Releasing INTELLECT-2: We’re open-sourcing the first 32B parameter model trained via globally distributed reinforcement learning:
• Detailed Technical Report
• INTELLECT-2 model checkpoint
primeintellect.ai/blog/intellect…
• Detailed Technical Report
• INTELLECT-2 model checkpoint
primeintellect.ai/blog/intellect…
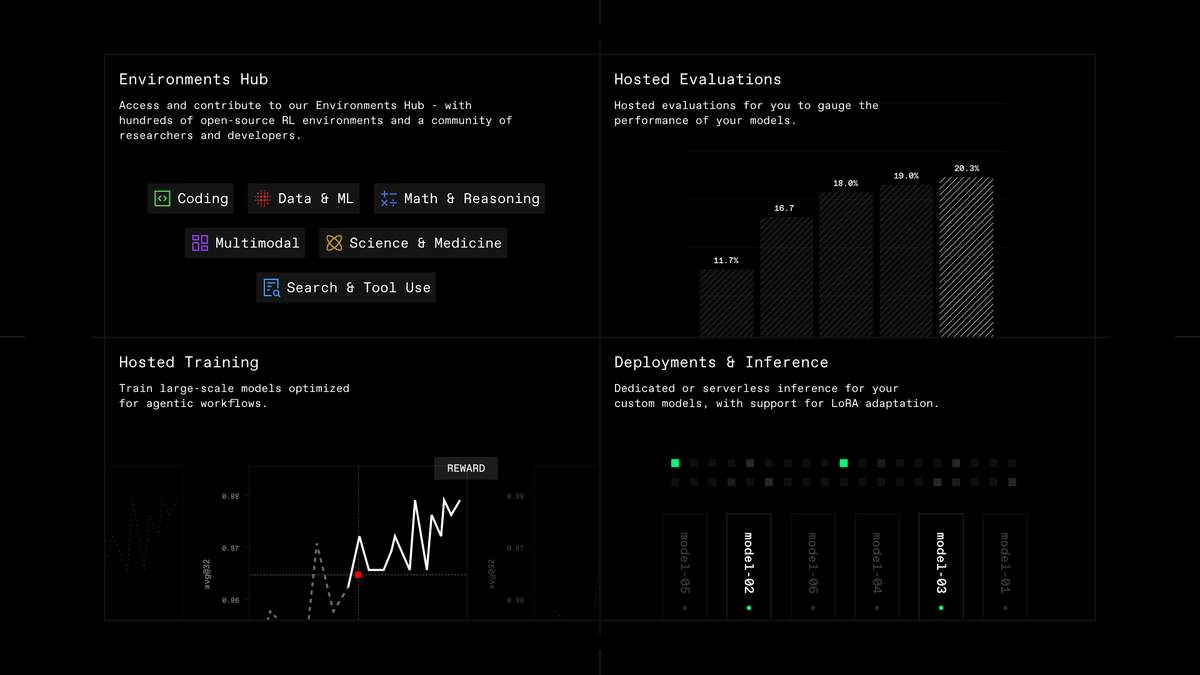
To train a model with reinforcement learning in a fully decentralized setting using community-contributed GPUs, we open-source several novel infrastructure components. 

PRIME-RL: A fully asynchronous reinforcement learning framework designed for decentralized training. Decoupling of rollout generation, model training, and weight broadcasting enables training across heterogeneous, unreliable networks.
SHARDCAST: A library for distributing large files via a HTTP-based tree-topology network that efficiently propagates updated model weights from training nodes to the decentralized inference workers.

TOPLOC Validators: A validator service using TOPLOC proofs to ensure that rollouts from untrusted inference workers can be trusted for model training.

