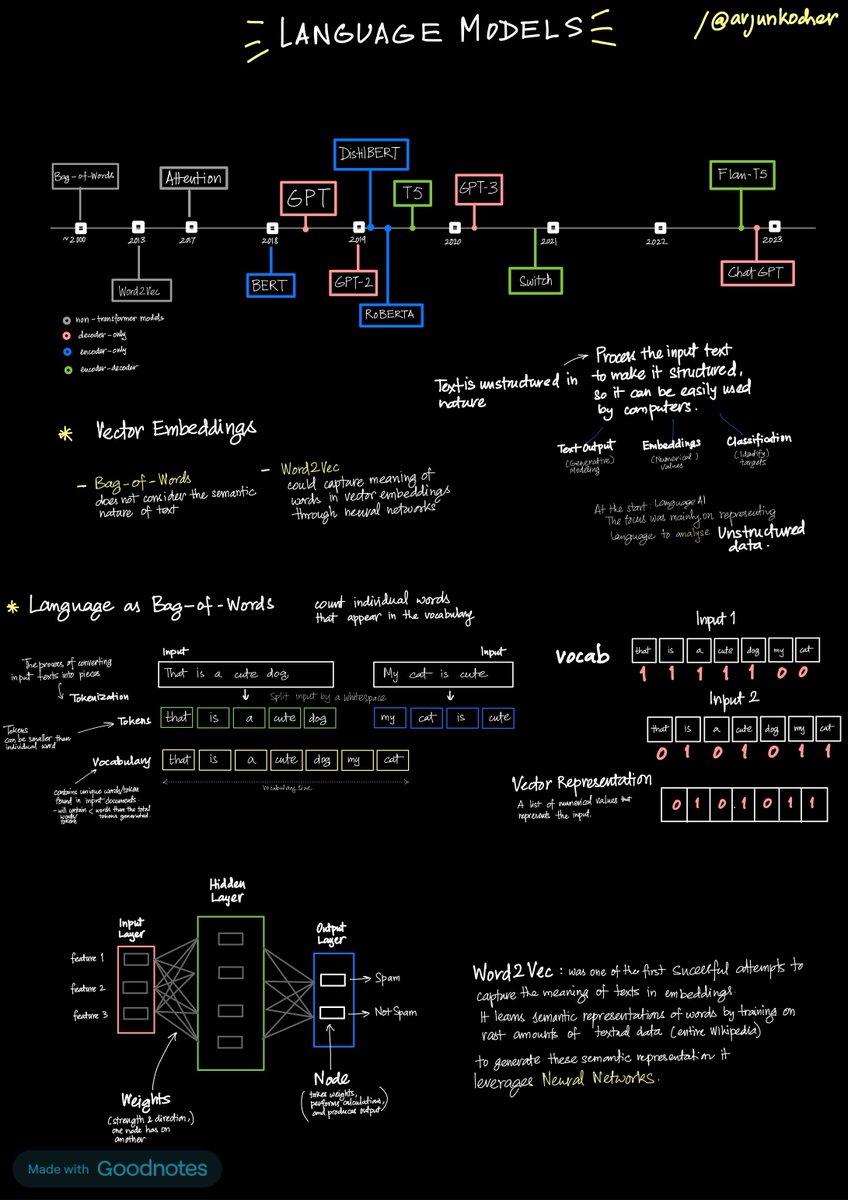
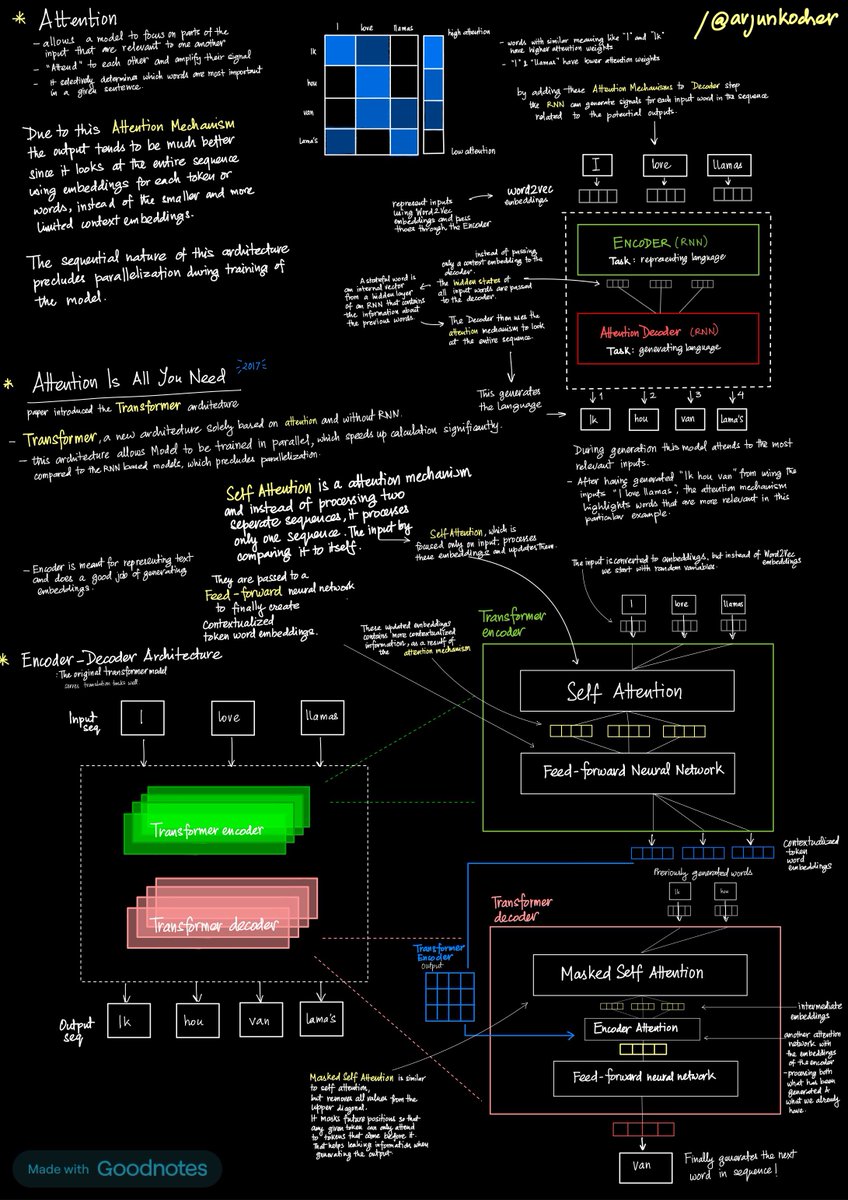
the best researchers from Meta, Yale, Stanford, Google DeepMind, and Microsoft laid out all we know about Agents in a 264-page paper [book],
here are some of their key findings:
here are some of their key findings:

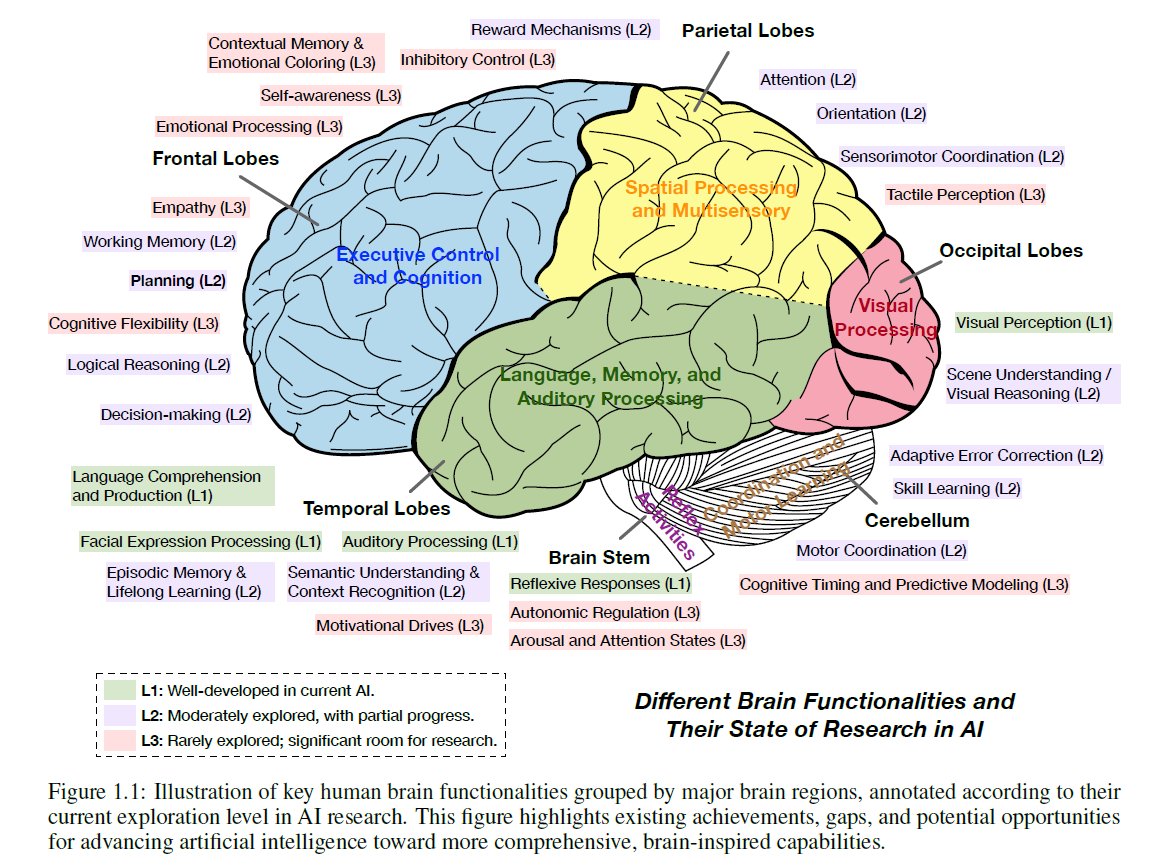
they build a mapping of different agent components, such as perception, memory, and world modelling, to different regions of the human brain and compare them:
- brain is much more energy-efficient
- no genuine experience in agents
- brain learns continuously, agent is static
- brain is much more energy-efficient
- no genuine experience in agents
- brain learns continuously, agent is static
an agent is broken down to:
- Perception: the agent's input mechanism. can be improved with multi-modality, feedback mechanisms (e.g., human corrections), etc.
- Cognition: learning, reasoning, planning, memory. LLMs are key in this part.
- Action: agent's output and tool use.
- Perception: the agent's input mechanism. can be improved with multi-modality, feedback mechanisms (e.g., human corrections), etc.
- Cognition: learning, reasoning, planning, memory. LLMs are key in this part.
- Action: agent's output and tool use.

