We've been limited to Claude Desktop and IDEs like Cursor for MCP... until now. ⚡️
We shipped Groq Desktop, a new MCP host that's insanely fast. You can now give models like Llama 4 Scout and Qwen QwQ 32B the ability to instantly read PDFs, connect to Slack, and so much more.
2/5 If you're still asking "WTH is MCP", think of it as Bluetooth - the same way Bluetooth allows you to easily connect your keyboard and mouse to your laptop, MCP is a standard protocol that lets models connect to tools like APIs or databases without having to write custom code.
Apr 17, 2025 • 5 tweets • 2 min read
read through @vercel's state of ai survey to see that 22% of builders are now using @groqinc and we're one of the top providers developers switched to in the last 6 months.
1/4 and just why are developers switching? the survey shows that 23% of you cite latency/performance as a top technical challenge, which is exactly what we're solving with our lpu inference engine and offering you access to that powerful hardware via groq api.
Apr 5, 2025 • 8 tweets • 2 min read
HUGE PSA: @Meta's Llama 4 Scout (17Bx16E MoE) is now live on @GroqInc for all users via console playground and Groq API.
This conversational beast with native multimodality just dropped today and we're excited to offer Day 0 support so you can build fast.
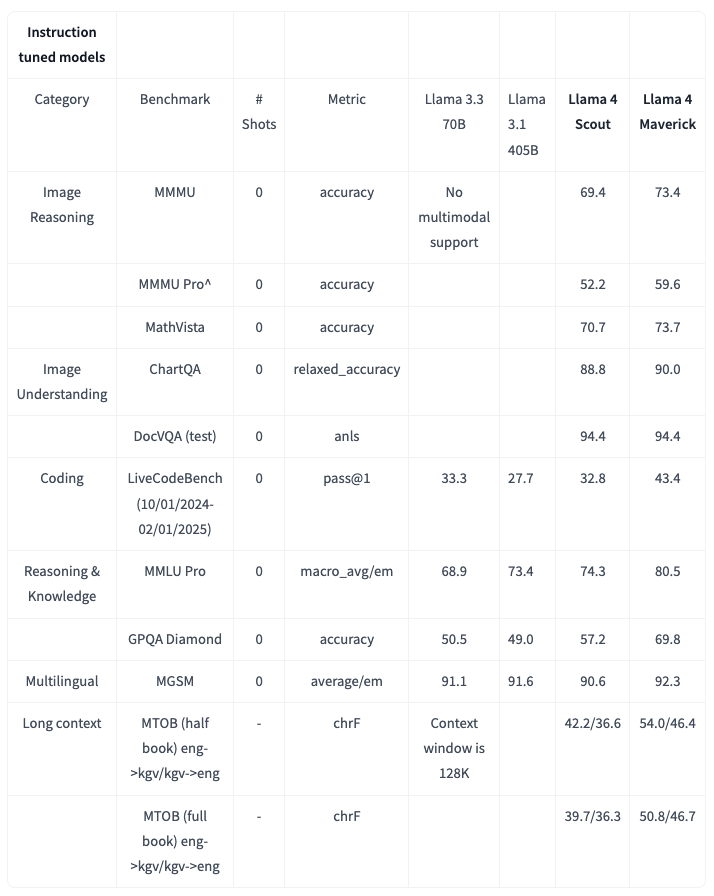
1/7 What makes Llama 4 Scout special? It's a chonky multimodal model with a 10M context window (yes, TEN MILLION tokens).
Built on an expert mixture architecture (17B activated params, 109B total), it brings incredible image understanding and conversational abilities.
Feb 21, 2025 • 10 tweets • 4 min read
Just wrapped up Day 1 of @aiDotEngineer and the talks went from "agents don't work (yet)" to enterprise deployment success stories.
2024 was for experimenting with AI, but 2025 is clearly the year of putting AI agents into production.
🧵 Here are some of my key takeaways:
1/9 @graceisford shared how agents = complex systems with compounding errors, but there's hope if we focus on:
- Data being our best asset/differentiator
- Personal LLM evals
- Tools to mitigate errors
- Intuitive AI UX (the moat that matters)
- Reimagining DevEx (go multimodal)
Feb 14, 2025 • 5 tweets • 2 min read
PSA: @Alibaba_Qwen's Qwen-2.5-Coder-32B-Instruct is now live on @GroqInc for insanely fast (and smart) code generation.
