Nice! Here we have an interesting paper using genetic ancestry to classify race/ethnicity in modern data and algorithms. Let's take a look at what this paper found: 🧵
https://twitter.com/timothycbates/status/1916500806196404395
First, I don't want to get too hung up on language, but TCB's tweet starts talking about "ethnicity", then shifts to "continental ancestries", and then entirely omits the largest ethnic group in the US: Hispanics. These terms have distinct definitions (). nap.nationalacademies.org/catalog/26902/…


Anyway, how well can this paper actually impute ethnicity from genetic ancestry in a large cancer population ()? ~17% of the time it gets Hispanic classification completely wrong or a no-call! worldscientific.com/doi/10.1142/97…

But even this is an overstatement, because the majority of participants either didn't list race/ethnicity or provided one that didn't fall into an established category. And the ML algorithm is *terrible* at classifying these unlabeled/partially labeled people as no calls.

This creates an interesting paradox where the algorithm can be made to look like it is more accurate over time, but in reality participants are simply drifting to a new unlabeled space in the social construct.
I was also intrigued by the claim that ethnicity is perhaps the least socially constructed variable in social science because an algorithm can classify some of the labels with some accuracy. Is this really true?

Language is a social construct, but AI is able to do a pretty good job at classifying languages.


Religion is a social construct, but AI can do a pretty good job classifying those too, even from a cartoony illustration.


Race is a social construct, but I bet you could easily classify thes-- wait, where was I going with this?

Even more interesting, you can explain a social construct like "money" to an AI and it will figure out the natural divisions within the construct based on visual details.
Can we do the same for race/ethnicity and ancestry? Let's play a game ...
Can we do the same for race/ethnicity and ancestry? Let's play a game ...


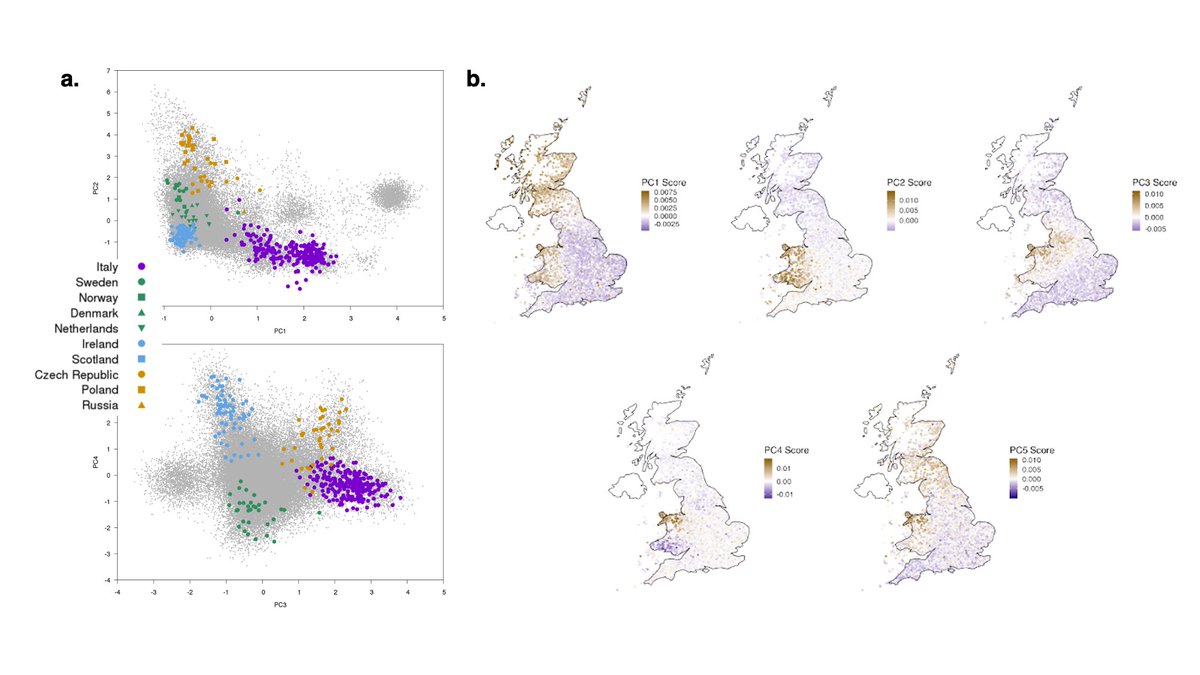
Here's a basic ancestry plot, where each point is a person. Do the green and purple dots reveal two racial groups?
Nope. The green and purple points are sampled from the same population but the purple dots just came from one family in that population.
Nope. The green and purple points are sampled from the same population but the purple dots just came from one family in that population.

Okay but that was simulated data. Here's another one, using real data from a large-scale biobank this time. Are these ten different racial groups? Surely the pink-ish groups are a different race from the greens at least?

Nope! These are all Chinese participants of the Kadoorie biobank, color-coded by the cities they were recruited from. Ancestry inference can be extremely sensitive with enough data.
() pubmed.ncbi.nlm.nih.gov/37601966/
() pubmed.ncbi.nlm.nih.gov/37601966/

Ok, maybe it's unfair to use such closely related populations. Let's look at data from continental groups and use a model-based clustering approach. Surely the two orange/tan clusters here are different races or continents:

Nope! The two groups being distinguished here are Melanesians and ... the rest of the world. Asian, Middle Eastern, European, and African participants all get clustered together because of the sampling of the data. () pmc.ncbi.nlm.nih.gov/articles/PMC60…

I'm making it too hard. Maybe we need more drifted populations and tree-based clustering instead? Look at the deep divergences across these populations, surely *these* must be different races?

Nope. These are all participants from Native American tribes within a single linguistic group. Some of the most diverged populations in the world get lumped together into one socially constructed box.
() nature.com/articles/natur…
() nature.com/articles/natur…

You get the idea.
TLDR: When people say a construct is "the least constructed / best / most replicable in social science", maybe they are telling you more about the quality of the social sciences than the validity of the construct. /x
TLDR: When people say a construct is "the least constructed / best / most replicable in social science", maybe they are telling you more about the quality of the social sciences than the validity of the construct. /x
• • •
Missing some Tweet in this thread? You can try to
force a refresh