
We work to scientifically measure whether and when AI systems might threaten catastrophic harm to society. Nonprofit.
 Expenditure horizon requires us to estimate human performance as a function of cost, but lets us compare humans and agents fairly when the cost of experimental compute or agent tokens is significant. We can use it to e.g. quantify model progress over time:
Expenditure horizon requires us to estimate human performance as a function of cost, but lets us compare humans and agents fairly when the cost of experimental compute or agent tokens is significant. We can use it to e.g. quantify model progress over time: 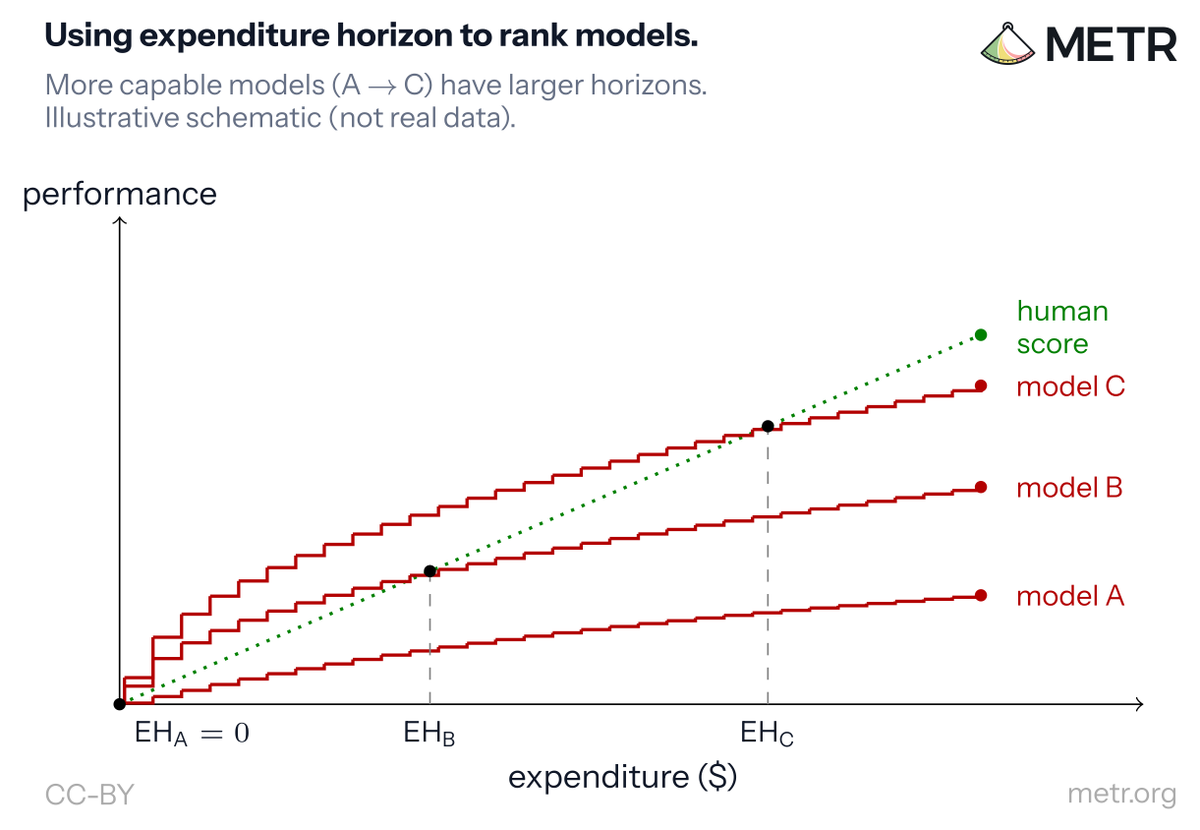
 We created private reports for each participating company based on our model evaluations and analysis. Participants could then approve what non-public evidence we could disclose in our public report, but had no editorial control.
We created private reports for each participating company based on our model evaluations and analysis. Participants could then approve what non-public evidence we could disclose in our public report, but had no editorial control. 