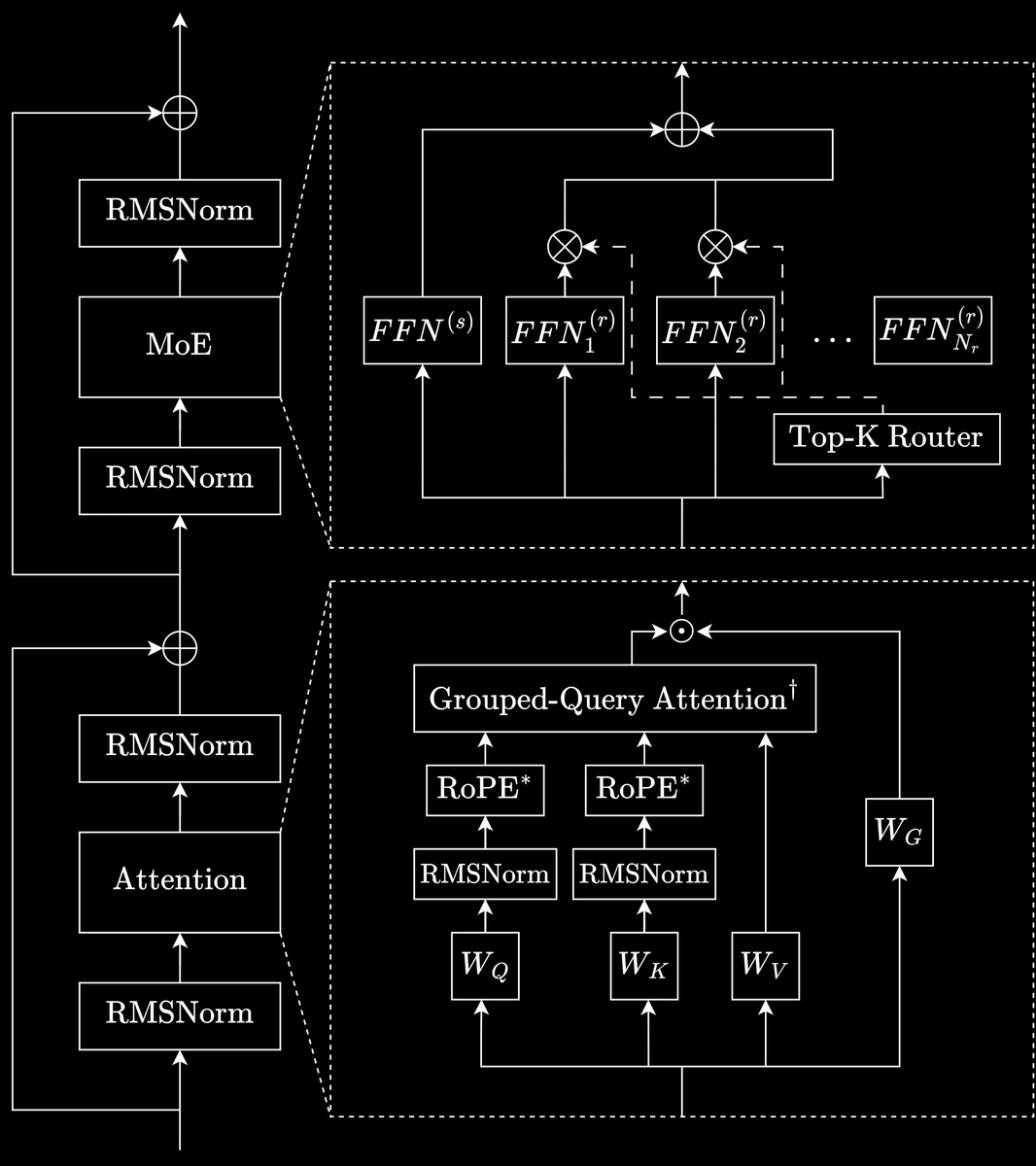
INTELLECT-2 is trained using rule-based rewards across math and coding problems and length rewards guiding the model to follow its thinking budget. We introduce modifications to the standard GRPO recipe to enhance training stability and encourage faster learning.
Two-step asynchronous RL: The broadcast of new policy weights is fully overlapped with ongoing inference and training, eliminating communication bottlenecks.
Two-step asynchronous RL: The broadcast of new policy weights is fully overlapped with ongoing inference and training, eliminating communication bottlenecks.

Two-Sided GRPO Clipping: Stabilizes training by mitigating gradient spikes with two-sided token probability ratio clipping.

Advanced Data Filtering: Combines offline and online filtering to select challenging tasks, significantly enhancing model learning efficiency.
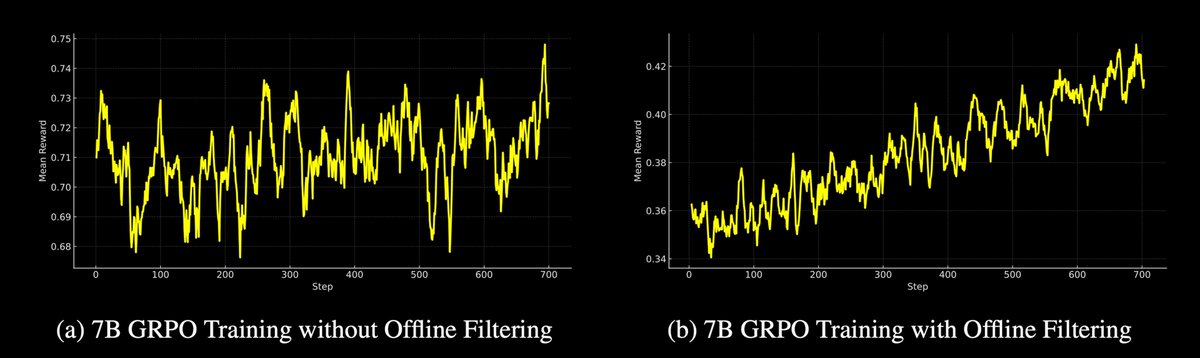
Experiments:
We report results from two main experiments: TARGET-SHORT, an experimental run with short target lengths to train an efficient reasoning model, and, TARGET-LONG, our main run with longer target lengths.
Reward Trajectories:
We report results from two main experiments: TARGET-SHORT, an experimental run with short target lengths to train an efficient reasoning model, and, TARGET-LONG, our main run with longer target lengths.
Reward Trajectories:

