1. evaluate your tools
1. evaluate your tools
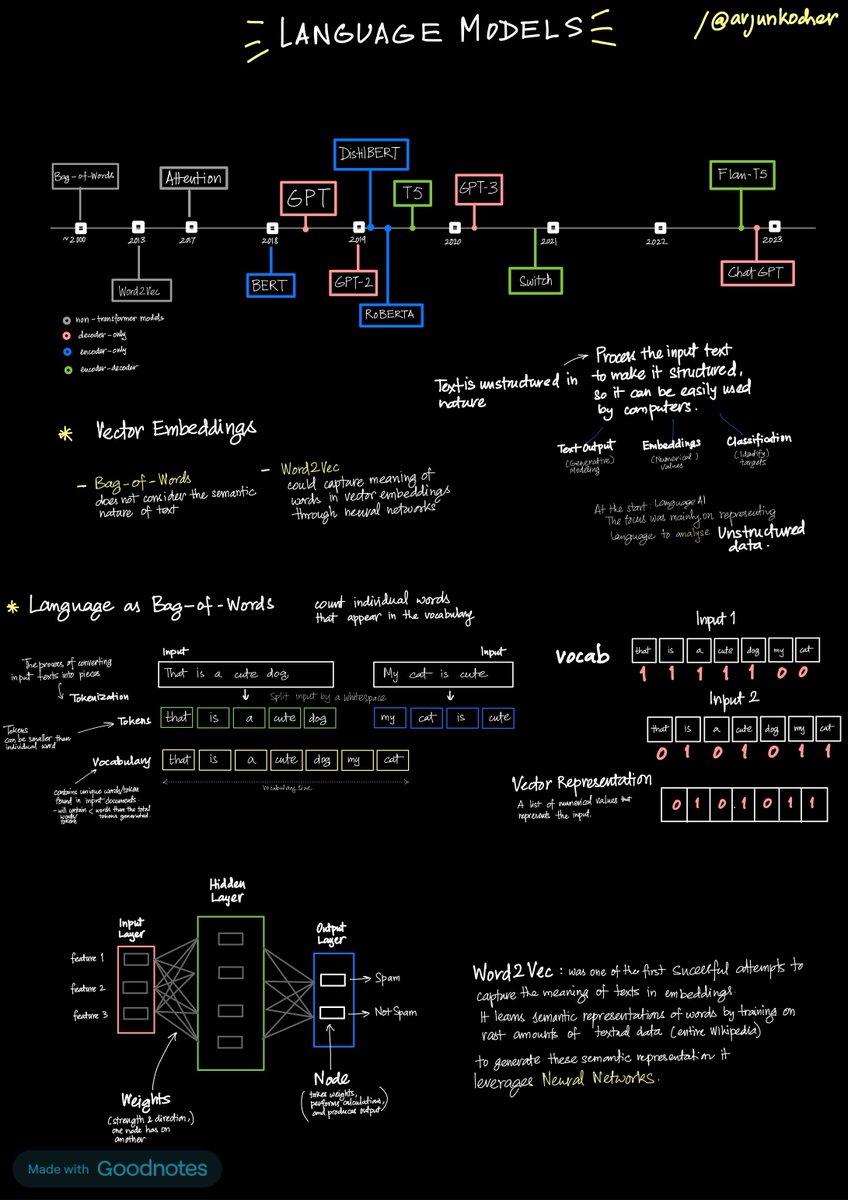 2. vector embeddings and RNNs.
2. vector embeddings and RNNs. 
