Introducing jina-reranker-m0: our new multilingual multimodal reranker model for ranking visual documents across multiple languages: it accepts a query alongside a collection of visually rich document images, including pages with text, figures, tables, infographics, and various layouts across multiple domains and over 29 languages.
Unlike jina-reranker-v2-base-multilingual, jina-reranker-m0 moves from the classic cross-encoder architecture to a decoder-only vision language model. It leverages the pretrained Qwen2-VL's vision encoder and projector, finetuned its LLM part with LoRA, and post-trained a MLP to generate ranking logits that measure query-document relevance. This gives a discriminative model optimized for ranking tasks.
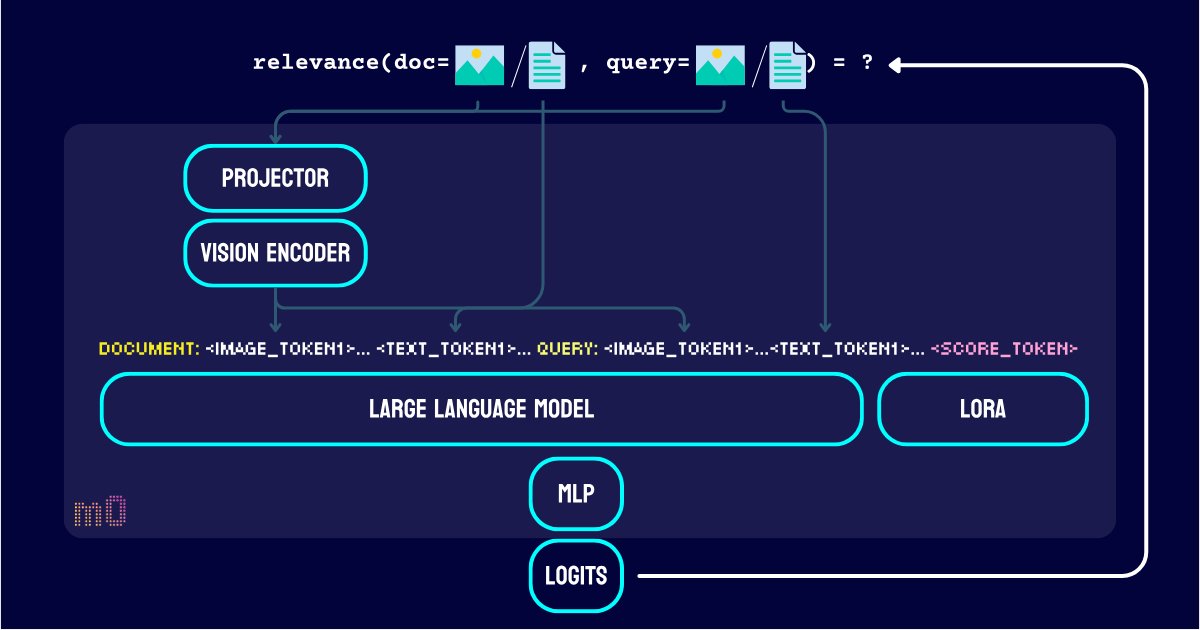
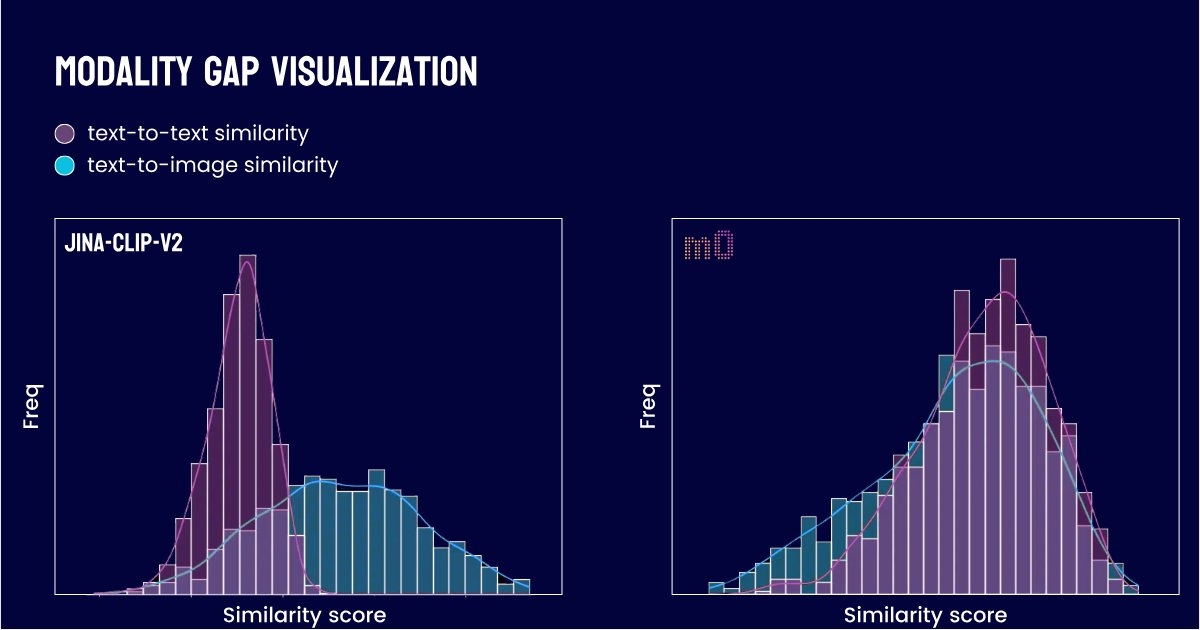
This architecture also effectively solves the modality gap problem that plagued earlier models like jina-clip-v1, jina-clip-v2. Previously, images would cluster near other images while text would cluster near other text in the representation space, creating a disconnect. This meant that when your candidate documents contained both images and text, retrieving images using text queries was problematic. With jina-reranker-m0, you can now rank images and documents together without worrying about this gap, creating a truly unified multimodal search experience.
jina-reranker-m0 is not only SOTA on ViDoRe, MBEIR, and Winoground visual retrieval benchmarks; but also on text-only benchmarks such as BEIR, MIRACL, MLDR, MKQA and CodeIR. Yes, jina-reranker-m0 is greatly optimized for code search.


Check out the post and learn more about the benchmarks, huggingface model page, API. jina-reranker-m0 is our first attempt to unify textual and visual modalities in a decoder-only model. It opens up many new possibilities that weren't achievable with encoder-only rerankers. Try m0 and let us know what you think.jina.ai/news/jina-rera…
• • •
Missing some Tweet in this thread? You can try to
force a refresh