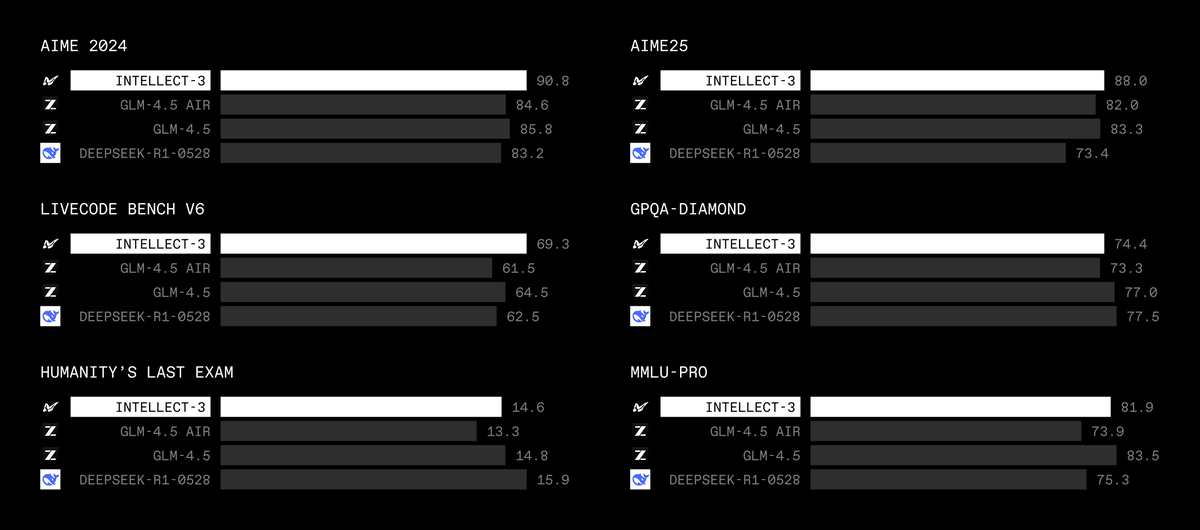
Benchmark Performance:
We were able to increase the performance of QwQ-32B on math and coding benchmarks. Since QwQ-32B is already very strong and heavily trained using RL, huge additional improvements will likely require better base models or higher quality data.
We were able to increase the performance of QwQ-32B on math and coding benchmarks. Since QwQ-32B is already very strong and heavily trained using RL, huge additional improvements will likely require better base models or higher quality data.

INTELLECT-2 demonstrates that globally decentralized RL works.
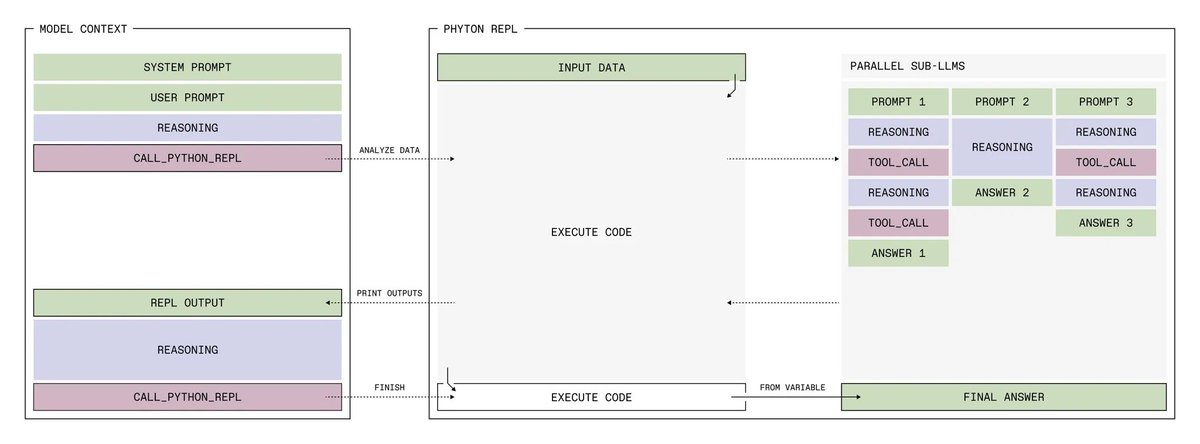
Now, we’re focusing on tool-assisted reasoning, crowdsourcing higher-quality data, and optimizing our infrastructure and training recipe to build frontier open models.
Join us to build open source and decentralized AGI.
Now, we’re focusing on tool-assisted reasoning, crowdsourcing higher-quality data, and optimizing our infrastructure and training recipe to build frontier open models.
Join us to build open source and decentralized AGI.
Links
• Detailed Technical Report: primeintellect.ai/intellect-2
• INTELLECT-2 on Hugging Face: huggingface.co/collections/Pr…
• Chat Interface to try it out: chat.primeintellect.ai
• Blog: primeintellect.ai/blog/intellect…
• Detailed Technical Report: primeintellect.ai/intellect-2
• INTELLECT-2 on Hugging Face: huggingface.co/collections/Pr…
• Chat Interface to try it out: chat.primeintellect.ai
• Blog: primeintellect.ai/blog/intellect…
• • •
Missing some Tweet in this thread? You can try to
force a refresh