It is critical for scientific integrity that we trust our measure of progress.
The @lmarena_ai has become the go-to evaluation for AI progress.
Our release today demonstrates the difficulty in maintaining fair evaluations on @lmarena_ai, despite best intentions.
The @lmarena_ai has become the go-to evaluation for AI progress.
Our release today demonstrates the difficulty in maintaining fair evaluations on @lmarena_ai, despite best intentions.

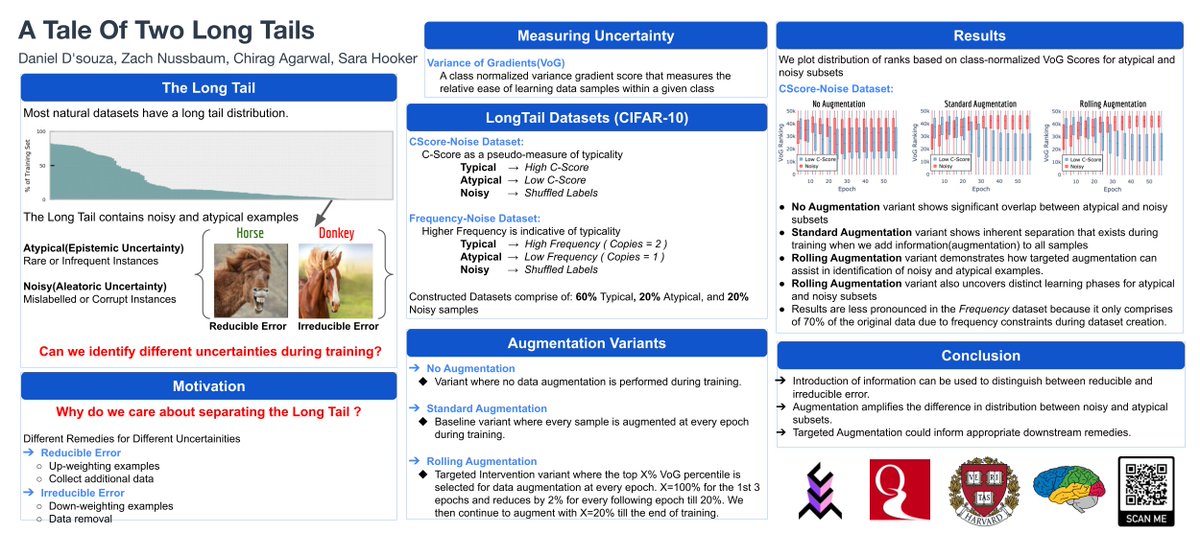
We spent 5 months analyzing 2.8M battles on the Arena, covering 238 models across 43 providers.
We show that preferential policies engaged in by a handful of providers lead to overfitting to Arena-specific metrics rather than genuine AI progress.
We show that preferential policies engaged in by a handful of providers lead to overfitting to Arena-specific metrics rather than genuine AI progress.

@lmarena_ai unspoken policy of hidden testing that benefits a small subset of providers.
Providers can choose what score to disclose and retract all others.
At an extreme, we see testing of up to 27 models in lead up to releases.
Providers can choose what score to disclose and retract all others.
At an extreme, we see testing of up to 27 models in lead up to releases.
There is no reasonable scientific justification for this practice.
Being able to choose the best score to disclose enables systematic gaming of Arena score.
This advantage increases with number of variants and if all other providers don’t know they can also private test..
Being able to choose the best score to disclose enables systematic gaming of Arena score.
This advantage increases with number of variants and if all other providers don’t know they can also private test..

This has to be very explicit -- continuing with current practice of:
1) only some providers are allowed unlimited tests,
2) allowed to retract scores
amounts to our community accepting a practice which we learn in our intro to ML classes is unacceptable.
We must do better.
1) only some providers are allowed unlimited tests,
2) allowed to retract scores
amounts to our community accepting a practice which we learn in our intro to ML classes is unacceptable.
We must do better.