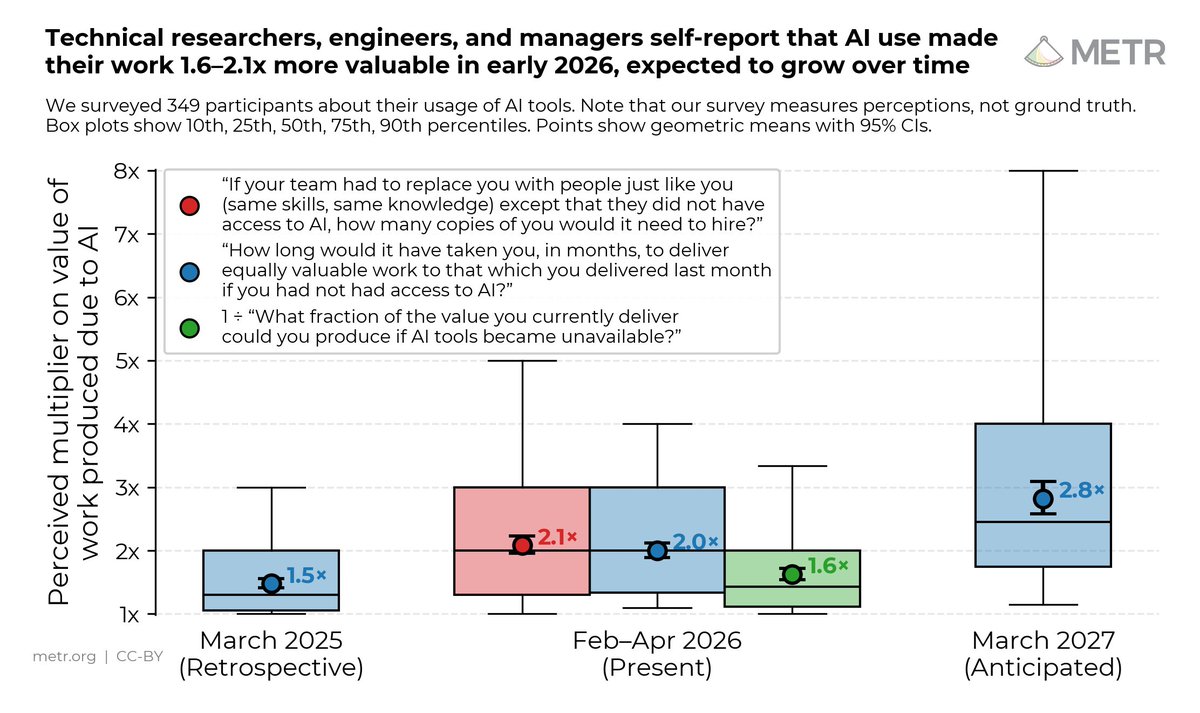 Surveys are fast and cheap to run, and can be directly focused on answering whatever questions we care most about. However, self-reports are known to be potentially unreliable.