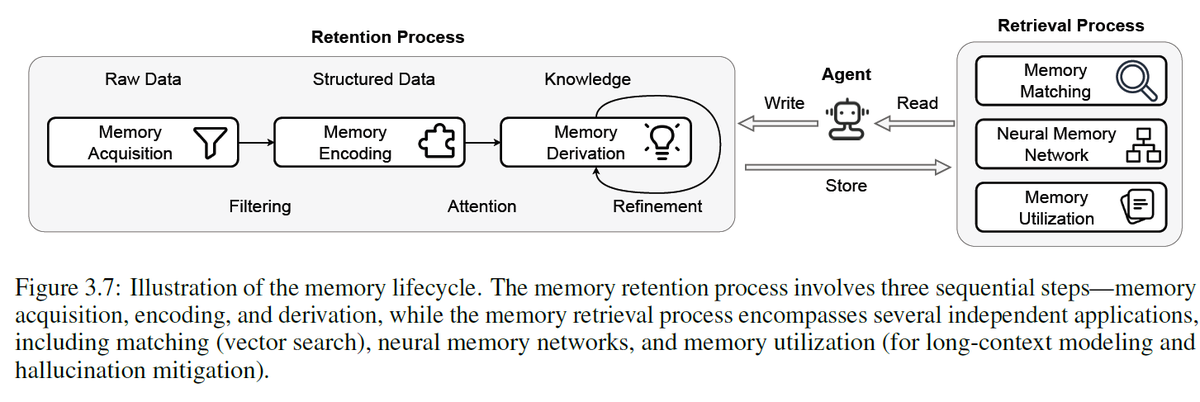
agentic memory is represented as:
- Sensory memory or short-term holding of inputs which is not emphasized much in agents.
- Short-term memory which is the LLM context window
- Long-term memory which is the external storage such as RAG or knowledge graphs.
- Sensory memory or short-term holding of inputs which is not emphasized much in agents.
- Short-term memory which is the LLM context window
- Long-term memory which is the external storage such as RAG or knowledge graphs.

the memory in agents can be improved and researched in terms of:
- increasing the amount of stored information
- how to retrieve the most relevant info
- combining context-window memory with external memory
- deciding what to forget or update in memory
- increasing the amount of stored information
- how to retrieve the most relevant info
- combining context-window memory with external memory
- deciding what to forget or update in memory
the agent must simulate or predict the future states of the environment for planning and decision-making.
ai world models are much simpler than the humans' with their causal reasoning (cause-and-effect) or physical intuition.
LLM world models are mostly implicit and embedded
ai world models are much simpler than the humans' with their causal reasoning (cause-and-effect) or physical intuition.
LLM world models are mostly implicit and embedded
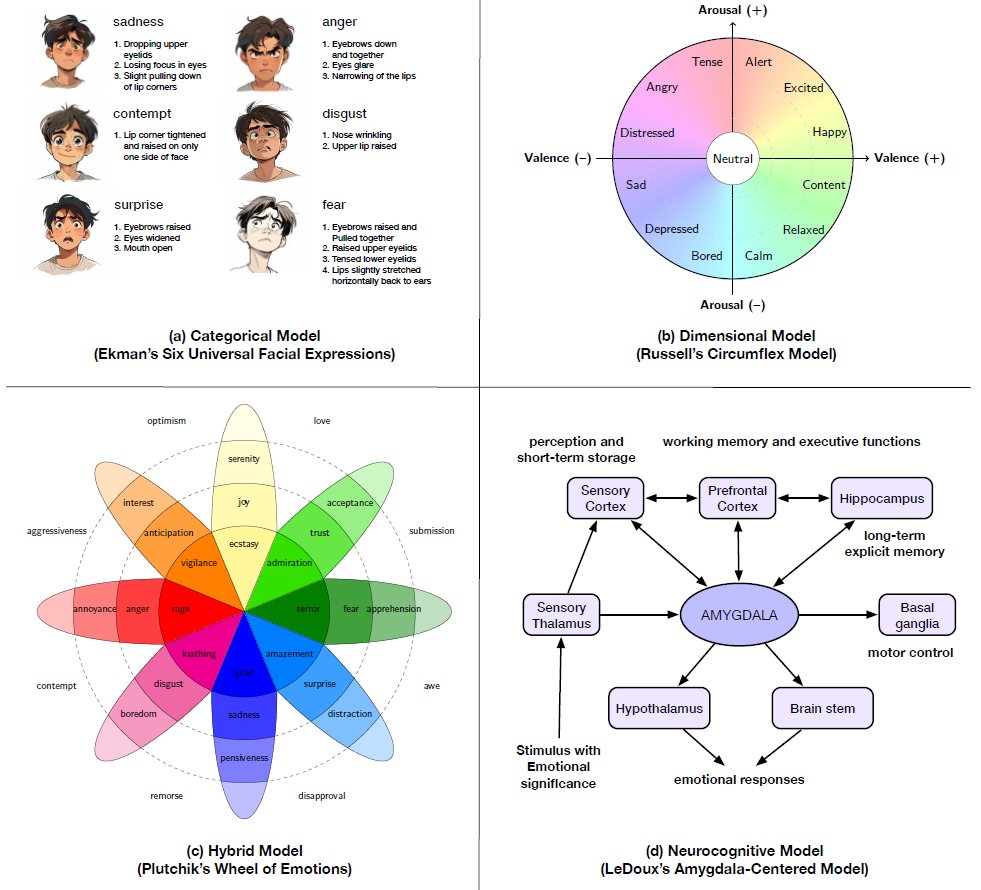
EMOTIONS are a deep aspect of humans, helping them with social interactions, decision-making, or learning.
