
Field ⇔ Frontier @AnthropicAI. Prev: Principal Applied Scientist @ Amazon, led ML @ Alibaba, Healthtech.





 Here's a GitHub gist if you want to try it yourself: gist.github.com/eugeneyan/1d2e…
Here's a GitHub gist if you want to try it yourself: gist.github.com/eugeneyan/1d2e… Yea, there were one-click deploys, rollbacks, A/B tests—you name it.
Yea, there were one-click deploys, rollbacks, A/B tests—you name it.
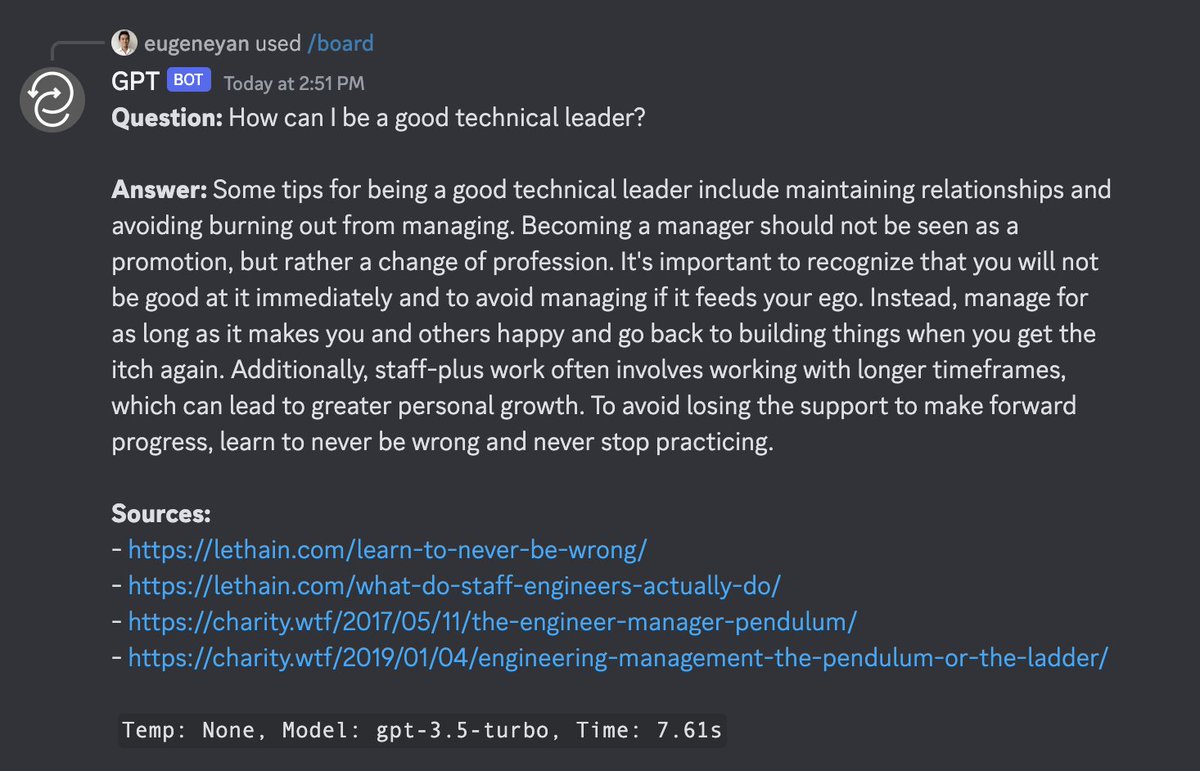


 `/ask-ey` does something similar for my own site, eugeneyan.com. And because I'm more familiar with my own writing, I can better spot shortfalls such as not answering based on a source when expected, or when a source is irrelevant.
`/ask-ey` does something similar for my own site, eugeneyan.com. And because I'm more familiar with my own writing, I can better spot shortfalls such as not answering based on a source when expected, or when a source is irrelevant. 



 Correction: I guess all we can say is that it now (only) uses the actual memory required instead of 2x memory required.
Correction: I guess all we can say is that it now (only) uses the actual memory required instead of 2x memory required.


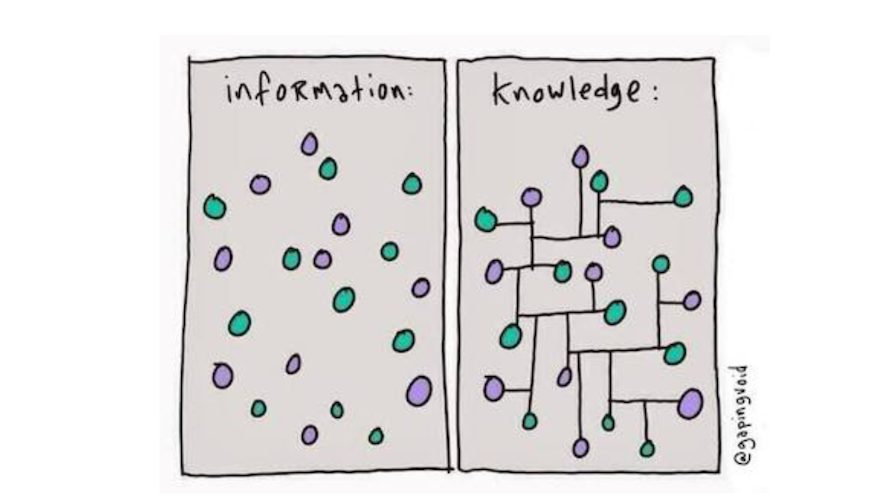 (1/4) Here's how a Zettelkasten works:
(1/4) Here's how a Zettelkasten works: