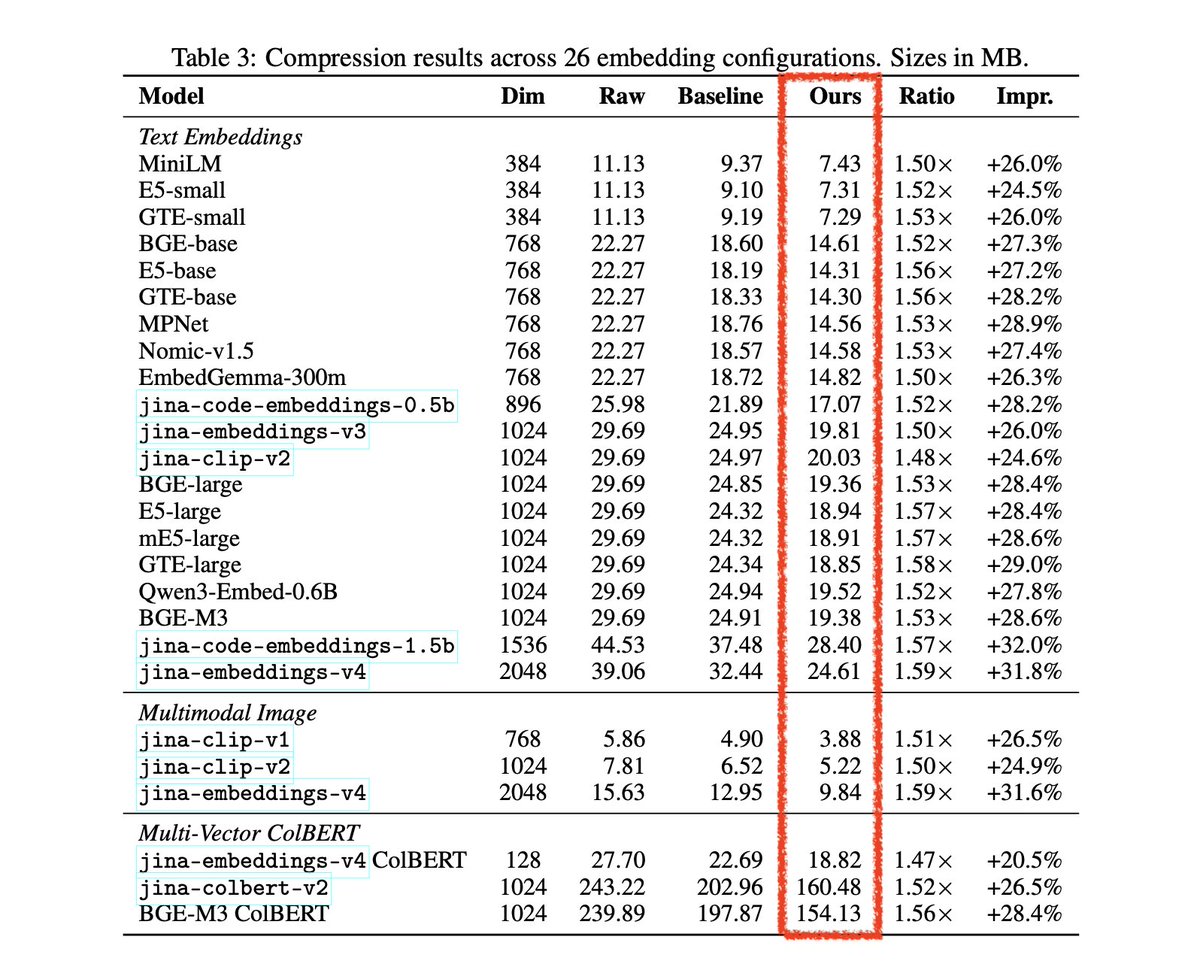
 Here's why it works: embeddings lie on a hypersphere, so d-1 angles can replace d Cartesian coordinates. In high dimensions, those angles concentrate around pi/2, causing IEEE 754 exponents to collapse to a single value. This makes the byte stream highly compressible.