See below for instructions to add to @cursor_ai.
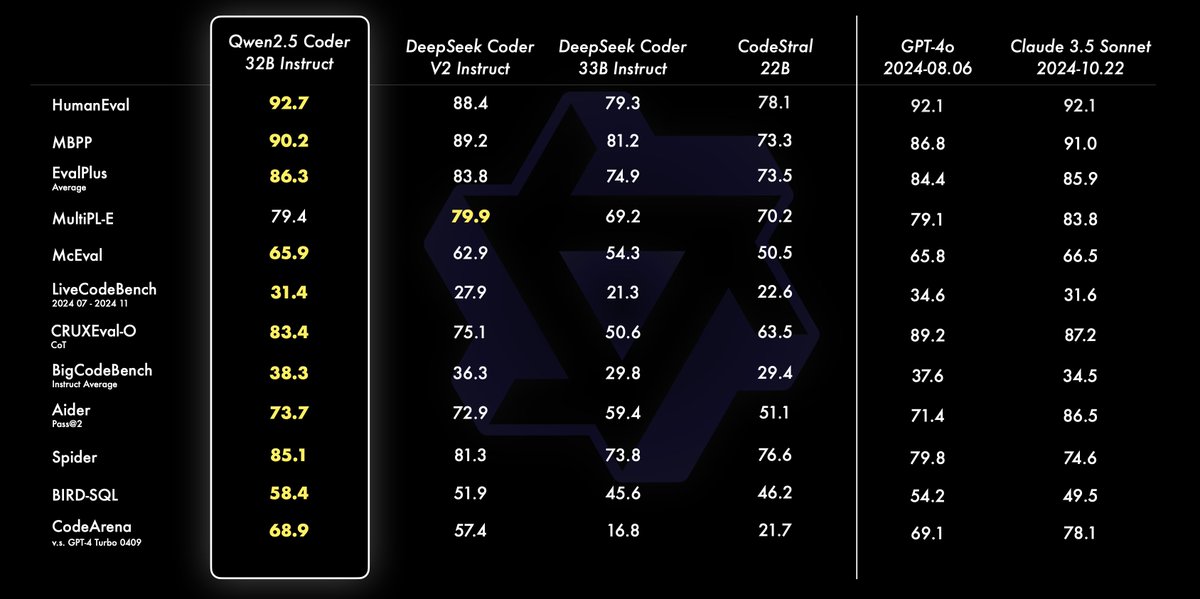
1/4 Qwen2.5 Coder is state-of-the-art when it comes to coding capabilities for open-source models with impressive performance across several popular code generation benchmarks - even beating GPT-4o and Claude 3.5 Sonnet.
Feb 6, 2025 • 6 tweets • 2 min read
PSA: DeepSeek R1 Distill Llama 70B speculative decoding version is now live on @GroqInc for Dev Tier.
We just made fast even faster for instant reasoning. 🏁
1/5 What is speculative decoding? It's a technique that uses a smaller, faster model to predict a sequence of tokens, which are then verified by the main, more powerful model in parallel. The main model evaluates these predictions and determines which tokens to keep or reject.
Feb 6, 2025 • 7 tweets • 3 min read
Let's couple our vibe coding with vibe learning with this incredible dive into LLMs that @karpathy just dropped. 🧠
This is what democratizing AI education looks like with knowledge for both beginners and builders. And if you're new to AI development, this thread is for you.
2/7 Karpathy explains how parallelization is possible during LLM training, but output token generation is sequential during LLM inference. Specialized HW (like Groq's LPU) is designed to optimize such computational reqs, particularly sequential token gen, for fast LLM outputs.
