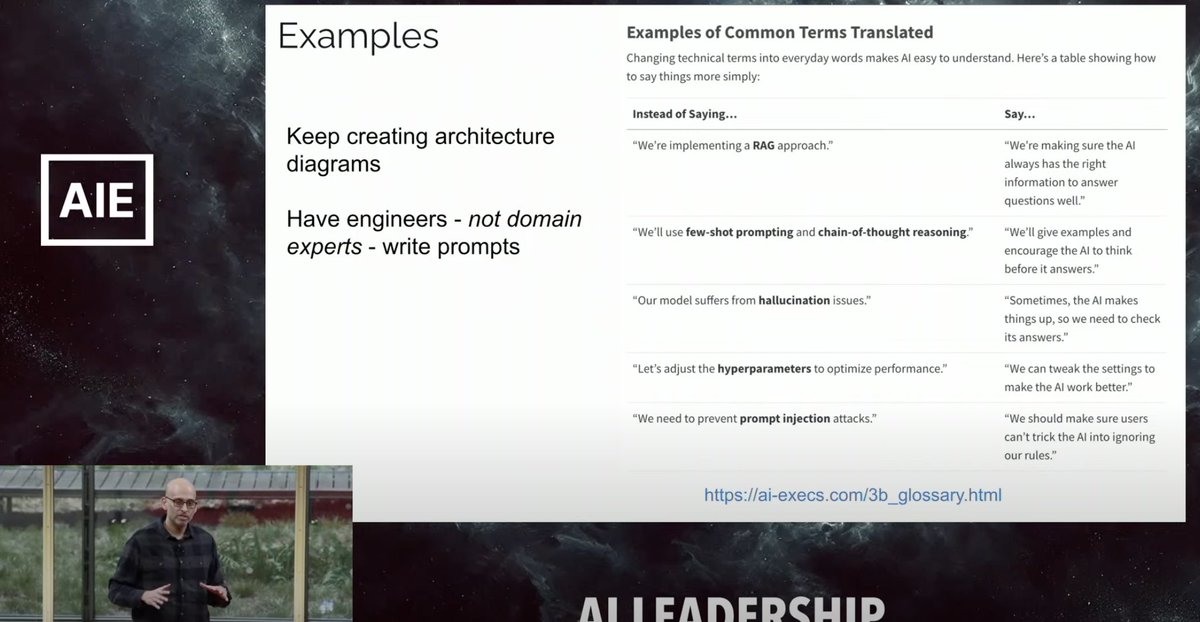
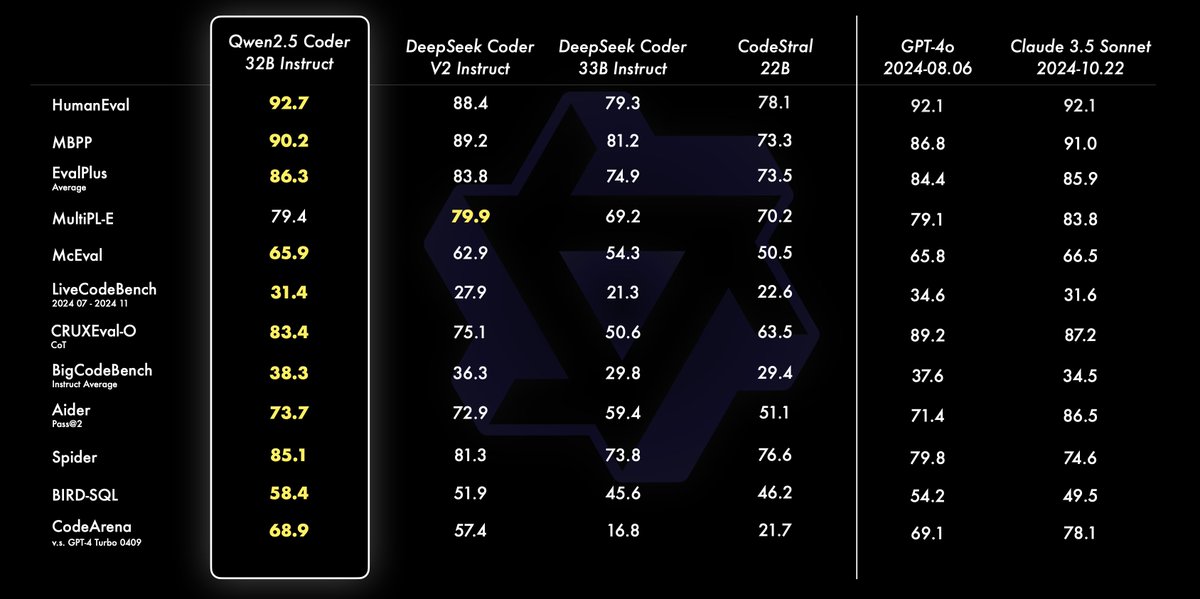
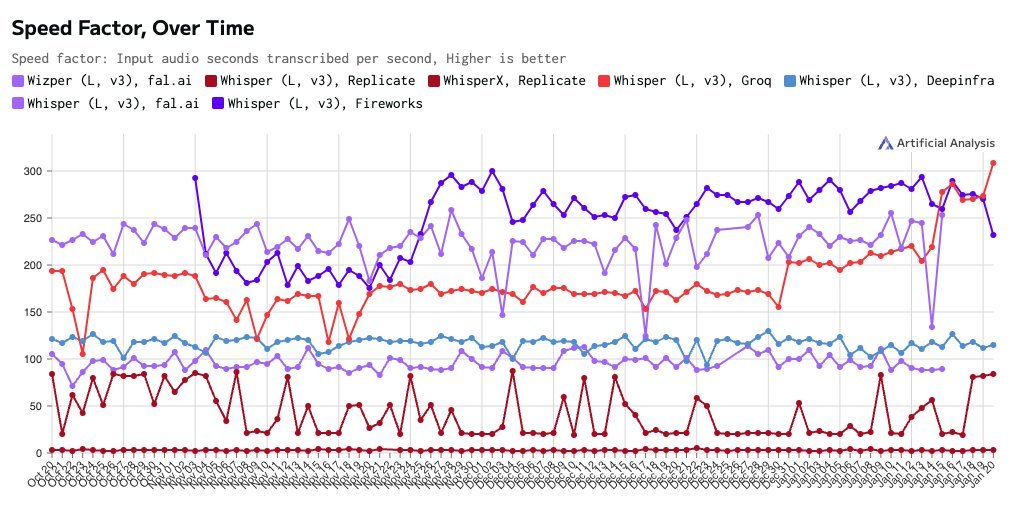
read through @vercel's state of ai survey to see that 22% of builders are now using @groqinc and we're one of the top providers developers switched to in the last 6 months.
we do it all for you. 🫡
we do it all for you. 🫡
https://twitter.com/vercel/status/1912588341973065972
1/4 and just why are developers switching? the survey shows that 23% of you cite latency/performance as a top technical challenge, which is exactly what we're solving with our lpu inference engine and offering you access to that powerful hardware via groq api.
2/4 another interesting, but not surprising data point: 86% of teams don't train their models, preferring to focus on implementation and optimization.
smart strategy - tell us the models you'd like to see and let us handle the inference speed while you spend your time building.
smart strategy - tell us the models you'd like to see and let us handle the inference speed while you spend your time building.
3/4 cost management remains a top challenge for 23% of developers. i hear you. (side eyeing openai/anthropic rn... with love). 🤨
if this is also a challenge for you, check out our pricing page to see how you can scale with us without breaking your bank:
groq.com/pricing
if this is also a challenge for you, check out our pricing page to see how you can scale with us without breaking your bank:
groq.com/pricing
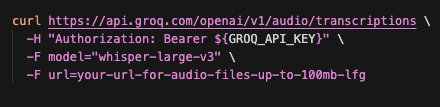
5/5 if you want to be part of the teams that switched ( you should, although i may be biased), check out our docs - built by devs for devs.
our api is openai-compatible & we have features ranging from crazy fast reasoning to TTS.
what should we add next?
console.groq.com/docs/overview
our api is openai-compatible & we have features ranging from crazy fast reasoning to TTS.
what should we add next?
console.groq.com/docs/overview
• • •
Missing some Tweet in this thread? You can try to
force a refresh