agents must understand emotions to better interact with us.
but rather than encoding the feeling of emotions, they have a surface-level modelling of emotions.
agents must understand emotions to better interact with us.
but rather than encoding the feeling of emotions, they have a surface-level modelling of emotions.
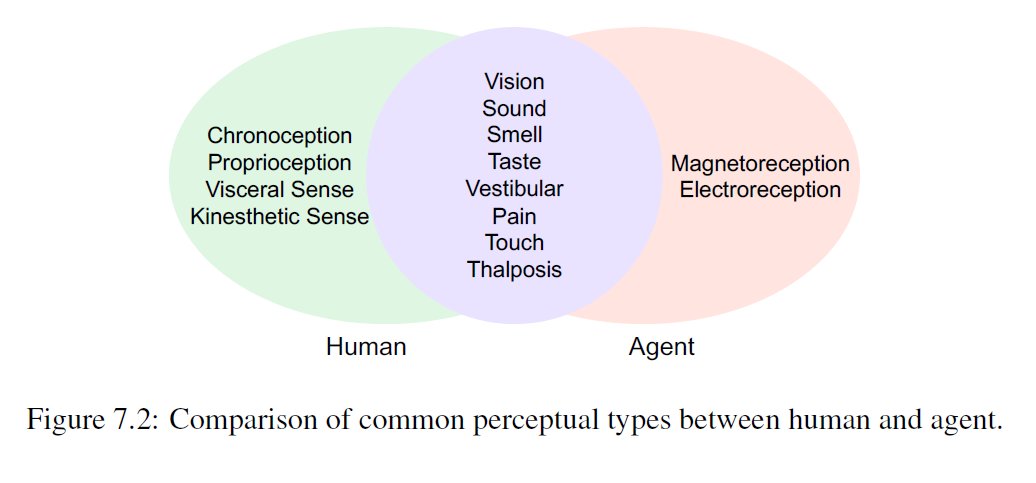
Perception is the process by which an agent receives and interprets raw data from its surroundings.
human perception is complex, while AI's perception is mostly limited to textual and vision data, though research is finding ways to incorporate more (e.g. audio)
human perception is complex, while AI's perception is mostly limited to textual and vision data, though research is finding ways to incorporate more (e.g. audio)
the paper goes on to explore multi-agent systems and the approach of key players such as MetaGPT, @CamelAIOrg , @huggingface, or ChatDEV.
It also touches on online active learning, design of multi-agent systems, and different agent collaboration paradigms.
It also touches on online active learning, design of multi-agent systems, and different agent collaboration paradigms.

I only covered the Part I of the paper. It has 4 comprehensive parts which cover almost all crucial things to know about agents.
Read Paper: huggingface.co/papers/2504.01…
Read Paper: huggingface.co/papers/2504.01…
CORRECTION: the paper is not affiliated with META but @MetaGPT_
• • •
Missing some Tweet in this thread? You can try to
force a refresh