 they build a mapping of different agent components, such as perception, memory, and world modelling, to different regions of the human brain and compare them:
they build a mapping of different agent components, such as perception, memory, and world modelling, to different regions of the human brain and compare them: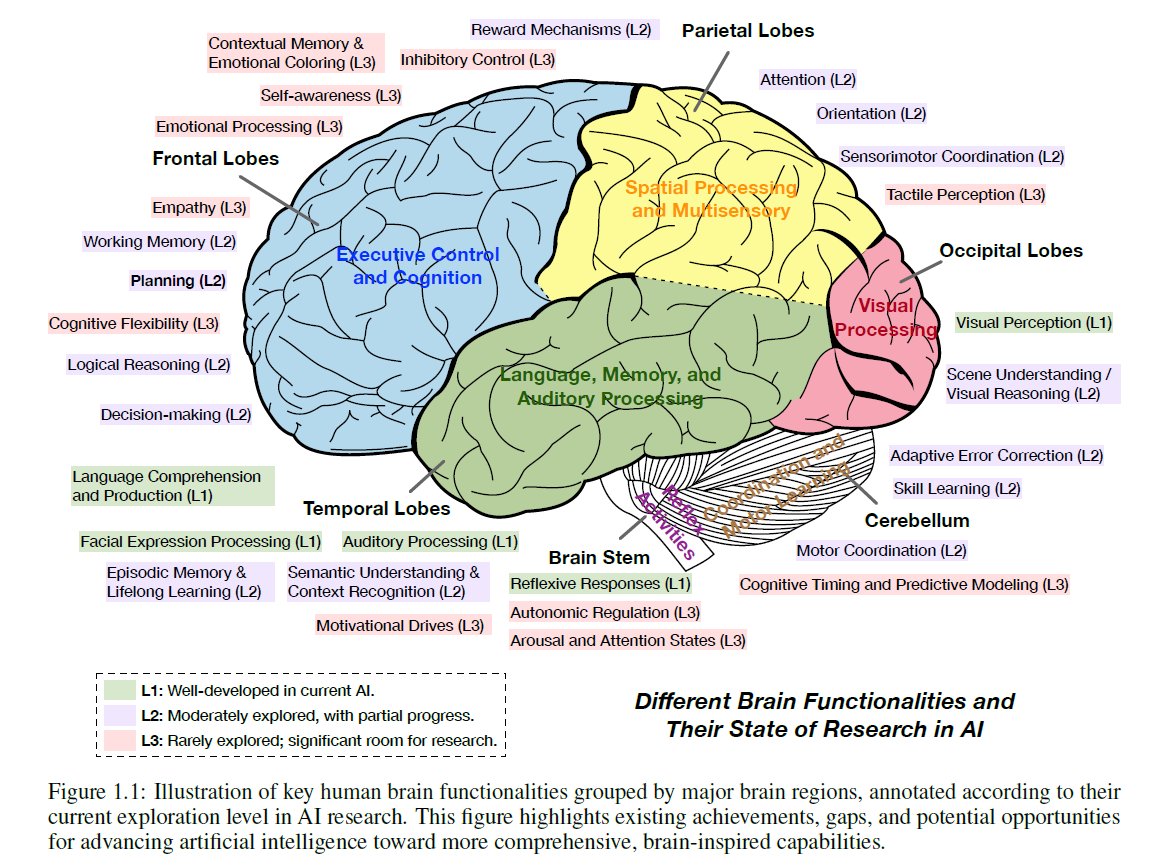
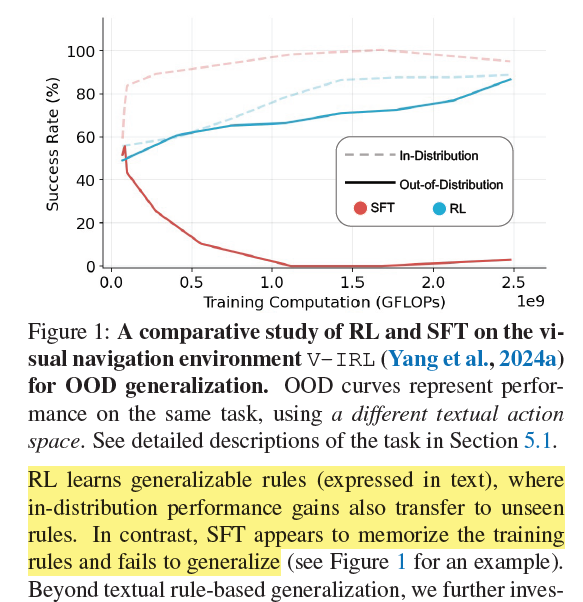
 In short, the paper argues that supervised fine-tuning (SFT) helps the model memorize and align with certain outputs, while reinforcement learning (RL) helps the model generalize and learn out-of-distribution (OOD) tasks.
In short, the paper argues that supervised fine-tuning (SFT) helps the model memorize and align with certain outputs, while reinforcement learning (RL) helps the model generalize and learn out-of-distribution (OOD) tasks.