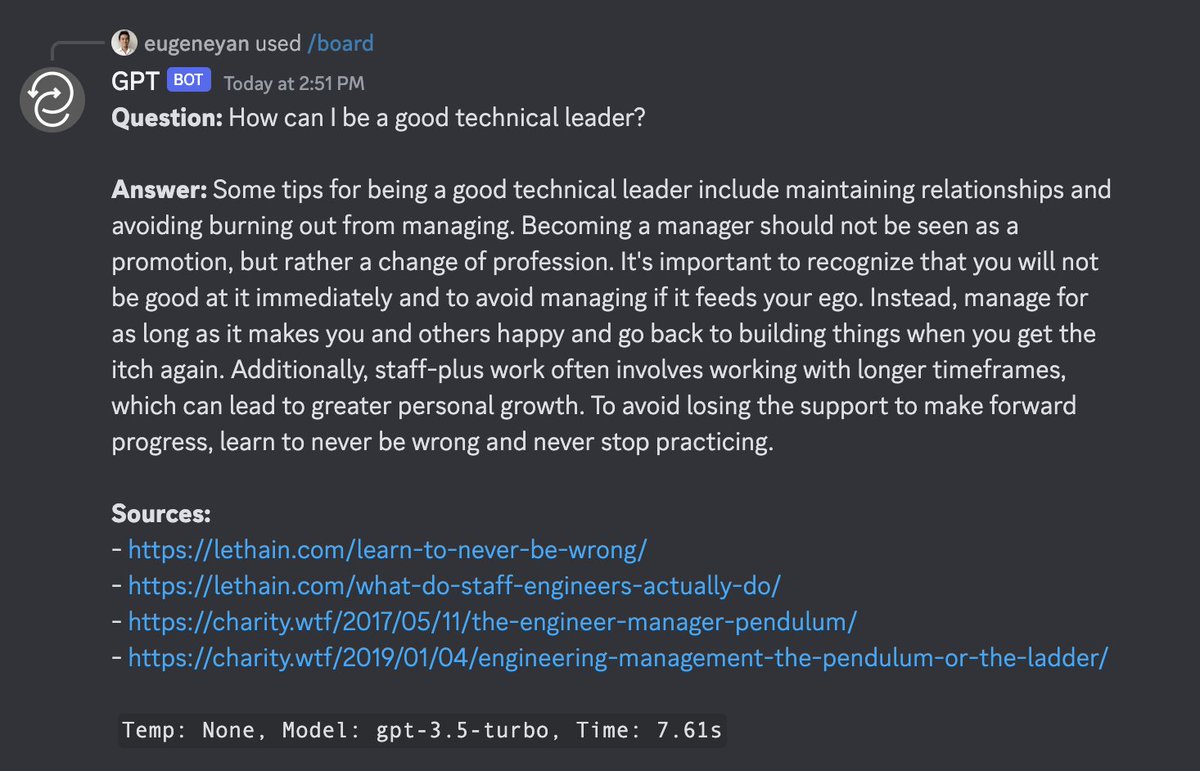
Tenets from Duolingo's push to be AI-first
• AI will be everywhere in our product
• Start with AI for every task
• Spend 10% of your time learning
• Share what you learn
• Avoid overbuilding
• Build and experiment carefully
• Technical excellence still matters
• AI will be everywhere in our product
• Start with AI for every task
• Spend 10% of your time learning
• Share what you learn
• Avoid overbuilding
• Build and experiment carefully
• Technical excellence still matters

Shopify had a similar push earlier this month
https://x.com/eugeneyan/status/1909444357058707960
I adopt similar tenets at work, and folks who're hungry to learn & apply have seen gains of 2-20x.
Similar trends in the past include:
• Proprietary (sas/spss)->oss/python
• Adopting spark
• Machine learning, then deep learning
AI-first is another shift; don't overlook it.
Similar trends in the past include:
• Proprietary (sas/spss)->oss/python
• Adopting spark
• Machine learning, then deep learning
AI-first is another shift; don't overlook it.
• • •
Missing some Tweet in this thread? You can try to
force a refresh