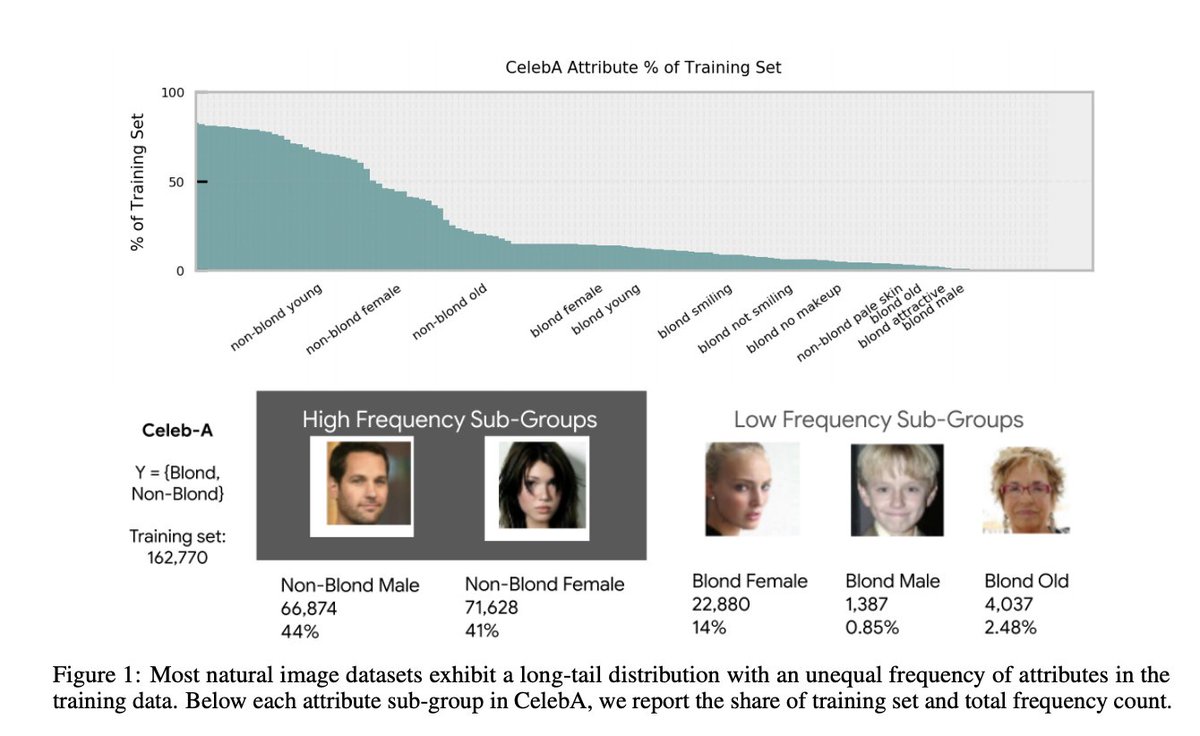
We also observe large differences in Arena Data Access
@lmarena_ai is a open community resource that provides free feedback but 61.3% of all data goes to proprietary model providers.
@lmarena_ai is a open community resource that provides free feedback but 61.3% of all data goes to proprietary model providers.
@lmarena_ai These data differences stem from some key policies that benefit a handful of providers:
1) proprietary models sampled at higher rates to appear in battles 📶
2) open-weights + open-source models removed from Arena more often
3) How many private variants
1) proprietary models sampled at higher rates to appear in battles 📶
2) open-weights + open-source models removed from Arena more often
3) How many private variants
@lmarena_ai The differences in sampling rates are actually what started this project.
Aya Expanse is an open-weights model we released last year, and we couldn't figure out last November why it was sampled far less than other models.
Aya Expanse is an open-weights model we released last year, and we couldn't figure out last November why it was sampled far less than other models.

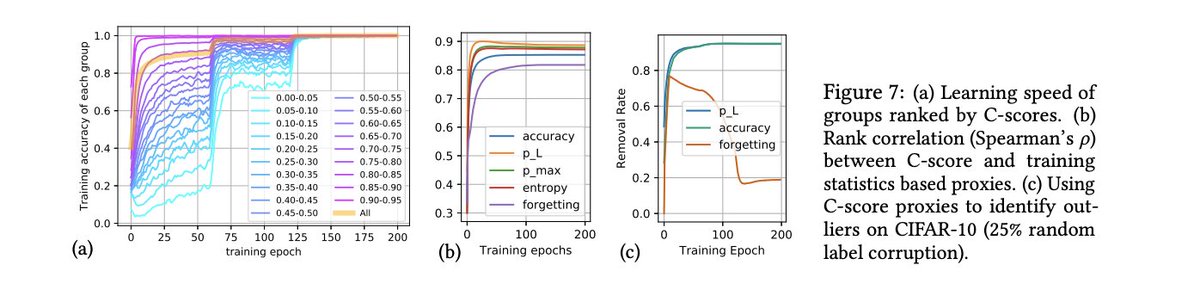
@lmarena_ai Our recommendation here is simple.
The organizers themselves proposed a very well motivated active sampling rate that returns the Arena to sampling votes where they are needed.
We found this was not implemented in practice. One of our core recommendations is to return to it.
The organizers themselves proposed a very well motivated active sampling rate that returns the Arena to sampling votes where they are needed.
We found this was not implemented in practice. One of our core recommendations is to return to it.

Overall, our work suggests that engagement from a handful of providers and preferential policies from @lmarena_ai towards the same small group have created conditions to overfit to Arena-specific dynamics rather than general model quality.
I remain optimistic this can be fixed.
I remain optimistic this can be fixed.

This was an uncomfortable paper to work on because it asks us to look in the mirror as a community.
As scientists, we must do better.
As a community, I hope we can demand better.
As scientists, we must do better.
As a community, I hope we can demand better.
I also do not want to detract from everything @lmarena_ai has achieved. They have democratized access to models, empowered an open community.
I believe the organizers can continue to restore trust by revising their policies.
We make very clear the five changes needed.
I believe the organizers can continue to restore trust by revising their policies.
We make very clear the five changes needed.

Very proud of this cross-institutional collaboration @Cohere_Labs @UWaterloo @stai_research @PrincetonCITP @uwnlp @MIT
Led by @singhshiviii @mziizm, with @YiyangNan @W4ngatang @mrdanieldsouza @sayashk @ahmetustun89 @sanmikoyejo @yuntiandeng @ShayneRedford @nlpnoah @beyzaermis
Led by @singhshiviii @mziizm, with @YiyangNan @W4ngatang @mrdanieldsouza @sayashk @ahmetustun89 @sanmikoyejo @yuntiandeng @ShayneRedford @nlpnoah @beyzaermis

• • •
Missing some Tweet in this thread? You can try to
force a refresh