Surveys are fast and cheap to run, and can be directly focused on answering whatever questions we care most about. However, self-reports are known to be potentially unreliable.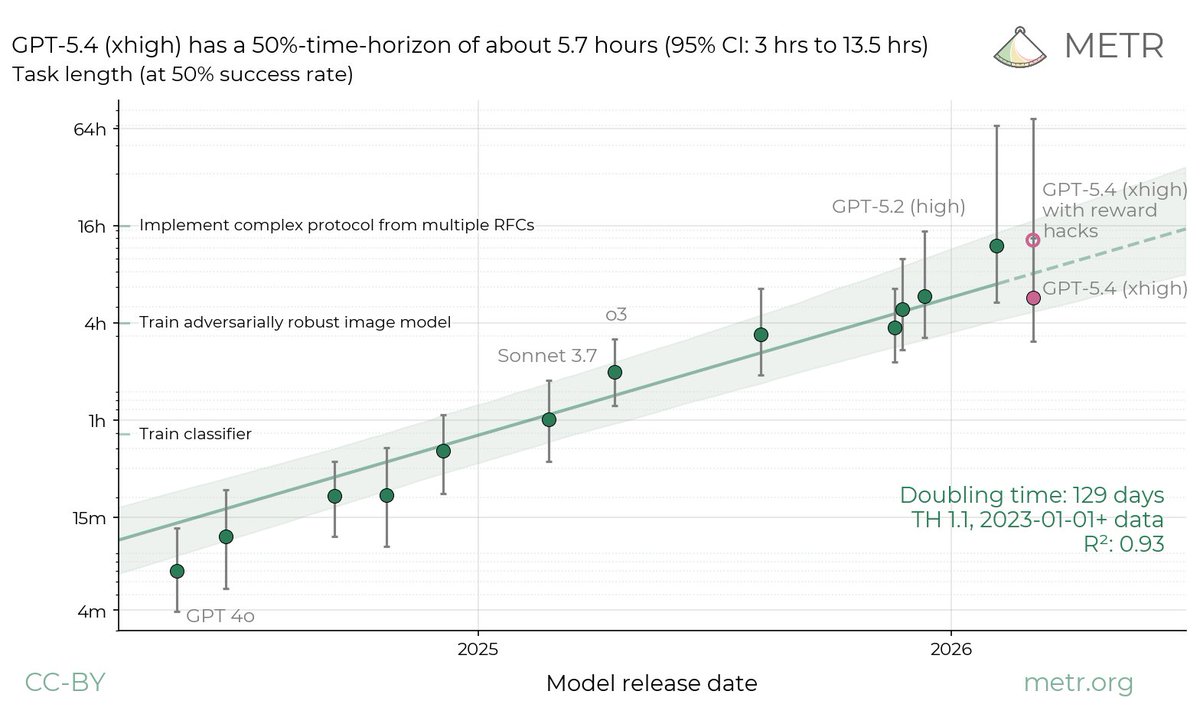 In our measurements, whenever a model succeeds on a task by reward-hacking, we consider the attempt a failure. Following this same policy, we arrived at a point estimate of 5.7hrs (95% CI of 3hrs to 13.5hrs) for GPT-5.4’s time horizon.
In our measurements, whenever a model succeeds on a task by reward-hacking, we consider the attempt a failure. Following this same policy, we arrived at a point estimate of 5.7hrs (95% CI of 3hrs to 13.5hrs) for GPT-5.4’s time horizon.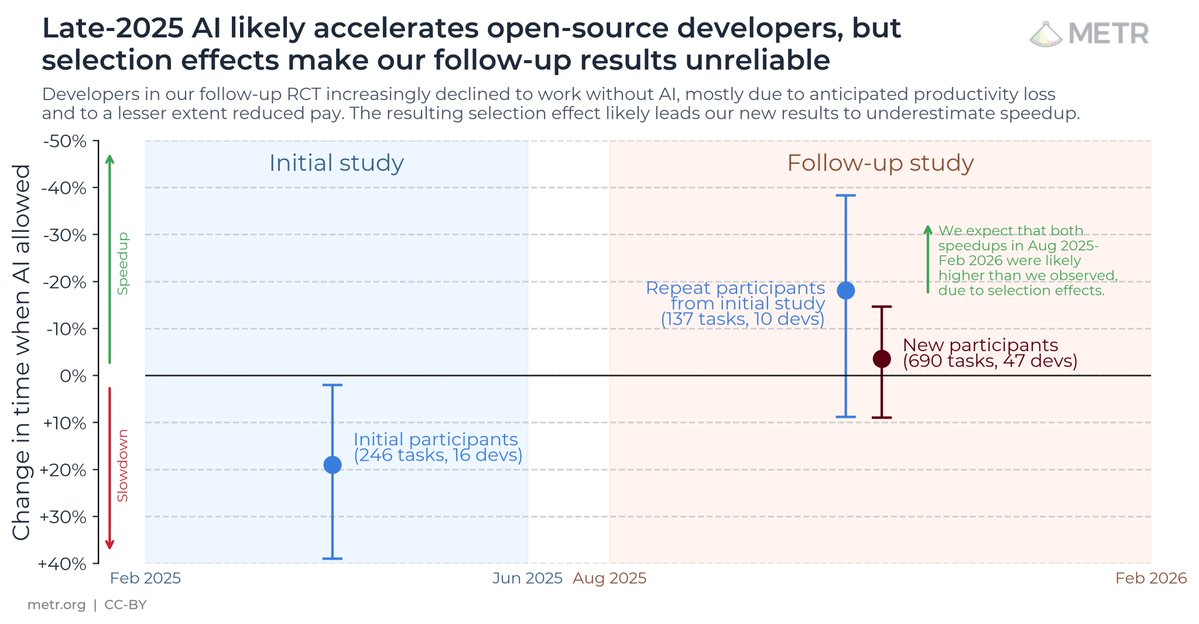 Last year we published findings that AI tools caused a 20% slowdown among experienced open source developers, using data collected over February to June 2025. We still believe that estimate was accurate for the specific tools and population at the time.
