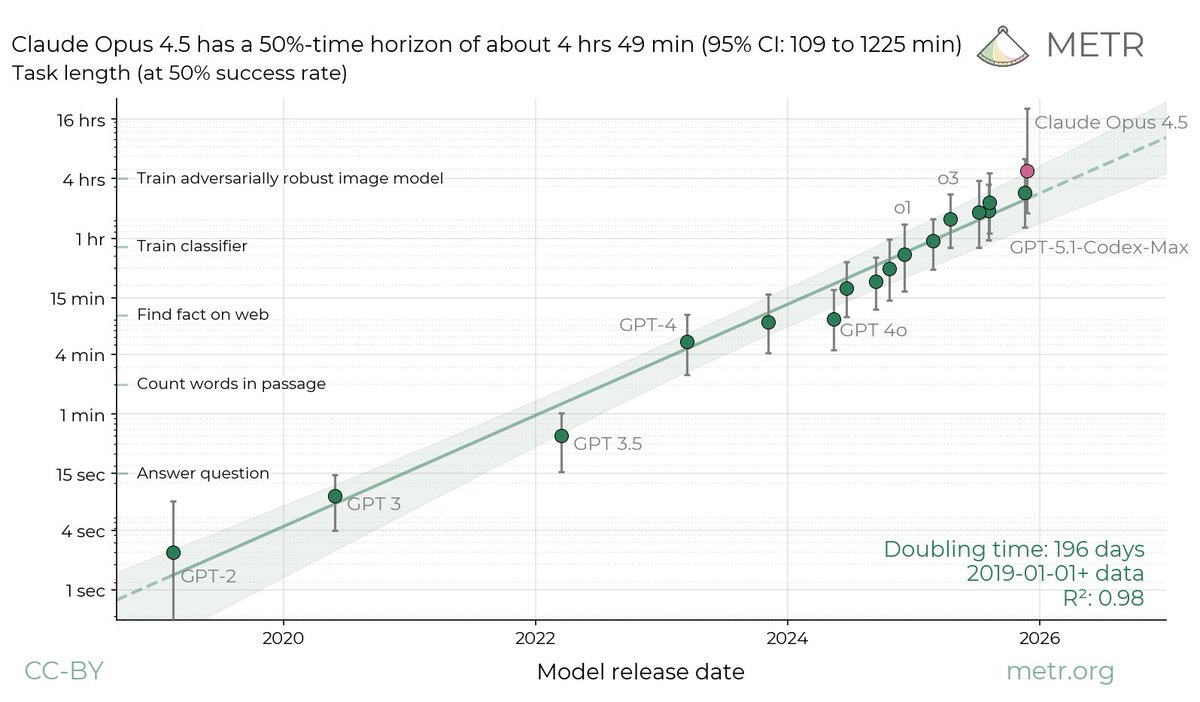
Plotting the historical trend of 50% time horizons across frontier AI systems shows exponential growth.
Plotting the historical trend of 50% time horizons across frontier AI systems shows exponential growth.

These results appear robust. Although our model could be wrong, we are relatively confident about its fit to the data. While our initial data only covered the most recent systems, we found we could retrodict back to GPT-2.


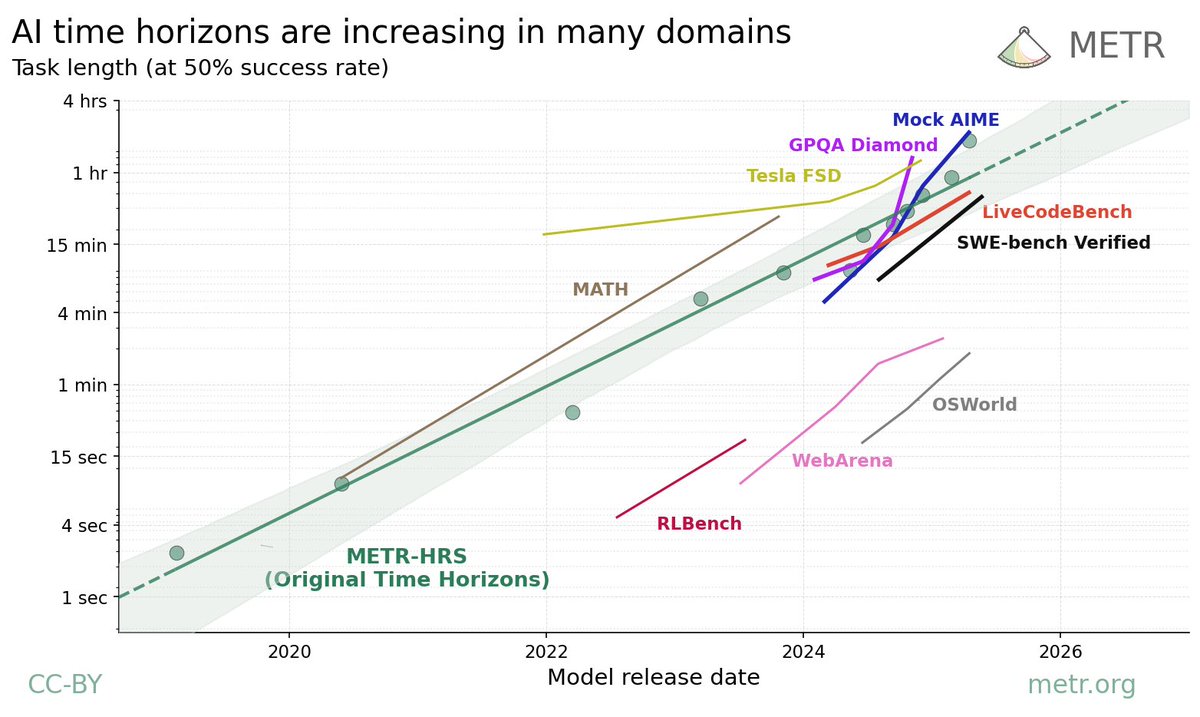
We ran experiments on SWE-bench Verified and found a similar trend. We also ran a small experiment on internal METR pull requests, and found results consistent with our other datasets. We are excited for researchers to extend this and measure time horizons on other benchmarks.

We are fairly confident in the rough trend of 1-4 doublings in horizon length per year. That is fast! Measures like these help make the notion of “degrees of autonomy” more concrete and let us quantify when AI abilities may rise above specific useful (or dangerous) thresholds.
https://twitter.com/richardmcngo/status/1643310525697105935
We give more high-level information about these results and what they might imply on the METR blog: metr.org/blog/2025-03-1…
For the details, read “Measuring AI Ability to Complete Long Tasks,” now on available on arXiv: arxiv.org/abs/2503.14499
If you are interested in contributing to more research like this, on quantitative evaluation of frontier AI capabilities: METR is hiring!
hiring.metr.org
hiring.metr.org
• • •
Missing some Tweet in this thread? You can try to
force a refresh