If you're an engineer who's feeling hesitant or overwhelmed by the innovation pace of AI coding, this thread is for you.
Here's the 10% of fundamentals that will put you in the 90th percentile of AI engineers.
🧵/many
Here's the 10% of fundamentals that will put you in the 90th percentile of AI engineers.
🧵/many
First, a crucial mindset shift: stop treating AI like a vending machine for code. Effective AI Engineering is IDE-native collaboration. It's a strategic partnership blending your insight with AI's capabilities.
Think of AI as a highly skilled (but forgetful) pair programmer.
Think of AI as a highly skilled (but forgetful) pair programmer.
The single biggest lever for better AI-generated code? Planning before AI writes any code. Frontload all relevant context -- files, existing patterns, overall goals. Then, collaboratively develop a strategy with your AI.
(this is why Cline has Plan/Act modes)
(this is why Cline has Plan/Act modes)

Why does planning work so well?
It ensures a shared understanding, so AI truly grasps what you're trying to achieve and its constraints.
It ensures a shared understanding, so AI truly grasps what you're trying to achieve and its constraints.
This drastically improves accuracy and leads to more relevant code, massively reducing rework by catching misunderstandings early.
Invest time here; save 10x downstream.
Invest time here; save 10x downstream.
Next up, you need to master the AI's "context window." This is its short-term memory, holding your instructions, code, chat history, etc.
It's finite. When it gets too full (often >50% for many models), AI performance can dip. It might start to "forget" earlier parts of your discussion.
It's finite. When it gets too full (often >50% for many models), AI performance can dip. It might start to "forget" earlier parts of your discussion.
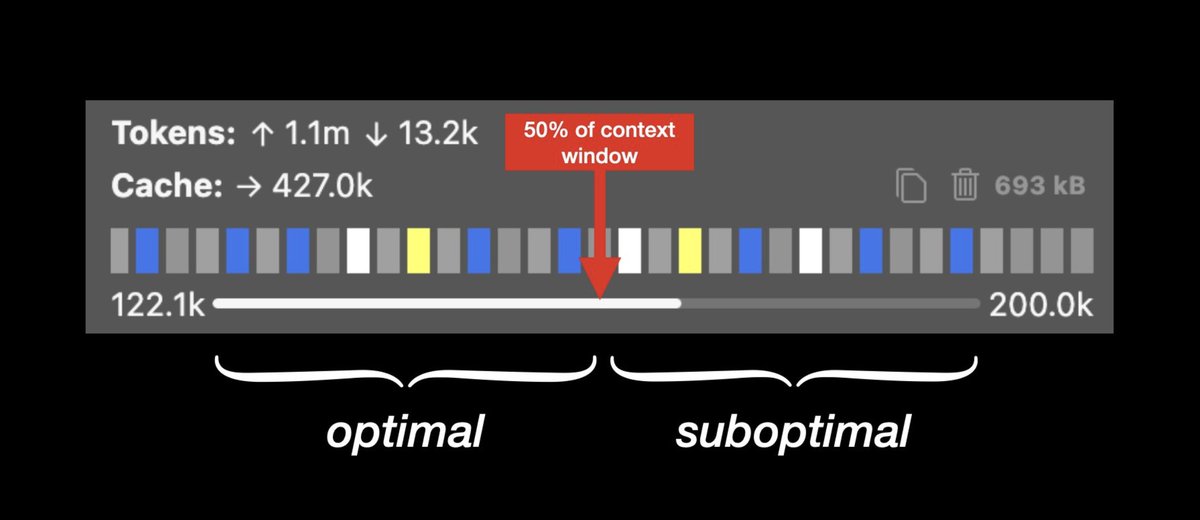
Proactive context management is key to avoiding this.
Be aware of how full the window is. For long chats, use techniques to summarize the history (/newtask).
Be aware of how full the window is. For long chats, use techniques to summarize the history (/newtask).
For extended tasks, break them down (/smol). Start "new tasks" or sessions, carrying over only essential, summarized context to keep the AI focused.
When it comes to choosing an AI model, simplify your approach by prioritizing models with strong reasoning, instruction following, and coding capabilities.
Top-tier models like Gemini 2.5 Pro or Claude 3.7 Sonnet are excellent starting points. Though expensive compared to less-performant models, most developers find the ROI worth it.
Don't skimp on model quality here.
Don't skimp on model quality here.

While cheaper or smaller models can be fine for simple, isolated tasks, for intricate, multi-step AI engineering that relies on reliable tool use, investing in a more capable model usually pays off significantly in speed, quality, and reduced frustration.
Now, let's talk about giving your AI guidance so you stop re-explaining the same things every session. Use "Rules Files" -- essentially custom instructions -- to persistently guide AI behavior.
Here are some of our favorites: github.com/cline/prompts
Here are some of our favorites: github.com/cline/prompts
These can enforce your coding standards, define project context like tech stack or architecture, or automate common workflows.
Complement Rules Files with "Memory Banks." This is a pattern of creating structured project documentation (e.g., in a `memory-bank/` folder with files like `project_brief.md`, `tech_context.md`) that your AI reads at the start of sessions.
docs.cline.bot/improving-your…
docs.cline.bot/improving-your…
This allows the AI to "remember" critical project details, patterns, and decisions over time.
The payoff for implementing these "memory" systems is huge:
You get consistent AI behavior aligned with your project, a reduced need for repetitive explanations, and faster onboarding for new team members.
It’s a scalable way to manage knowledge as projects grow.
You get consistent AI behavior aligned with your project, a reduced need for repetitive explanations, and faster onboarding for new team members.
It’s a scalable way to manage knowledge as projects grow.
So, to recap the fundamentals that deliver outsized impact in AI engineering:
1. Collaborate strategically with your AI; don't just prompt.
2. Always plan WITH your AI before it codes.
3. Proactively manage the AI's context window.
4. Use capable models for complex, agentic work.
5. Give your AI persistent knowledge through Rules Files & Memory Banks.
2. Always plan WITH your AI before it codes.
3. Proactively manage the AI's context window.
4. Use capable models for complex, agentic work.
5. Give your AI persistent knowledge through Rules Files & Memory Banks.
Focus on these fundamentals, and you'll be understand the 10% of what matters in AI coding.
The goal is to build better software, faster.
The goal is to build better software, faster.
• • •
Missing some Tweet in this thread? You can try to
force a refresh