Last year we published findings that AI tools caused a 20% slowdown among experienced open source developers, using data collected over February to June 2025. We still believe that estimate was accurate for the specific tools and population at the time.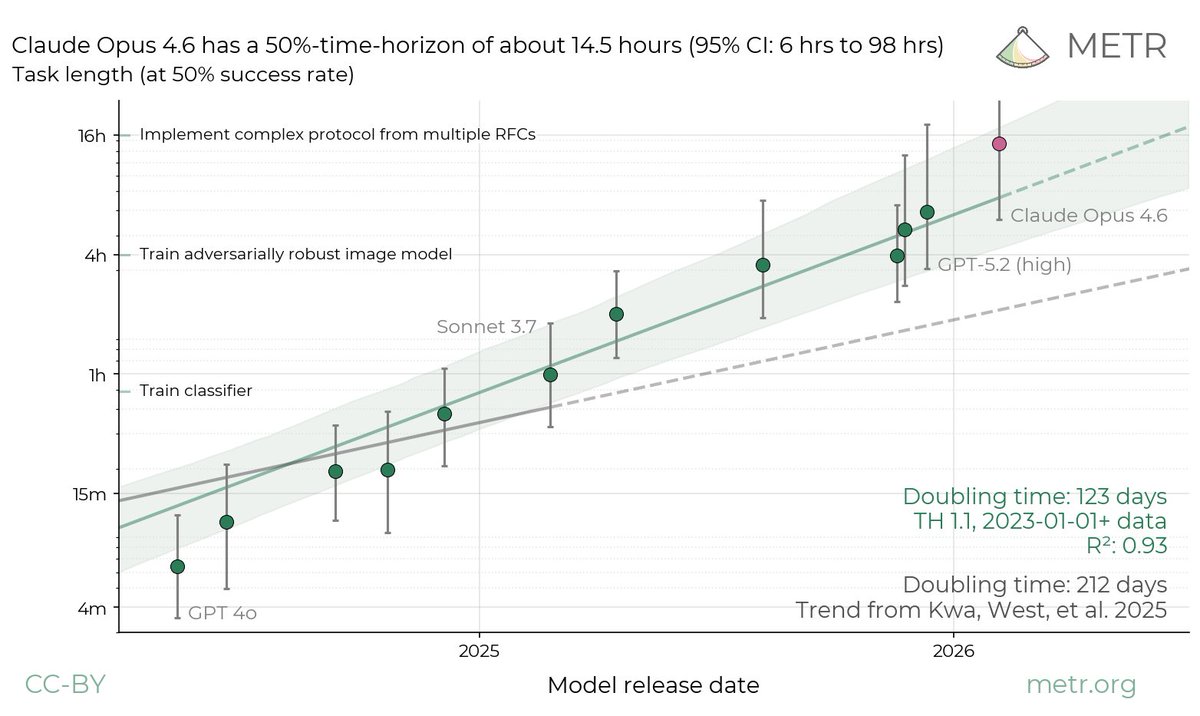 Near-saturation of the task suite can have unintuitive consequences for the time-horizon estimates. For example, the upper bound of the 95% CI is much longer than any of the tasks used for the measurement.