Jan 21, 2025 • 4 tweets • 2 min read
Huge ship recap from @GroqInc this past week:
- Flex Tier Beta is live for Llama 3.3 70b/8b with 10x higher rate limits
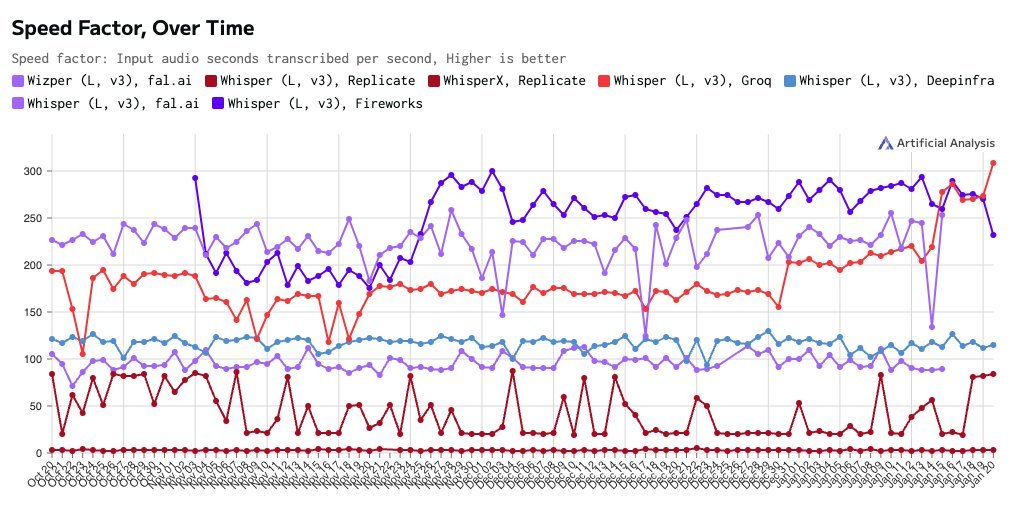
- Whisper Large v3 is now 67% faster (tokens go BRRR)
- Whisper Large v3 audio file limit is now 100MB (up from 40MB)
- The DevRel team is growing 📈📈📈 2/4 Flex Tier gives on-demand processing with rapid timeout when resources are constrained - perfect for workloads that need fast inference and can handle occasional request failures.
Available with Llama 3.3 70b/8b for paid tier at the same price.
@Meta's Llama 3.3 70B is now available on @GroqInc for all users! 🦙 We're launching:
- llama-3.3-70b-versatile
- llama-3.3-70b-specdec (for insanely fast speed)
Why is this exciting? We're getting 405B performance in a 70B model (yup). 1/6
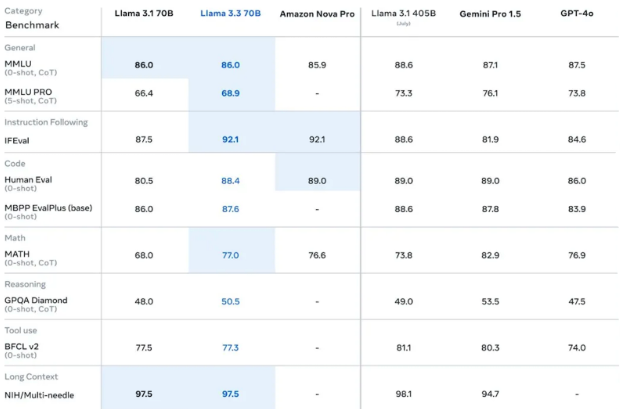
2/6 Technical improvements in model architecture and post-training techniques have yielded significant gains across key benchmarks:
- IFEval: 92.1 (↑ from 87.5 and beats 405B’s 88.6)
- HumanEval: 88.4 (↑ from 80.5)
- MATH: 77.0 (↑ from 68.0 and beats GPT-4o)
Nov 22, 2024 • 7 tweets • 2 min read
Friday Feature Drop:
We added a metrics dashboard to your console at for monitoring LLM requests powered by @GroqInc.
You can't improve what you don't measure - metrics will help you better understand your workflows so you can optimize them at scale. 💪 console.groq.com/metrics
@GroqInc V1 of your metrics dashboard includes HTTP status code tracking, API request tracking, and token usage. Let’s explore why tracking HTTP status codes and token usage is your first step toward production-grade AI infrastructure. 2/7
Oct 22, 2024 • 5 tweets • 1 min read
Do you know about our Groq API Cookbook? 🧑🍳
It's our carefully curated collection of code tutorials and real-world implementations that leverage @GroqInc's fast inference and integrations with other powerful tools to use in your apps.
Here's the repo: github.com/groq/groq-api-…
@GroqInc Our cookbook focuses on production-ready patterns to teach you the latest and greatest. From benchmarking RAG implementations with @LangChainAI to creating agentic workflows with @crewAIInc, each tutorial provides concrete examples of building robust AI apps for you to learn. 2/5