Temperature in LLMs, clearly explained (with code):
Let's prompt OpenAI GPT-3.5 with a low temperature value twice.
It produces identical responses from the LLM.
Check the response below👇
It produces identical responses from the LLM.
Check the response below👇

Now, let's prompt it with a high temperature value.
This time, it produces a gibberish output. Check the output below👇
What is going on here? Let's dive in!
This time, it produces a gibberish output. Check the output below👇
What is going on here? Let's dive in!

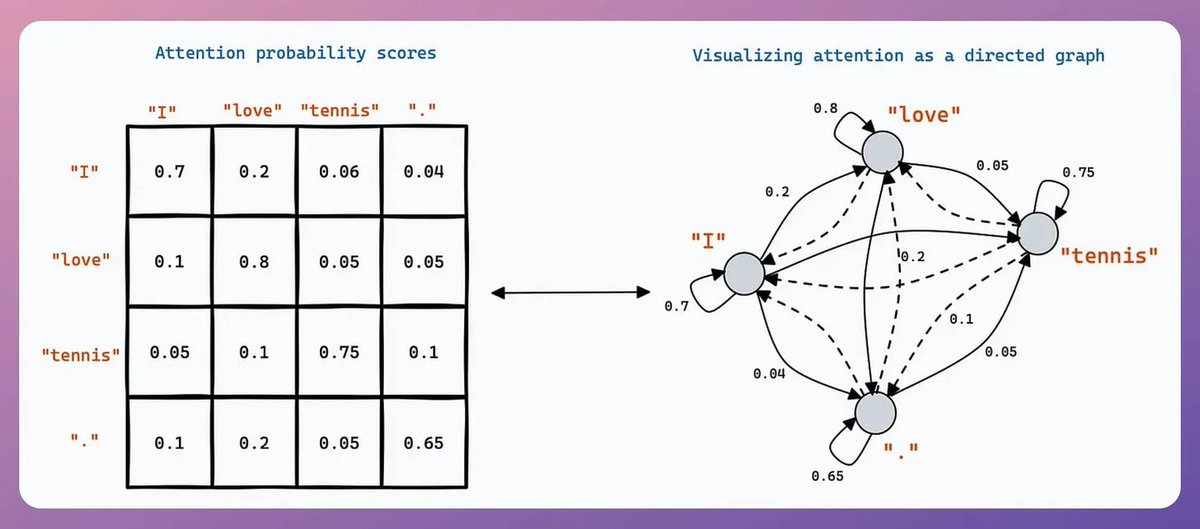
Text-generating LLMs are like classification models whose output layer spans the entire vocabulary.
However, instead of selecting the best token, they "sample" the prediction.
So even if “Token 1” has the highest softmax score, it may not be chosen due to sampling👇
However, instead of selecting the best token, they "sample" the prediction.
So even if “Token 1” has the highest softmax score, it may not be chosen due to sampling👇

The impact of sampling is controlled using the Temperature parameter.
Temperature introduces the following tweak in the softmax function 👇
Temperature introduces the following tweak in the softmax function 👇

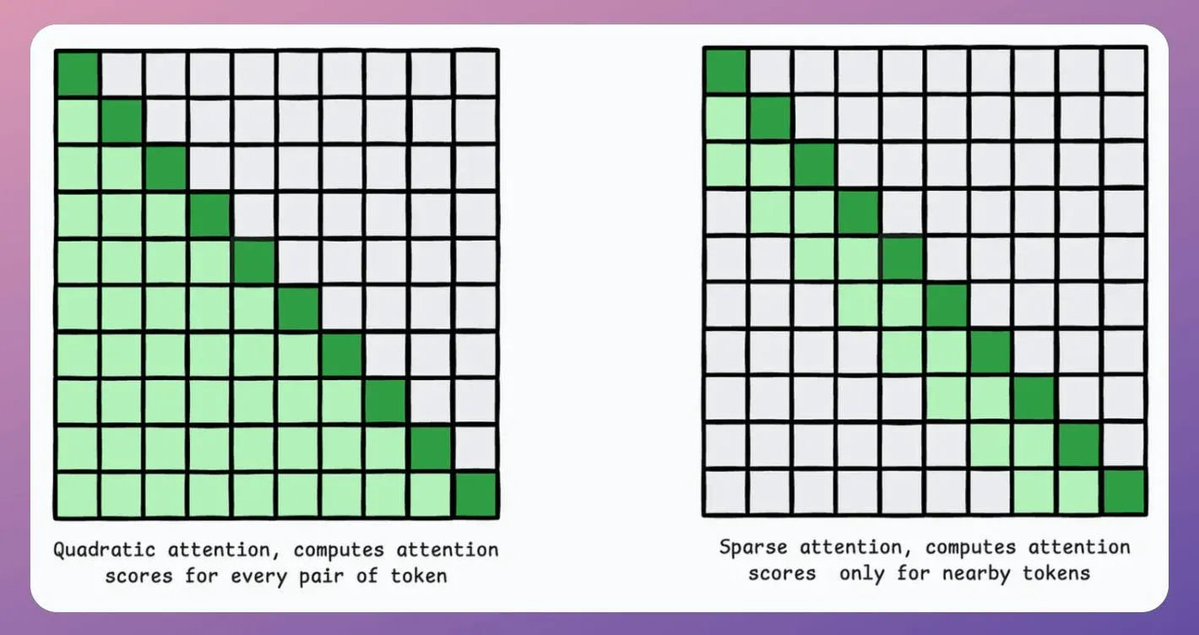
If the temperature is low, the probabilities look like a max value instead of a “soft-max” value.
This means the sampling process will almost certainly choose the token with the highest probability. This makes the generation process (nearly) greedy.
Check this👇
This means the sampling process will almost certainly choose the token with the highest probability. This makes the generation process (nearly) greedy.
Check this👇

If the temperature is high, the probabilities start to look like a uniform distribution:
This means the sampling process may select any token. This makes the generation process random and heavily stochastic, like we saw earlier.
Check this👇
This means the sampling process may select any token. This makes the generation process random and heavily stochastic, like we saw earlier.
Check this👇

Some best practices for using temperature (T):
- Set a low T value to generate predictable responses.
- Set a high T value to generate more random and creative responses.
- An extremely high T value rarely has any real utility, as shown below👇
- Set a low T value to generate predictable responses.
- Set a high T value to generate more random and creative responses.
- An extremely high T value rarely has any real utility, as shown below👇

That's a wrap!
If you enjoyed this tutorial:
Find me → @_avichawla
Every day, I share tutorials and insights on DS, ML, LLMs, and RAGs.
If you enjoyed this tutorial:
Find me → @_avichawla
Every day, I share tutorials and insights on DS, ML, LLMs, and RAGs.
• • •
Missing some Tweet in this thread? You can try to
force a refresh