Near-saturation of the task suite can have unintuitive consequences for the time-horizon estimates. For example, the upper bound of the 95% CI is much longer than any of the tasks used for the measurement.
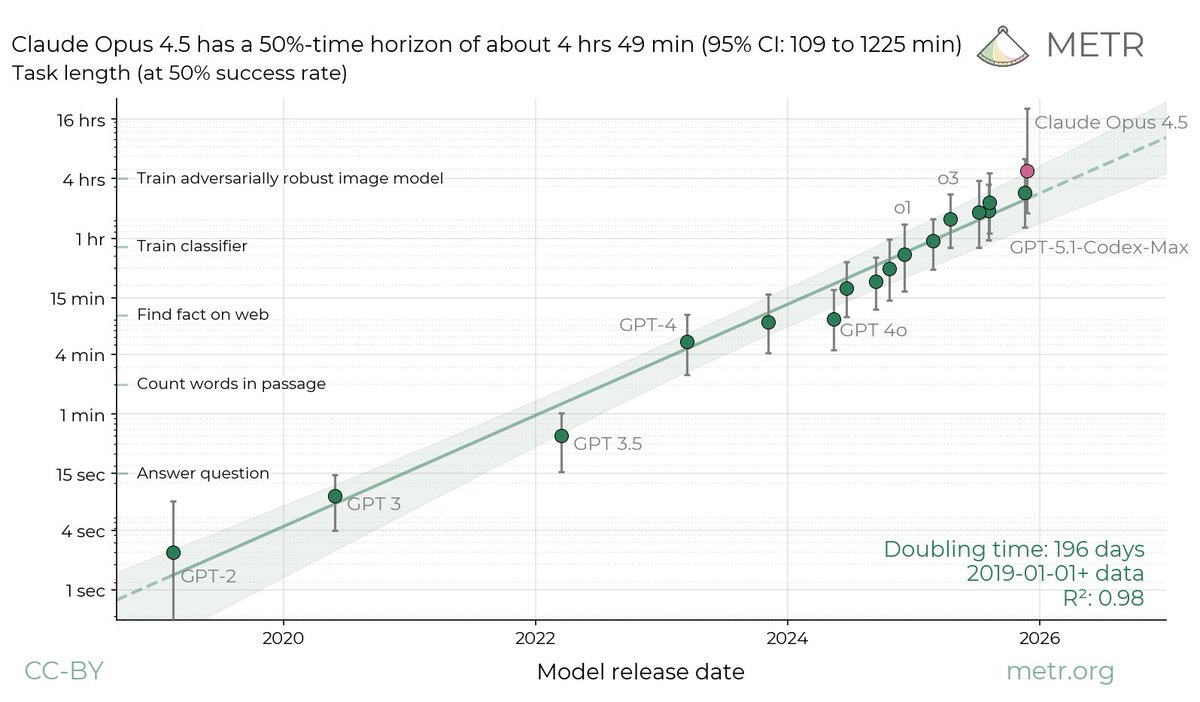 We don’t think the high upper CI bound reflects Opus’s actual capabilities: our current task suite doesn’t have enough long tasks to confidently upper bound Opus 4.5’s 50%-time horizon. We are working on updating our task suite, and hope to share more details soon.
We don’t think the high upper CI bound reflects Opus’s actual capabilities: our current task suite doesn’t have enough long tasks to confidently upper bound Opus 4.5’s 50%-time horizon. We are working on updating our task suite, and hope to share more details soon.
 Model performance can vary based on inference provider and time of evaluation. Our Kimi K2 Thinking runs for this evaluation come from Novita AI via OpenRouter, over November 13-17.
Model performance can vary based on inference provider and time of evaluation. Our Kimi K2 Thinking runs for this evaluation come from Novita AI via OpenRouter, over November 13-17.
 We argue: (1) these threat models require capabilities significantly beyond current systems, (2) our results indicate GPT-5 is an on-trend improvement that lacks these capabilities by a reasonable margin and (3) other evidence did not raise significant doubts about our results.