Here's why it works: embeddings lie on a hypersphere, so d-1 angles can replace d Cartesian coordinates. In high dimensions, those angles concentrate around pi/2, causing IEEE 754 exponents to collapse to a single value. This makes the byte stream highly compressible. 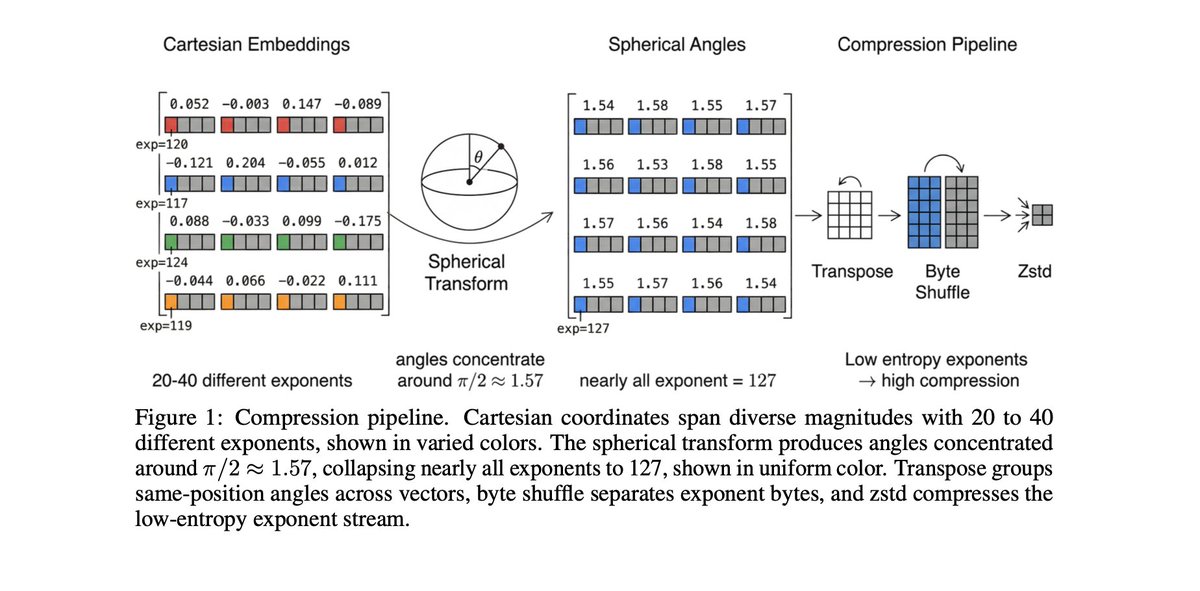
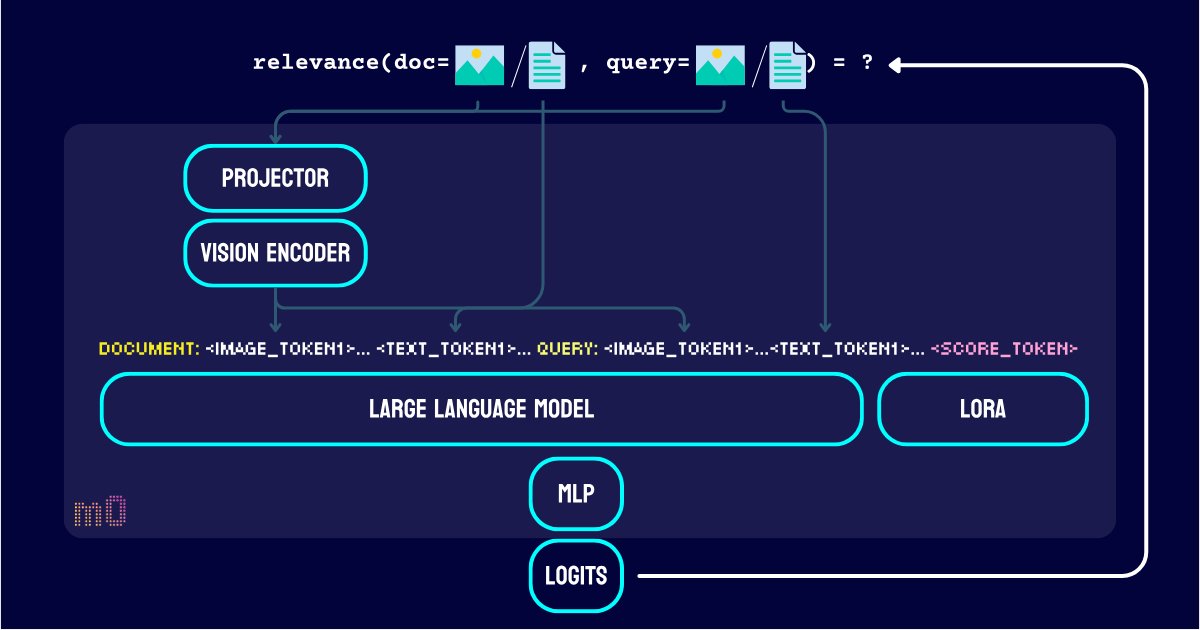
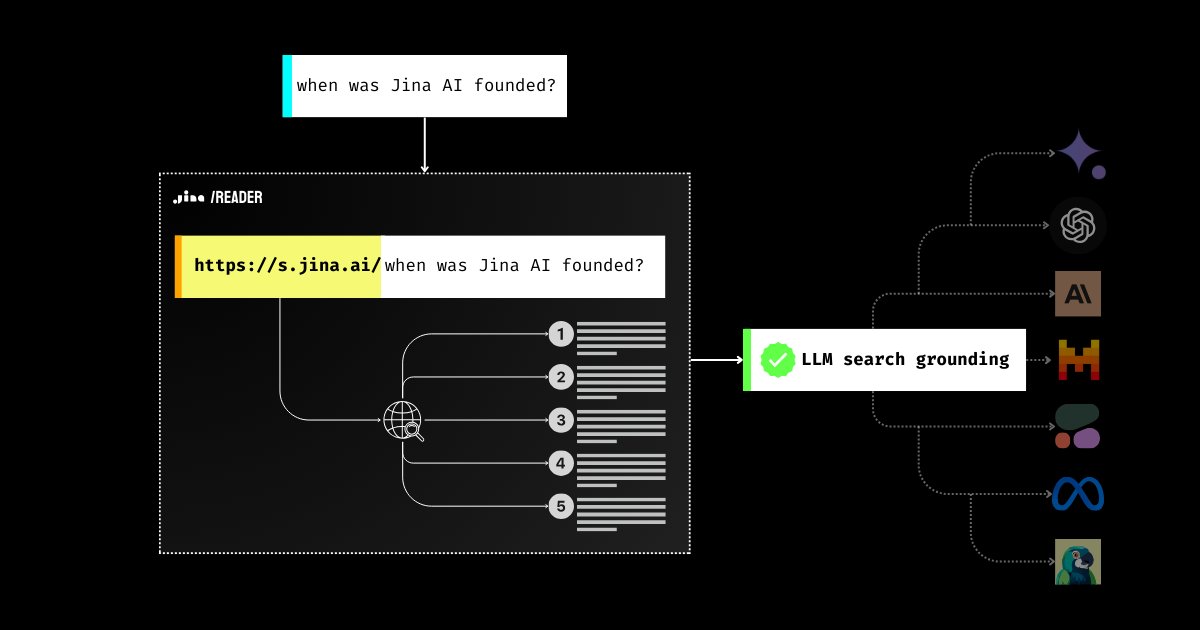 Not familiar with search grounding? Allow me to explain a bit. We all know LLMs can make things up and harm user trust. LLMs may say things that are not factual (aka hallucinate), especially regarding topics they didn't learn about during training. This could be either new information created since training or niche knowledge that has been "marginalized" during training.
Not familiar with search grounding? Allow me to explain a bit. We all know LLMs can make things up and harm user trust. LLMs may say things that are not factual (aka hallucinate), especially regarding topics they didn't learn about during training. This could be either new information created since training or niche knowledge that has been "marginalized" during training.