We argue: (1) these threat models require capabilities significantly beyond current systems, (2) our results indicate GPT-5 is an on-trend improvement that lacks these capabilities by a reasonable margin and (3) other evidence did not raise significant doubts about our results. 
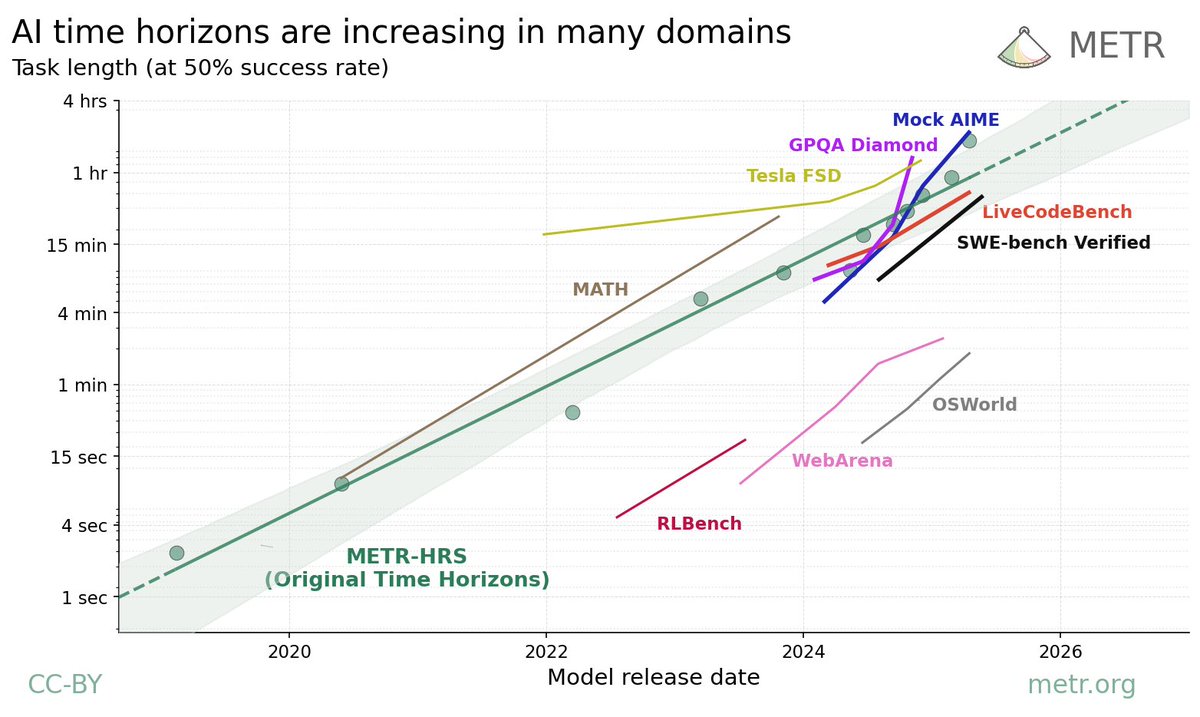 We analyze data from 9 existing benchmarks: MATH, OSWorld, LiveCodeBench, Mock AIME, GPQA Diamond, Tesla FSD, Video-MME, RLBench, and SWE-Bench Verified, which either include human time data or allow us to estimate it.
We analyze data from 9 existing benchmarks: MATH, OSWorld, LiveCodeBench, Mock AIME, GPQA Diamond, Tesla FSD, Video-MME, RLBench, and SWE-Bench Verified, which either include human time data or allow us to estimate it. 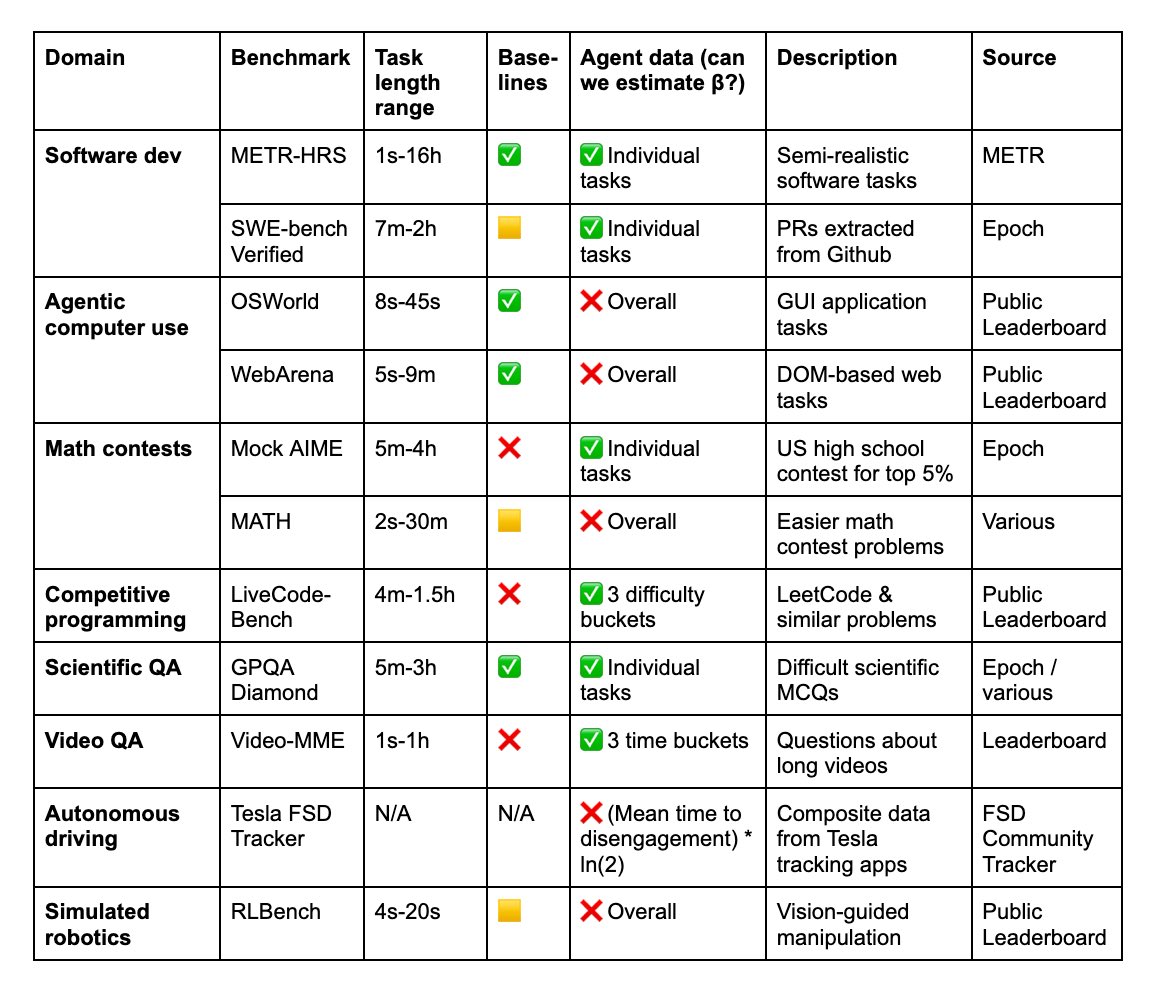
 We recruited 16 experienced open-source developers to work on 246 real tasks in their own repositories (avg 22k+ stars, 1M+ lines of code).
We recruited 16 experienced open-source developers to work on 246 real tasks in their own repositories (avg 22k+ stars, 1M+ lines of code).
 On an updated version of our task suite, we estimate that o3 and o4-mini reach 50% time horizons which are 1.8x and 1.5x that of Claude 3.7 Sonnet, respectively. This is longer than all other public models we’ve tested.
On an updated version of our task suite, we estimate that o3 and o4-mini reach 50% time horizons which are 1.8x and 1.5x that of Claude 3.7 Sonnet, respectively. This is longer than all other public models we’ve tested. 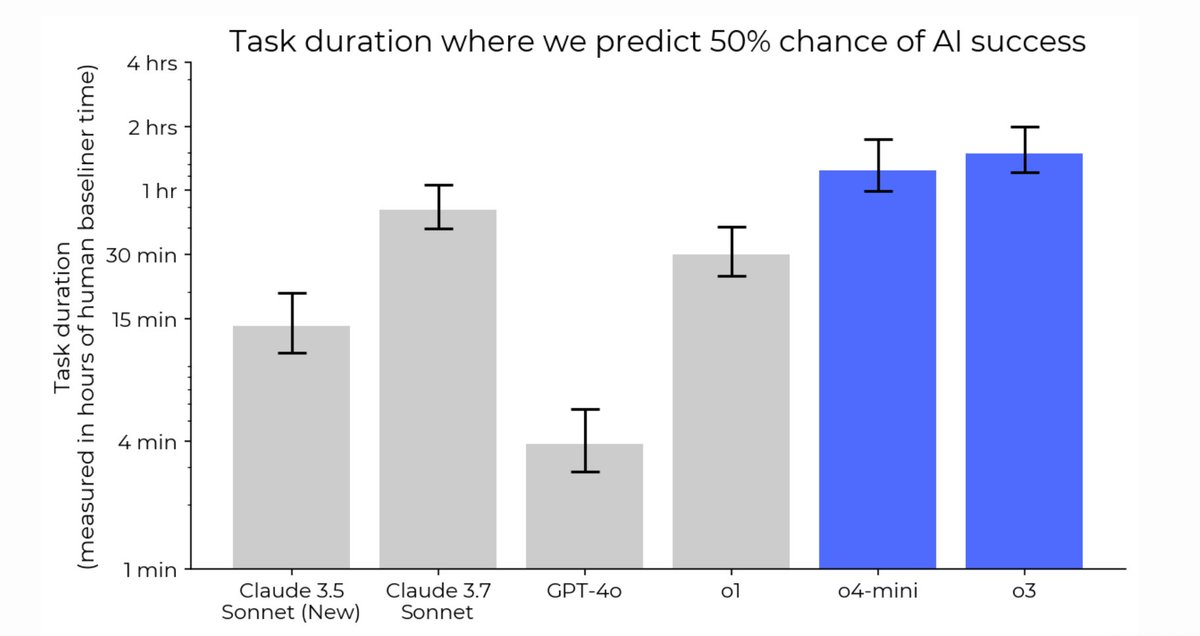
 At a high level, our method is simple:
At a high level, our method is simple:
 Many governments and companies have highlighted automation of AI R&D by AI agents as a key capability to monitor for when scaling/deploying frontier ML systems. However, existing evals tend to focus on short, narrow tasks and lack direct comparisons with human experts.
Many governments and companies have highlighted automation of AI R&D by AI agents as a key capability to monitor for when scaling/deploying frontier ML systems. However, existing evals tend to focus on short, narrow tasks and lack direct comparisons with human experts. 
 The o1-preview agent made nontrivial progress on 2 of 7 challenging AI R&D tasks (intended for skilled research engineers to take ~8h). It was able to create an agent scaffold that allowed GPT-3.5 to solve coding problems in rust, and fine-tune GPT-2 for question-answering.
The o1-preview agent made nontrivial progress on 2 of 7 challenging AI R&D tasks (intended for skilled research engineers to take ~8h). It was able to create an agent scaffold that allowed GPT-3.5 to solve coding problems in rust, and fine-tune GPT-2 for question-answering. 

 Supplementing our work on evaluating specific capabilities of concern, our task suite for autonomous capabilities measures skills including cybersecurity, software engineering, and ML. The tasks range in difficulty from taking skilled humans less than 15 minutes to many hours.
Supplementing our work on evaluating specific capabilities of concern, our task suite for autonomous capabilities measures skills including cybersecurity, software engineering, and ML. The tasks range in difficulty from taking skilled humans less than 15 minutes to many hours. 